 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Augmented Learnable Algorithms for Resource Management in Wireless Networks
Jul 05, 2022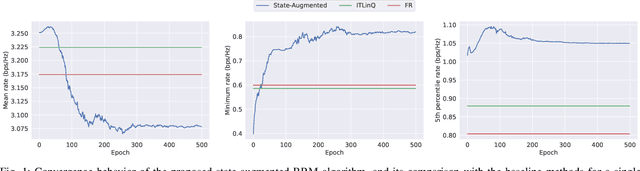
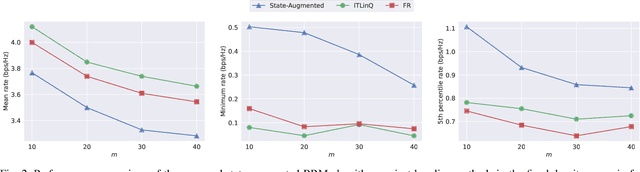
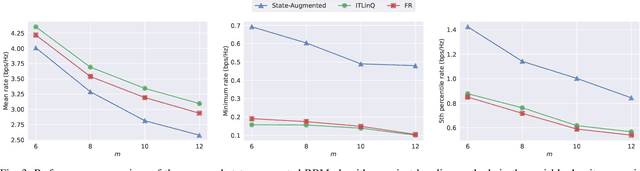
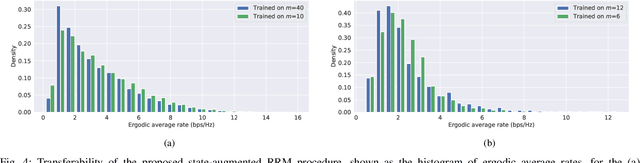
We consider resource management problems in multi-user wireless networks, which can be cast as optimizing a network-wide utility function, subject to constraints on the long-term average performance of users across the network. We propose a state-augmented algorithm for solving the aforementioned radio resource management (RRM) problems, where, alongside the instantaneous network state, the RRM policy takes as input the set of dual variables corresponding to the constraints, which evolve depending on how much the constraints are violated during execution. We theoretically show that the proposed state-augmented algorithm leads to feasible and near-optimal RRM decisions. Moreover, focusing on the problem of wireless power control using graph neural network (GNN) parameterizations, we demonstrate the superiority of the proposed RRM algorithm over baseline methods across a suite of numerical experiments.
Self-Consistency of the Fokker-Planck Equation
Jun 02, 2022

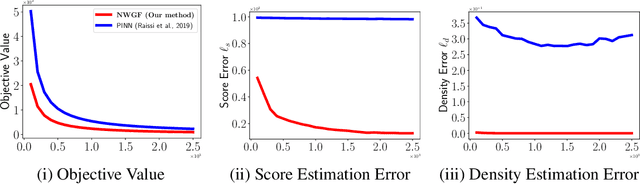
The Fokker-Planck equation (FPE) is the partial differential equation that governs the density evolution of the It\^o process and is of great importance to the literature of statistical physics and machine learning. The FPE can be regarded as a continuity equation where the change of the density is completely determined by a time varying velocity field. Importantly, this velocity field also depends on the current density function. As a result, the ground-truth velocity field can be shown to be the solution of a fixed-point equation, a property that we call self-consistency. In this paper, we exploit this concept to design a potential function of the hypothesis velocity fields, and prove that, if such a function diminishes to zero during the training procedure, the trajectory of the densities generated by the hypothesis velocity fields converges to the solution of the FPE in the Wasserstein-2 sense. The proposed potential function is amenable to neural-network based parameterization as the stochastic gradient with respect to the parameter can be efficiently computed. Once a parameterized model, such as Neural Ordinary Differential Equation is trained, we can generate the entire trajectory to the FPE.
coVariance Neural Networks
May 31, 2022



Graph neural networks (GNN) are an effective framework that exploit inter-relationships within graph-structured data for learning. Principal component analysis (PCA) involves the projection of data on the eigenspace of the covariance matrix and draws similarities with the graph convolutional filters in GNNs. Motivated by this observation, we propose a GNN architecture, called coVariance neural network (VNN), that operates on sample covariance matrices as graphs. We theoretically establish the stability of VNNs to perturbations in the covariance matrix, thus, implying an advantage over standard PCA-based data analysis approaches that are prone to instability due to principal components associated with close eigenvalues. Our experiments on real-world datasets validate our theoretical results and show that VNN performance is indeed more stable than PCA-based statistical approaches. Moreover, our experiments on multi-resolution datasets also demonstrate that VNNs are amenable to transferability of performance over covariance matrices of different dimensions; a feature that is infeasible for PCA-based approaches.
Graph Neural Networks Are More Powerful Than we Think
May 19, 2022
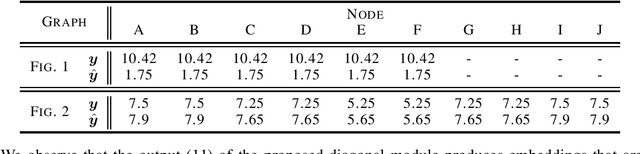
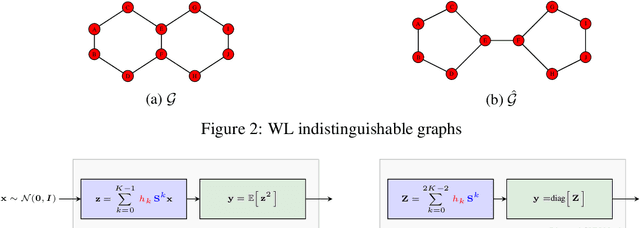

Graph Neural Networks (GNNs) are powerful convolutional architectures that have shown remarkable performance in various node-level and graph-level tasks. Despite their success, the common belief is that the expressive power of GNNs is limited and that they are at most as discriminative as the Weisfeiler-Lehman (WL) algorithm. In this paper we argue the opposite and show that the WL algorithm is the upper bound only when the input to the GNN is the vector of all ones. In this direction, we derive an alternative analysis that employs linear algebraic tools and characterize the representational power of GNNs with respect to the eigenvalue decomposition of the graph operators. We show that GNNs can distinguish between any graphs that differ in at least one eigenvalue and design simple GNN architectures that are provably more expressive than the WL algorithm. Thorough experimental analysis on graph isomorphism and graph classification datasets corroborates our theoretical results and demonstrates the effectiveness of the proposed architectures.
Learning Graph Structure from Convolutional Mixtures
May 19, 2022

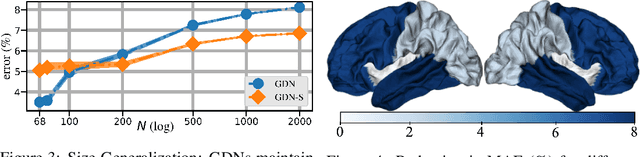

Machine learning frameworks such as graph neural networks typically rely on a given, fixed graph to exploit relational inductive biases and thus effectively learn from network data. However, when said graphs are (partially) unobserved, noisy, or dynamic, the problem of inferring graph structure from data becomes relevant. In this paper, we postulate a graph convolutional relationship between the observed and latent graphs, and formulate the graph learning task as a network inverse (deconvolution) problem. In lieu of eigendecomposition-based spectral methods or iterative optimization solutions, we unroll and truncate proximal gradient iterations to arrive at a parameterized neural network architecture that we call a Graph Deconvolution Network (GDN). GDNs can learn a distribution of graphs in a supervised fashion, perform link prediction or edge-weight regression tasks by adapting the loss function, and they are inherently inductive. We corroborate GDN's superior graph recovery performance and its generalization to larger graphs using synthetic data in supervised settings. Furthermore, we demonstrate the robustness and representation power of GDNs on real world neuroimaging and social network datasets.
Learning Resilient Radio Resource Management Policies with Graph Neural Networks
Mar 07, 2022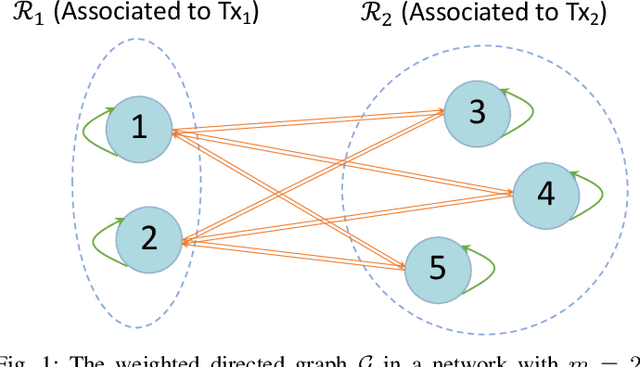
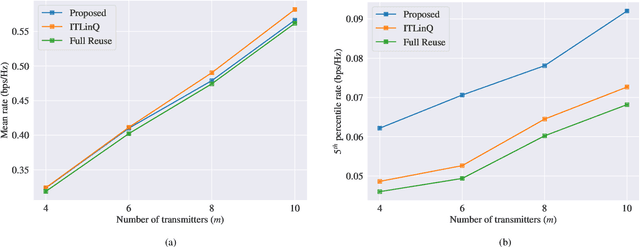
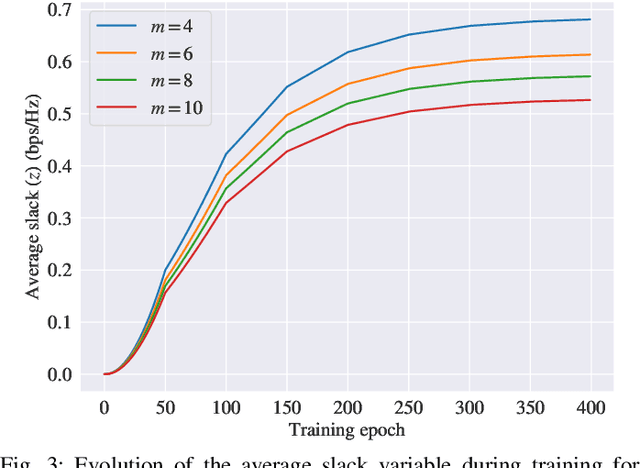
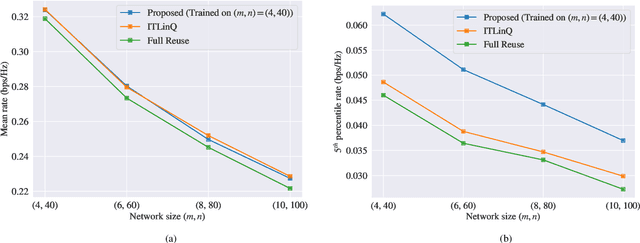
We consider the problems of downlink user selection and power control in wireless networks, comprising multiple transmitters and receivers communicating with each other over a shared wireless medium. To achieve a high aggregate rate, while ensuring fairness across all the receivers, we formulate a resilient radio resource management (RRM) policy optimization problem with per-user minimum-capacity constraints that adapt to the underlying network conditions via learnable slack variables. We reformulate the problem in the Lagrangian dual domain, and show that we can parameterize the user selection and power control policies using a finite set of parameters, which can be trained alongside the slack and dual variables via an unsupervised primal-dual approach thanks to a provably small duality gap. We use a scalable and permutation-equivariant graph neural network (GNN) architecture to parameterize the RRM policies based on a graph topology derived from the instantaneous channel conditions. Through experimental results, we verify that the minimum-capacity constraints adapt to the underlying network configurations and channel conditions. We further demonstrate that, thanks to such adaptation, our proposed method achieves a superior tradeoff between the average rate and the 5th percentile rate -- a metric that quantifies the level of fairness in the resource allocation decisions -- as compared to baseline algorithms.
A Lagrangian Duality Approach to Active Learning
Feb 08, 2022
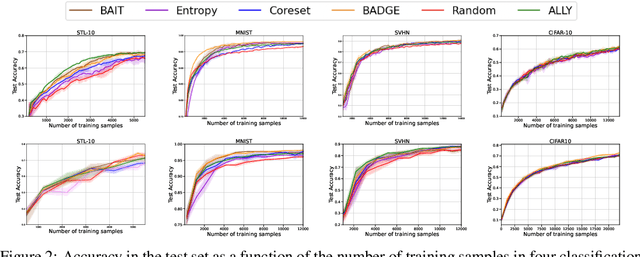
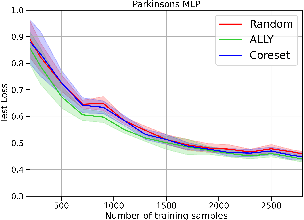
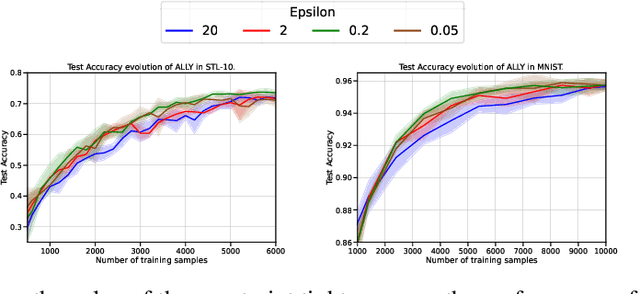
We consider the batch active learning problem, where only a subset of the training data is labeled, and the goal is to query a batch of unlabeled samples to be labeled so as to maximally improve model performance. We formulate the learning problem using constrained optimization, where each constraint bounds the performance of the model on labeled samples. Considering a primal-dual approach, we optimize the primal variables, corresponding to the model parameters, as well as the dual variables, corresponding to the constraints. As each dual variable indicates how significantly the perturbation of the respective constraint affects the optimal value of the objective function, we use it as a proxy of the informativeness of the corresponding training sample. Our approach, which we refer to as Active Learning via Lagrangian dualitY, or ALLY, leverages this fact to select a diverse set of unlabeled samples with the highest estimated dual variables as our query set. We show, via numerical experiments, that our proposed approach performs similarly to or better than state-of-the-art active learning methods in a variety of classification and regression tasks. We also demonstrate how ALLY can be used in a generative mode to create novel, maximally-informative samples. The implementation code for ALLY can be found at https://github.com/juanelenter/ALLY.
Graph Reinforcement Learning for Wireless Control Systems: Large-Scale Resource Allocation over Interference Channels
Jan 24, 2022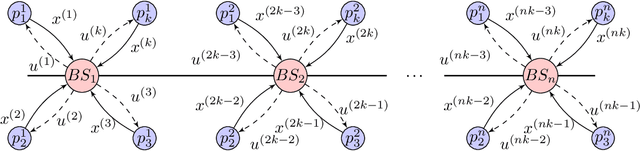
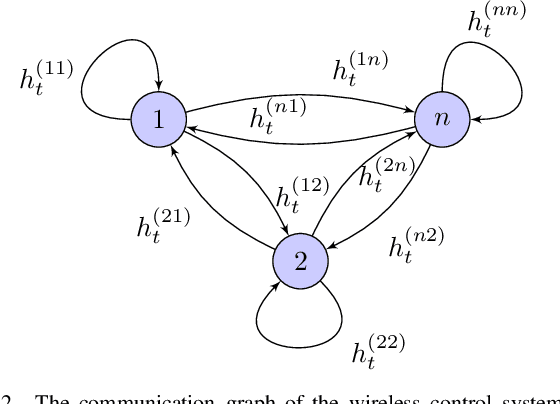
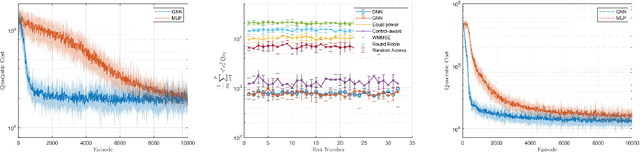
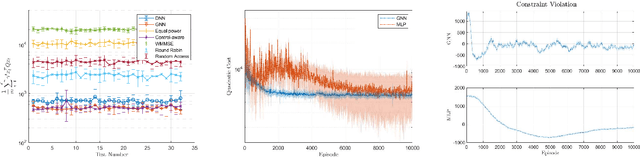
Modern control systems routinely employ wireless networks to exchange information between spatially distributed plants, actuators and sensors. With wireless networks defined by random, rapidly changing transmission conditions that challenge assumptions commonly held in the design of control systems, proper allocation of communication resources is essential to achieve reliable operation. Designing resource allocation policies, however, is challenging, motivating recent works to successfully exploit deep learning and deep reinforcement learning techniques to design resource allocation and scheduling policies for wireless control systems. As the number of learnable parameters in a neural network grows with the size of the input signal, deep reinforcement learning algorithms may fail to scale, limiting the immediate generalization of such scheduling and resource allocation policies to large-scale systems. The interference and fading patterns among plants and controllers in the network, on the other hand, induce a time-varying communication graph that can be used to construct policy representations based on graph neural networks (GNNs), with the number of learnable parameters now independent of the number of plants in the network. That invariance to the number of nodes is key to design scalable and transferable resource allocation policies, which can be trained with reinforcement learning. Through extensive numerical experiments we show that the proposed graph reinforcement learning approach yields policies that not only outperform baseline solutions and deep reinforcement learning based policies in large-scale systems, but that can also be transferred across networks of varying size.
Learning Connectivity-Maximizing Network Configurations
Dec 14, 2021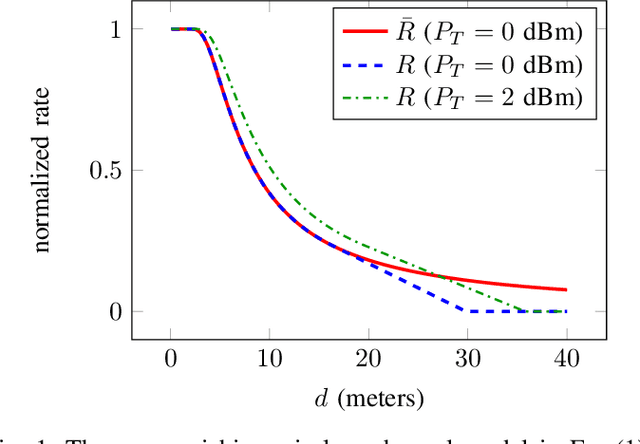
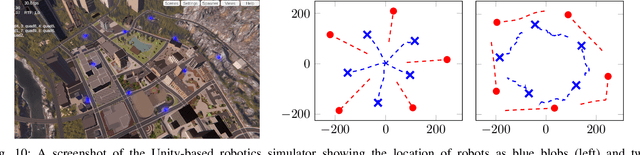
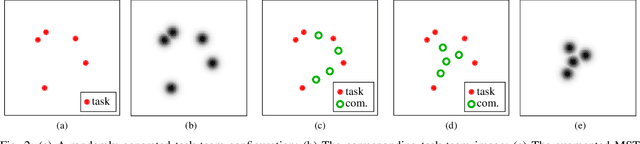

In this work we propose a data-driven approach to optimizing the algebraic connectivity of a team of robots. While a considerable amount of research has been devoted to this problem, we lack a method that scales in a manner suitable for online applications for more than a handful of agents. To that end, we propose a supervised learning approach with a convolutional neural network (CNN) that learns to place communication agents from an expert that uses an optimization-based strategy. We demonstrate the performance of our CNN on canonical line and ring topologies, 105k randomly generated test cases, and larger teams not seen during training. We also show how our system can be applied to dynamic robot teams through a Unity-based simulation. After training, our system produces connected configurations 2 orders of magnitude faster than the optimization-based scheme for teams of 10-20 agents.
Transferability Properties of Graph Neural Networks
Dec 09, 2021
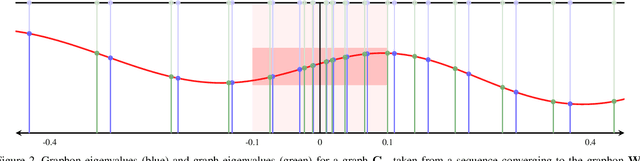
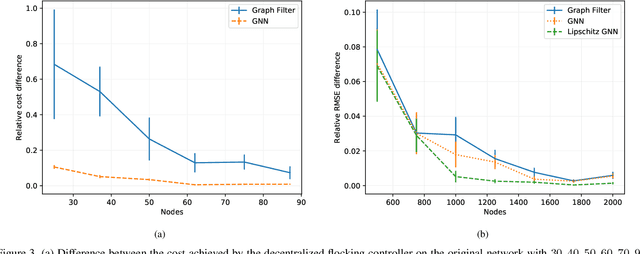
Graph neural networks (GNNs) are deep convolutional architectures consisting of layers composed by graph convolutions and pointwise nonlinearities. Due to their invariance and stability properties, GNNs are provably successful at learning representations from network data. However, training them requires matrix computations which can be expensive for large graphs. To address this limitation, we investigate the ability of GNNs to be transferred across graphs. We consider graphons, which are both graph limits and generative models for weighted and stochastic graphs, to define limit objects of graph convolutions and GNNs -- graphon convolutions and graphon neural networks (WNNs) -- which we use as generative models for graph convolutions and GNNs. We show that these graphon filters and WNNs can be approximated by graph filters and GNNs sampled from them on weighted and stochastic graphs. Using these results, we then derive error bounds for transferring graph filters and GNNs across such graphs. These bounds show that transferability increases with the graph size, and reveal a tradeoff between transferability and spectral discriminability which in GNNs is alleviated by the pointwise nonlinearities. These findings are further verified empirically in numerical experiments in movie recommendation and decentralized robot control.