 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Search of Relevant Points for Nearest-Neighbor Classification
Mar 07, 2022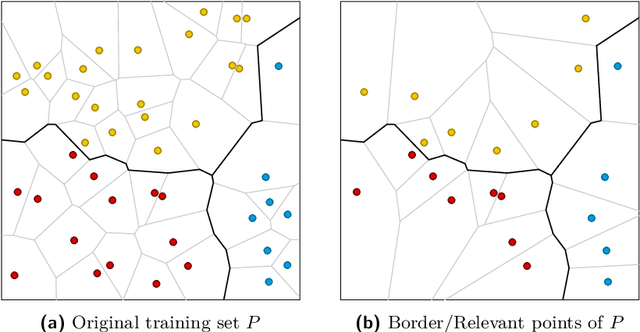
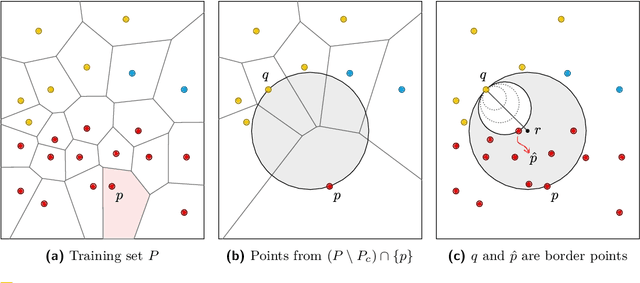
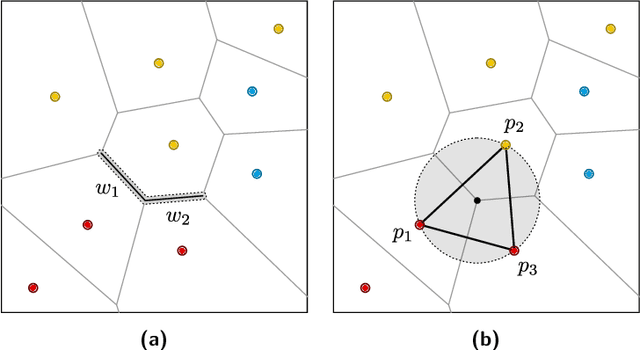
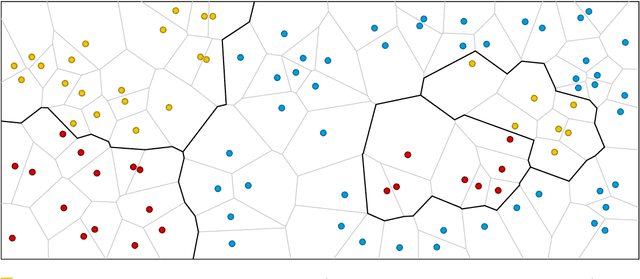
Given a training set $P \subset \mathbb{R}^d$, the nearest-neighbor classifier assigns any query point $q \in \mathbb{R}^d$ to the class of its closest point in $P$. To answer these classification queries, some training points are more relevant than others. We say a training point is relevant if its omission from the training set could induce the misclassification of some query point in $\mathbb{R}^d$. These relevant points are commonly known as border points, as they define the boundaries of the Voronoi diagram of $P$ that separate points of different classes. Being able to compute this set of points efficiently is crucial to reduce the size of the training set without affecting the accuracy of the nearest-neighbor classifier. Improving over a decades-long result by Clarkson, in a recent paper by Eppstein an output-sensitive algorithm was proposed to find the set of border points of $P$ in $O( n^2 + nk^2 )$ time, where $k$ is the size of such set. In this paper, we improve this algorithm to have time complexity equal to $O( nk^2 )$ by proving that the first steps of their algorithm, which require $O( n^2 )$ time, are unnecessary.
Social Distancing is Good for Points too!
Jun 28, 2020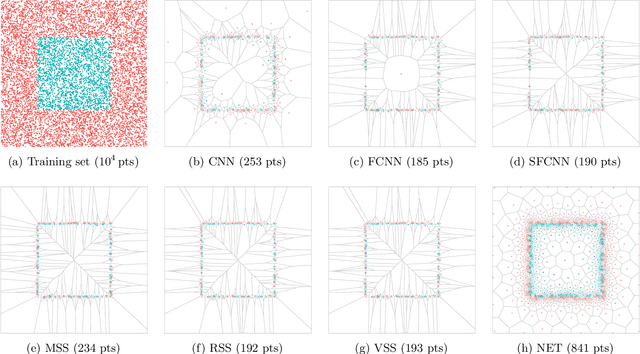
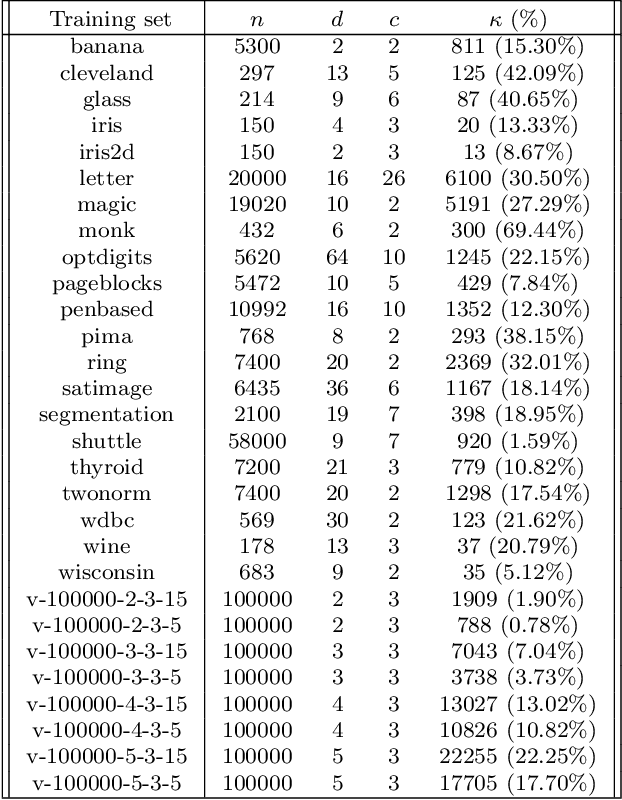
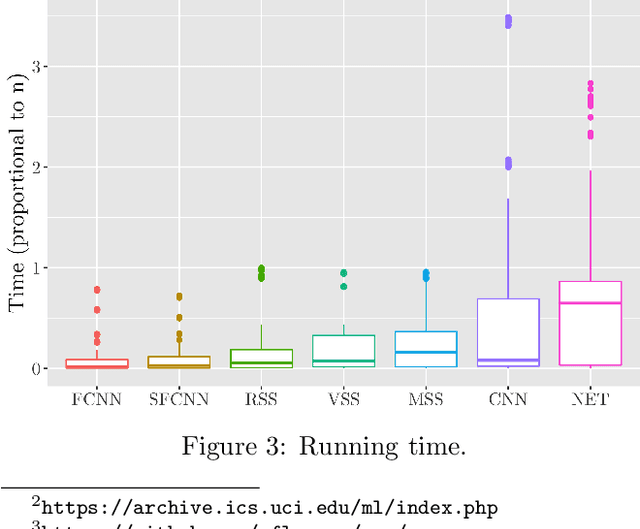
The nearest-neighbor rule is a well-known classification technique that, given a training set P of labeled points, classifies any unlabeled query point with the label of its closest point in P. The nearest-neighbor condensation problem aims to reduce the training set without harming the accuracy of the nearest-neighbor rule. FCNN is the most popular algorithm for condensation. It is heuristic in nature, and theoretical results for it are scarce. In this paper, we settle the question of whether reasonable upper-bounds can be proven for the size of the subset selected by FCNN. First, we show that the algorithm can behave poorly when points are too close to each other, forcing it to select many more points than necessary. We then successfully modify the algorithm to avoid such cases, thus imposing that selected points should "keep some distance". This modification is sufficient to prove useful upper-bounds, along with approximation guarantees for the algorithm.
Coresets for the Nearest-Neighbor Rule
Feb 19, 2020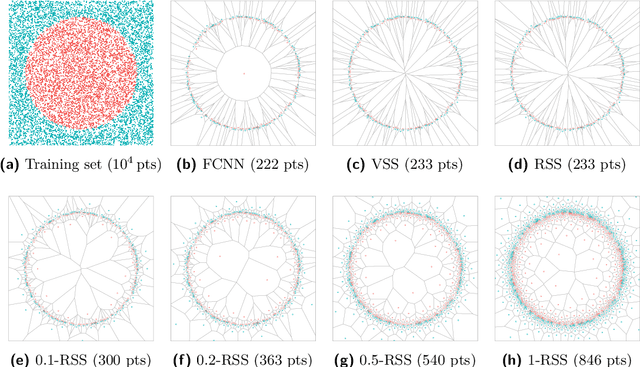
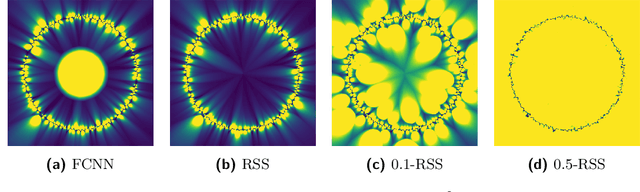
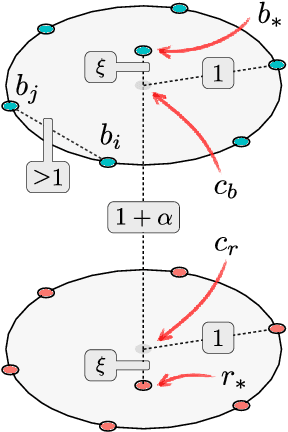
The problem of nearest-neighbor condensation deals with finding a subset $R$ from a set of labeled points $P$ such that for every point $p \in P$ the nearest-neighbor of $p$ in $R$ has the same label as $p$. This is motivated by applications in classification, where the nearest-neighbor rule assigns to an unlabeled query point the label of its nearest-neighbor in the point set. In this context, condensation aims to reduce the size of the set needed to classify new points. However, finding such subsets of minimum cardinality is NP-hard, and most research has focused on practical heuristics without performance guarantees. Additionally, the use of exact nearest-neighbors is always assumed, ignoring the effect of condensation in the classification accuracy when nearest-neighbors are computed approximately. In this paper, we address these shortcomings by proposing new approximation-sensitive criteria for the nearest-neighbor condensation problem, along with practical algorithms with provable performance guarantees. We characterize sufficient conditions to guarantee correct classification of unlabeled points using approximate nearest-neighbor queries on these subsets, which introduces the notion of coresets for classification with the nearest-neighbor rule. Moreover, we prove that it is NP-hard to compute subsets with these characteristics, whose cardinality approximates that of the minimum cardinality subset. Additionally, we propose new algorithms for computing such subsets, with tight approximation factors in general metrics, and improved factors for doubling metrics and $\ell_p$ metrics with $p\geq2$. Finally, we show an alternative implementation scheme that reduces the worst-case time complexity of one of these algorithms, becoming the first truly subquadratic approximation algorithm for the nearest-neighbor condensation problem.