 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGravitational Models Explain Shifts on Human Visual Attention
Sep 15, 2020
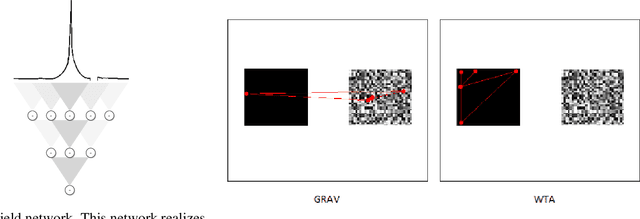
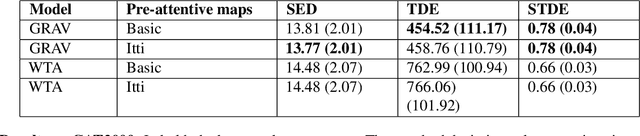

Visual attention refers to the human brain's ability to select relevant sensory information for preferential processing, improving performance in visual and cognitive tasks. It proceeds in two phases. One in which visual feature maps are acquired and processed in parallel. Another where the information from these maps is merged in order to select a single location to be attended for further and more complex computations and reasoning. Its computational description is challenging, especially if the temporal dynamics of the process are taken into account. Numerous methods to estimate saliency have been proposed in the last three decades. They achieve almost perfect performance in estimating saliency at the pixel level, but the way they generate shifts in visual attention fully depends on winner-take-all (WTA) circuitry. WTA is implemented} by the biological hardware in order to select a location with maximum saliency, towards which to direct overt attention. In this paper we propose a gravitational model (GRAV) to describe the attentional shifts. Every single feature acts as an attractor and {the shifts are the result of the joint effects of the attractors. In the current framework, the assumption of a single, centralized saliency map is no longer necessary, though still plausible. Quantitative results on two large image datasets show that this model predicts shifts more accurately than winner-take-all.
End-to-End Models for the Analysis of Pupil Size Variations and Diagnosis of Parkinson's Disease
Feb 06, 2020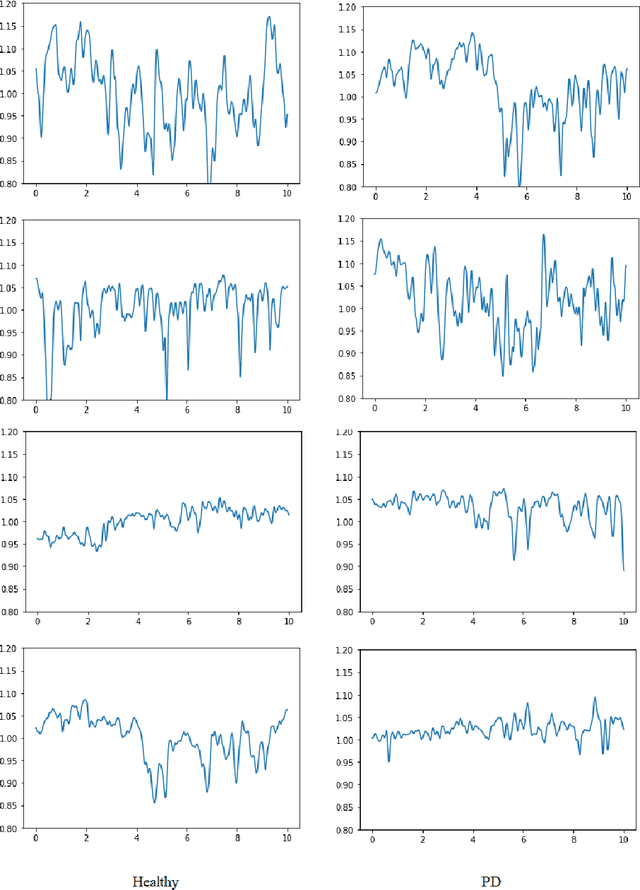
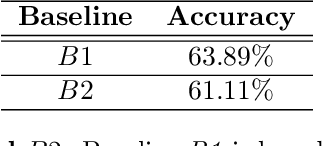
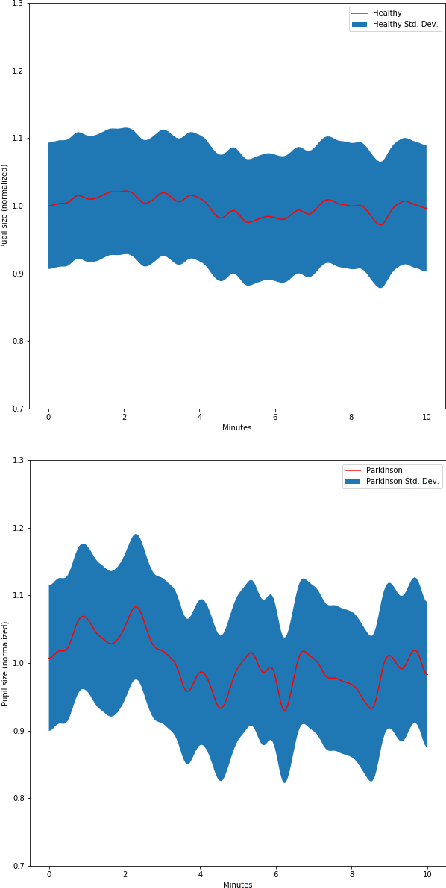
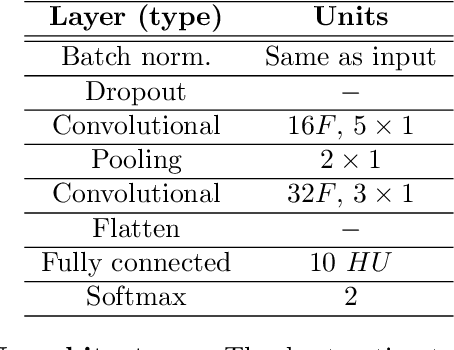
It is well known that a systematic analysis of the pupil size variations, recorded by means of an eye-tracker, is a rich source of information about a subject's cognitive state. In this work we present end-to-end models for the diagnosis of Parkinson's disease (PD) based on the raw pupil size signal. Long-range registration (10 minutes) of the pupil size were collected in scotopic conditions (complete darkness, 0 lux) on 21 healthy subjects and 15 subjects diagnosed with PD. 1-D convolutional neural network models are trained for classification of short-range sequences (10 to 60 seconds of registration). The model provides prediction with high average accuracy on a hold out test set. A temporal analysis of the model performance allowed the characterization of pupil's size variations in PD and healthy subjects during a resting state. Dataset and codes are released for reproducibility and benchmarking purposes.
FixaTons: A collection of Human Fixations Datasets and Metrics for Scanpath Similarity
Oct 03, 2018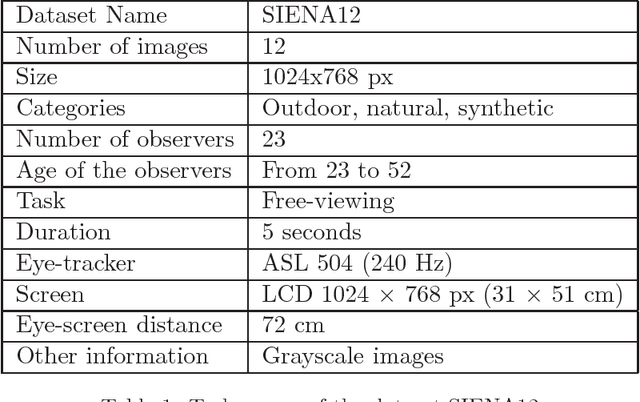


In the last three decades, human visual attention has been a topic of great interest in various disciplines. In computer vision, many models have been proposed to predict the distribution of human fixations on a visual stimulus. Recently, thanks to the creation of large collections of data, machine learning algorithms have obtained state-of-the-art performance on the task of saliency map estimation. On the other hand, computational models of scanpath are much less studied. Works are often only descriptive or task specific. This is due to the fact that the scanpath is harder to model because it must include the description of a dynamic. General purpose computational models are present in the literature, but are then evaluated in tasks of saliency prediction, losing therefore information about the dynamics and the behaviour. In addition, two technical reasons have limited the research. The first reason is the lack of robust and uniformly used set of metrics to compare the similarity between scanpath. The second reason is the lack of sufficiently large and varied scanpath datasets. In this report we want to help in both directions. We present FixaTons, a large collection of datasets human scanpaths (temporally ordered sequences of fixations) and saliency maps. It comes along with a software library for easy data usage, statistics calculation and implementation of metrics for scanpath and saliency prediction evaluation.