 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers and Slot Encoding for Sample Efficient Physical World Modelling
May 30, 2024



World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Recent applications of the Transformer architecture to the problem of world modelling from video input show notable improvements in sample efficiency. However, existing approaches tend to work only at the image level thus disregarding that the environment is composed of objects interacting with each other. In this paper, we propose an architecture combining Transformers for world modelling with the slot-attention paradigm, an approach for learning representations of objects appearing in a scene. We describe the resulting neural architecture and report experimental results showing an improvement over the existing solutions in terms of sample efficiency and a reduction of the variation of the performance over the training examples. The code for our architecture and experiments is available at https://github.com/torchipeppo/transformers-and-slot-encoding-for-wm
Sandra -- A Neuro-Symbolic Reasoner Based On Descriptions And Situations
Feb 02, 2024



This paper presents sandra, a neuro-symbolic reasoner combining vectorial representations with deductive reasoning. Sandra builds a vector space constrained by an ontology and performs reasoning over it. The geometric nature of the reasoner allows its combination with neural networks, bridging the gap with symbolic knowledge representations. Sandra is based on the Description and Situation (DnS) ontology design pattern, a formalization of frame semantics. Given a set of facts (a situation) it allows to infer all possible perspectives (descriptions) that can provide a plausible interpretation for it, even in presence of incomplete information. We prove that our method is correct with respect to the DnS model. We experiment with two different tasks and their standard benchmarks, demonstrating that, without increasing complexity, sandra (i) outperforms all the baselines (ii) provides interpretability in the classification process, and (iii) allows control over the vector space, which is designed a priori.
EFO: the Emotion Frame Ontology
Jan 19, 2024Emotions are a subject of intense debate in various disciplines. Despite the proliferation of theories and definitions, there is still no consensus on what emotions are, and how to model the different concepts involved when we talk about - or categorize - them. In this paper, we propose an OWL frame-based ontology of emotions: the Emotion Frames Ontology (EFO). EFO treats emotions as semantic frames, with a set of semantic roles that capture the different aspects of emotional experience. EFO follows pattern-based ontology design, and is aligned to the DOLCE foundational ontology. EFO is used to model multiple emotion theories, which can be cross-linked as modules in an Emotion Ontology Network. In this paper, we exemplify it by modeling Ekman's Basic Emotions (BE) Theory as an EFO-BE module, and demonstrate how to perform automated inferences on the representation of emotion situations. EFO-BE has been evaluated by lexicalizing the BE emotion frames from within the Framester knowledge graph, and implementing a graph-based emotion detector from text. In addition, an EFO integration of multimodal datasets, including emotional speech and emotional face expressions, has been performed to enable further inquiry into crossmodal emotion semantics.
DOLCE: A Descriptive Ontology for Linguistic and Cognitive Engineering
Aug 03, 2023



DOLCE, the first top-level (foundational) ontology to be axiomatized, has remained stable for twenty years and today is broadly used in a variety of domains. DOLCE is inspired by cognitive and linguistic considerations and aims to model a commonsense view of reality, like the one human beings exploit in everyday life in areas as diverse as socio-technical systems, manufacturing, financial transactions and cultural heritage. DOLCE clearly lists the ontological choices it is based upon, relies on philosophical principles, is richly formalized, and is built according to well-established ontological methodologies, e.g. OntoClean. Because of these features, it has inspired most of the existing top-level ontologies and has been used to develop or improve standards and public domain resources (e.g. CIDOC CRM, DBpedia and WordNet). Being a foundational ontology, DOLCE is not directly concerned with domain knowledge. Its purpose is to provide the general categories and relations needed to give a coherent view of reality, to integrate domain knowledge, and to mediate across domains. In these 20 years DOLCE has shown that applied ontologies can be stable and that interoperability across reference and domain ontologies is a reality. This paper briefly introduces the ontology and shows how to use it on a few modeling cases.
* 25 pages, 7 figures
The Music Note Ontology
Mar 30, 2023In this paper we propose the Music Note Ontology, an ontology for modelling music notes and their realisation. The ontology addresses the relation between a note represented in a symbolic representation system, and its realisation, i.e. a musical performance. This work therefore aims to solve the modelling and representation issues that arise when analysing the relationships between abstract symbolic features and the corresponding physical features of an audio signal. The ontology is composed of three different Ontology Design Patterns (ODP), which model the structure of the score (Score Part Pattern), the note in the symbolic notation (Music Note Pattern) and its realisation (Musical Object Pattern).
That's All Folks: a KG of Values as Commonsense Social Norms and Behaviors
Mar 01, 2023Values, as intended in ethics, determine the shape and validity of moral and social norms, grounding our everyday individual and community behavior on commonsense knowledge. Formalising latent moral content in human interaction is an appealing perspective that would enable a deeper understanding of both social dynamics and individual cognitive and behavioral dimension. To tackle this problem, several theoretical frameworks offer different values models, and organize them into different taxonomies. The problem of the most used theories is that they adopt a cultural-independent perspective while many entities that are considered "values" are grounded in commonsense knowledge and expressed in everyday life interaction. We propose here two ontological modules, FOLK, an ontology for values intended in their broad sense, and That's All Folks, a module for lexical and factual folk value triggers, whose purpose is to complement the main theories, providing a method for identifying the values that are not contemplated by the major value theories, but which nonetheless play a key role in daily human interactions, and shape social structures, cultural biases, and personal beliefs. The resource is tested via performing automatic detection of values from text with a frame-based approach.
Is Your Model Sensitive? SPeDaC: A New Benchmark for Detecting and Classifying Sensitive Personal Data
Aug 12, 2022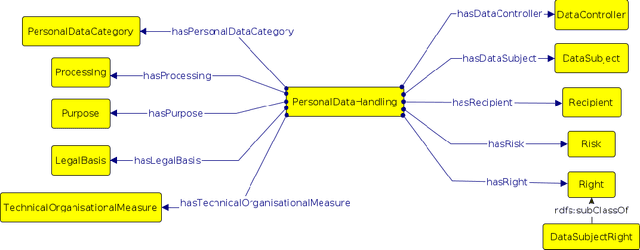

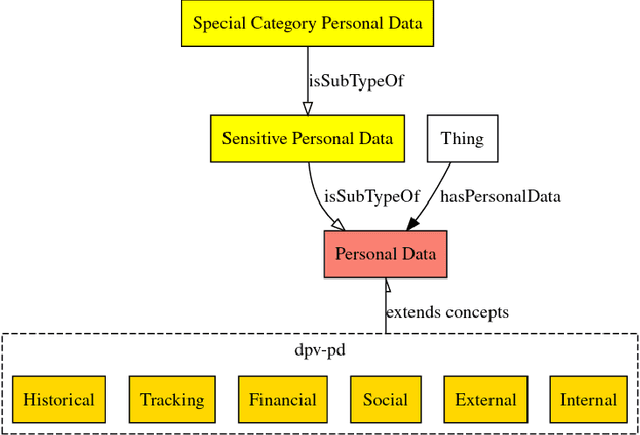

In recent years we have seen the exponential growth of applications, including dialogue systems, that handle sensitive personal information. This has brought to light the extremely important issue regarding personal data protection in virtual environments. Firstly, a performing model should be able to distinguish sentences with sensitive content from neutral sentences. Secondly, it should be able to identify the type of personal data category contained in them. In this way, a different privacy treatment could be considered for each category. In literature, if there are works on automatic sensitive data identification, these are often conducted on different domains or languages without a common benchmark. To fill this gap, in this work we introduce SPeDaC, a new annotated benchmark for the identification of sensitive personal data categories. Furthermore, we provide an extensive evaluation of our dataset, conducted using different baselines and a classifier based on RoBERTa, a neural architecture that achieves strong performances on the detection of sensitive sentences and on the personal data categories classification.
Automatically Drafting Ontologies from Competency Questions with FrODO
Jun 06, 2022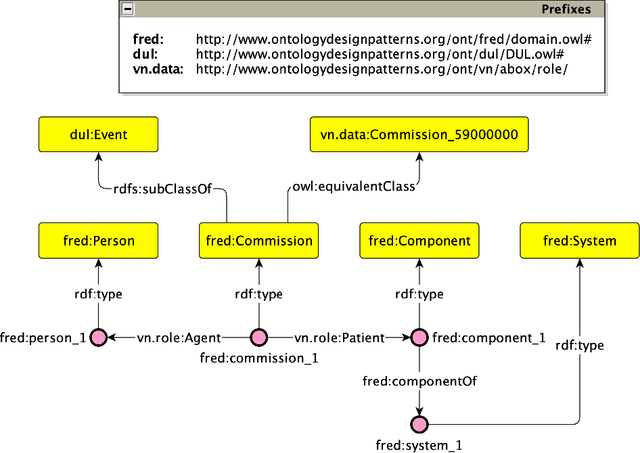


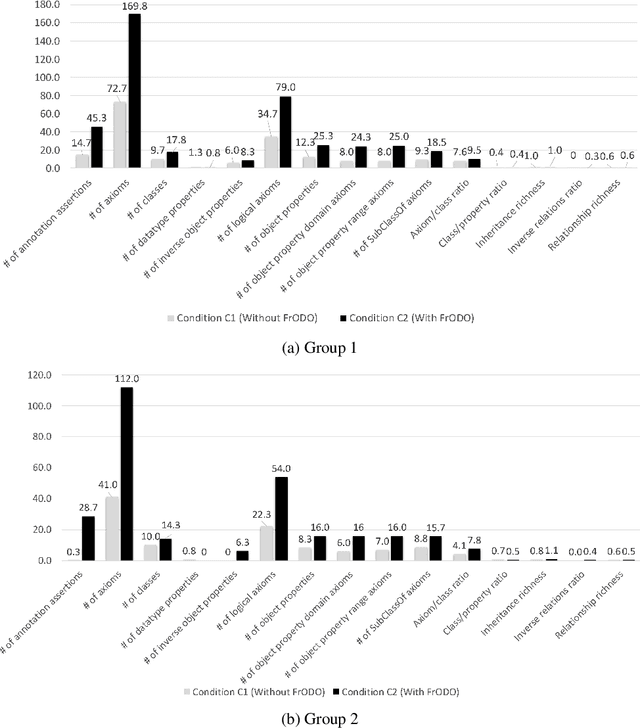
We present the Frame-based ontology Design Outlet (FrODO), a novel method and tool for drafting ontologies from competency questions automatically. Competency questions are expressed as natural language and are a common solution for representing requirements in a number of agile ontology engineering methodologies, such as the eXtreme Design (XD) or SAMOD. FrODO builds on top of FRED. In fact, it leverages the frame semantics for drawing domain-relevant boundaries around the RDF produced by FRED from a competency question, thus drafting domain ontologies. We carried out a user-based study for assessing FrODO in supporting engineers for ontology design tasks. The study shows that FrODO is effective in this and the resulting ontology drafts are qualitative.
The HaMSE Ontology: Using Semantic Technologies to support Music Representation Interoperability and Musicological Analysis
Feb 11, 2022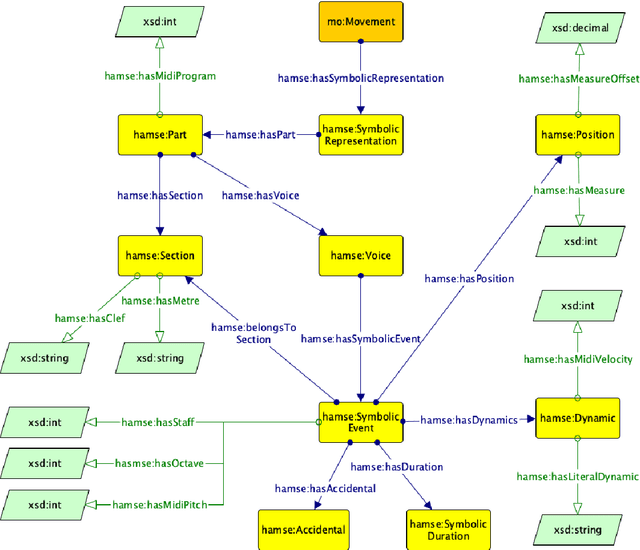
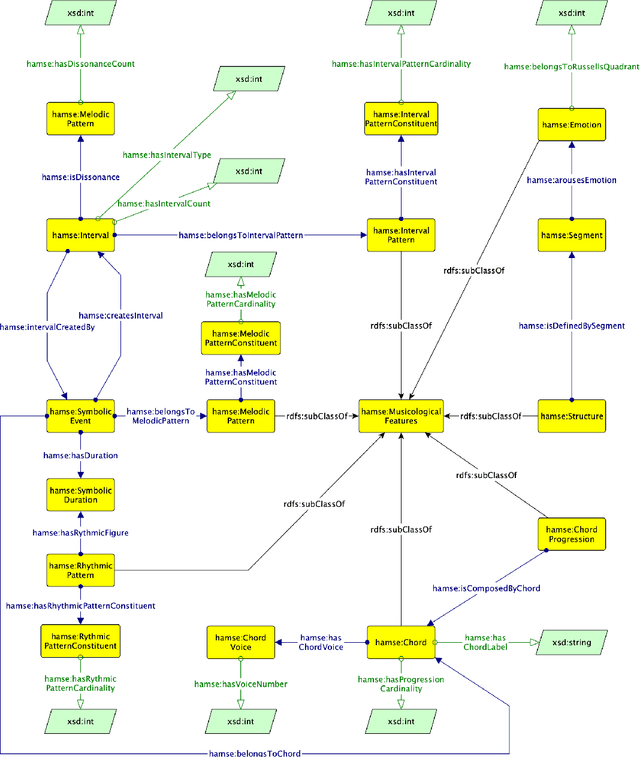
The use of Semantic Technologies - in particular the Semantic Web - has revealed to be a great tool for describing the cultural heritage domain and artistic practices. However, the panorama of ontologies for musicological applications seems to be limited and restricted to specific applications. In this research, we propose HaMSE, an ontology capable of describing musical features that can assist musicological research. More specifically, HaMSE proposes to address sues that have been affecting musicological research for decades: the representation of music and the relationship between quantitative and qualitative data. To do this, HaMSE allows the alignment between different music representation systems and describes a set of musicological features that can allow the music analysis at different granularity levels.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
Jan 24, 2022


Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.