 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Meaningful Explanations
Sep 11, 2018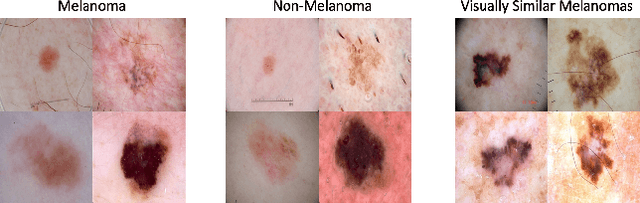
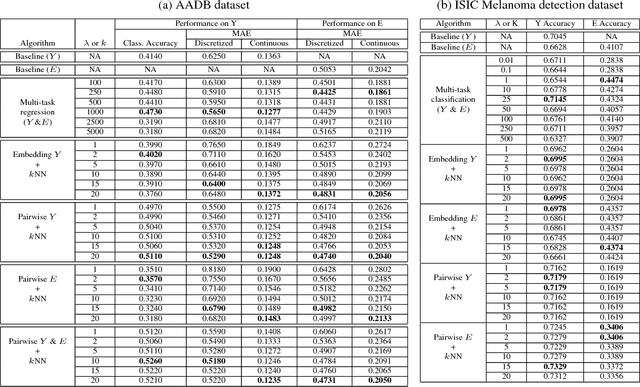
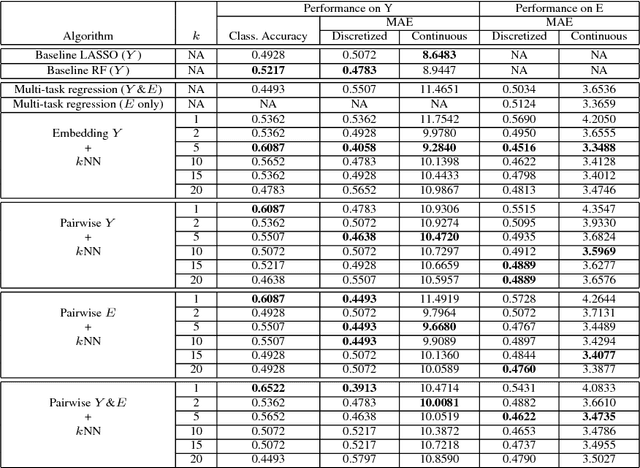
The adoption of machine learning in high-stakes applications such as healthcare and law has lagged in part because predictions are not accompanied by explanations comprehensible to the domain user, who often holds the ultimate responsibility for decisions and outcomes. In this paper, we propose an approach to generate such explanations in which training data is augmented to include, in addition to features and labels, explanations elicited from domain users. A joint model is then learned to produce both labels and explanations from the input features. This simple idea ensures that explanations are tailored to the complexity expectations and domain knowledge of the consumer. Evaluation spans multiple modeling techniques on a game dataset, a (visual) aesthetics dataset, a chemical odor dataset and a Melanoma dataset showing that our approach is generalizable across domains and algorithms. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, also improve modeling accuracy.
Increasing Trust in AI Services through Supplier's Declarations of Conformity
Aug 22, 2018The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers' trust in a service. In this paper, we propose a supplier's declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.
Teaching machines to understand data science code by semantic enrichment of dataflow graphs
Jul 16, 2018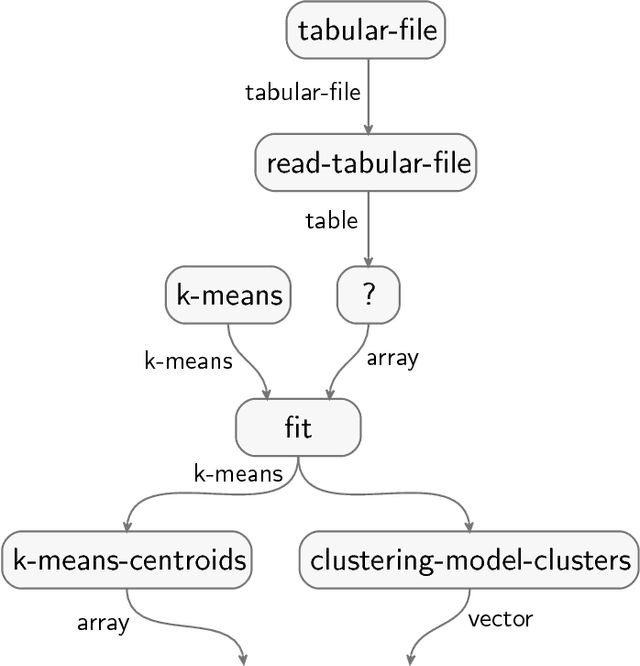

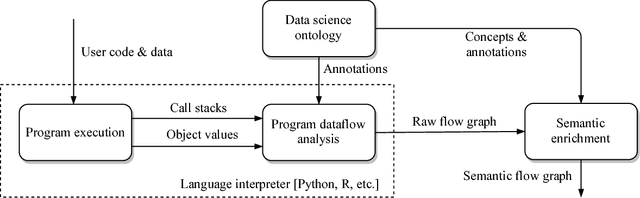
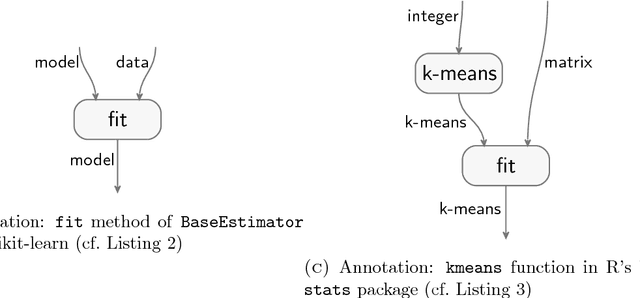
Your computer is continuously executing programs, but does it really understand them? Not in any meaningful sense. That burden falls upon human knowledge workers, who are increasingly asked to write and understand code. They would benefit greatly from intelligent tools that reveal the connections between their code and its subject matter. Towards this prospect, we develop an AI system that forms semantic representations of computer programs, using techniques from knowledge representation and program analysis. We focus on code written for data science, although our method is more generally applicable. The semantic representations are created through a novel algorithm for the semantic enrichment of dataflow graphs. This algorithm is undergirded by a new ontology language for modeling computer programs and a new ontology about data science, written in this language.