 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Training Scaling for Chemical Exploration in Drug Design
Jan 31, 2025



Chemical language models for molecular design have the potential to find solutions to multi-parameter optimization problems in drug discovery via reinforcement learning (RL). A key requirement to achieve this is the capacity to "search" chemical space to identify all molecules of interest. Here, we propose a challenging new benchmark to discover dissimilar molecules that possess similar bioactivity, a common scenario in drug discovery, but a hard problem to optimize. We show that a population of RL agents can solve the benchmark, while a single agent cannot. We also find that cooperative strategies are not significantly better than independent agents. Moreover, the performance on the benchmark scales log-linearly with the number of independent agents, showing a test-time training scaling law for chemical language models.
REINFORCE-ING Chemical Language Models in Drug Design
Jan 27, 2025



Chemical language models, combined with reinforcement learning, have shown significant promise to efficiently traverse large chemical spaces in drug design. However, the performance of various RL algorithms and their best practices for practical drug design are still unclear. Here, starting from the principles of the REINFORCE algorithm, we investigate the effect of different components from RL theory including experience replay, hill-climbing, baselines to reduce variance, and alternative reward shaping. Additionally we demonstrate how RL hyperparameters can be fine-tuned for effectiveness, efficiency, or chemical regularization as demonstrated using the MolOpt benchmark.
Aviary: training language agents on challenging scientific tasks
Dec 30, 2024



Solving complex real-world tasks requires cycles of actions and observations. This is particularly true in science, where tasks require many cycles of analysis, tool use, and experimentation. Language agents are promising for automating intellectual tasks in science because they can interact with tools via natural language or code. Yet their flexibility creates conceptual and practical challenges for software implementations, since agents may comprise non-standard components such as internal reasoning, planning, tool usage, as well as the inherent stochasticity of temperature-sampled language models. Here, we introduce Aviary, an extensible gymnasium for language agents. We formalize agents as policies solving language-grounded partially observable Markov decision processes, which we term language decision processes. We then implement five environments, including three challenging scientific environments: (1) manipulating DNA constructs for molecular cloning, (2) answering research questions by accessing scientific literature, and (3) engineering protein stability. These environments were selected for their focus on multi-step reasoning and their relevance to contemporary biology research. Finally, with online training and scaling inference-time compute, we show that language agents backed by open-source, non-frontier LLMs can match and exceed both frontier LLM agents and human experts on multiple tasks at up to 100x lower inference cost.
ACEGEN: Reinforcement learning of generative chemical agents for drug discovery
May 07, 2024



In recent years, reinforcement learning (RL) has emerged as a valuable tool in drug design, offering the potential to propose and optimize molecules with desired properties. However, striking a balance between capability, flexibility, and reliability remains challenging due to the complexity of advanced RL algorithms and the significant reliance on specialized code. In this work, we introduce ACEGEN, a comprehensive and streamlined toolkit tailored for generative drug design, built using TorchRL, a modern decision-making library that offers efficient and thoroughly tested reusable components. ACEGEN provides a robust, flexible, and efficient platform for molecular design. We validate its effectiveness by benchmarking it across various algorithms and conducting multiple drug discovery case studies. ACEGEN is accessible at https://github.com/acellera/acegen-open.
TorchRL: A data-driven decision-making library for PyTorch
Jun 01, 2023Striking a balance between integration and modularity is crucial for a machine learning library to be versatile and user-friendly, especially in handling decision and control tasks that involve large development teams and complex, real-world data, and environments. To address this issue, we propose TorchRL, a generalistic control library for PyTorch that provides well-integrated, yet standalone components. With a versatile and robust primitive design, TorchRL facilitates streamlined algorithm development across the many branches of Reinforcement Learning (RL) and control. We introduce a new PyTorch primitive, TensorDict, as a flexible data carrier that empowers the integration of the library's components while preserving their modularity. Hence replay buffers, datasets, distributed data collectors, environments, transforms and objectives can be effortlessly used in isolation or combined. We provide a detailed description of the building blocks, supporting code examples and an extensive overview of the library across domains and tasks. Finally, we show comparative benchmarks to demonstrate its computational efficiency. TorchRL fosters long-term support and is publicly available on GitHub for greater reproducibility and collaboration within the research community. The code is opensourced on https://github.com/pytorch/rl.
NAPPO: Modular and scalable reinforcement learning in pytorch
Jul 06, 2020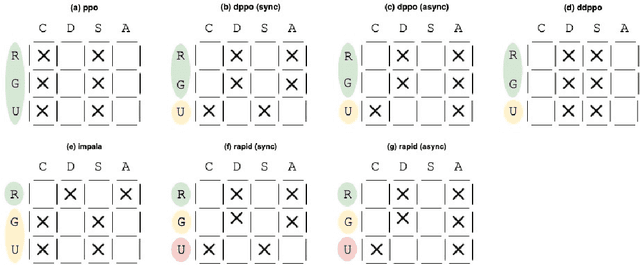

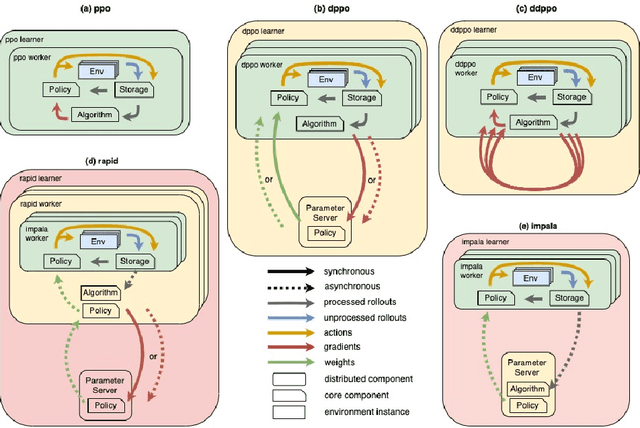
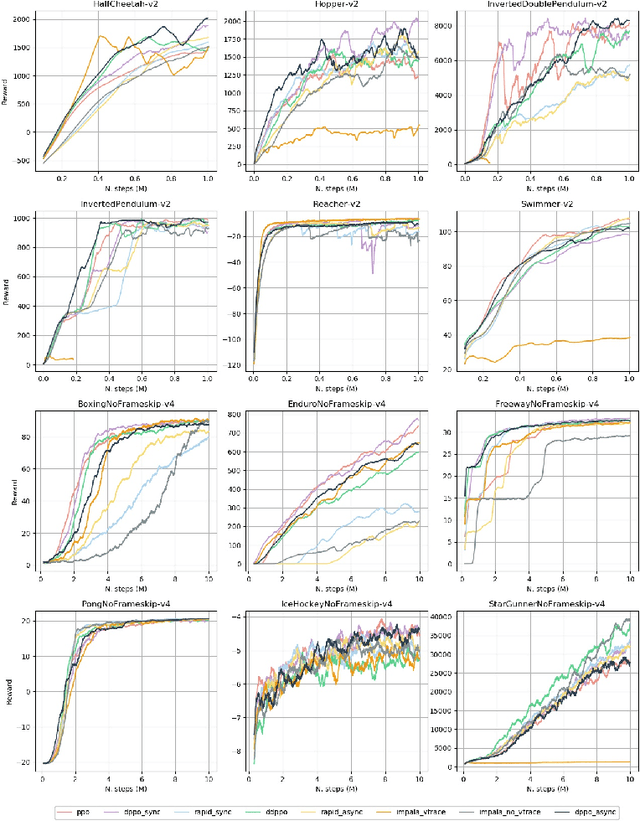
Reinforcement learning (RL) has been very successful in recent years but, limited by its sample inefficiency, often requires large computational resources. While new methods are being investigated to increase the efficiency of RL algorithms it is critical to enable training at scale, yet using a code-base flexible enough to allow for method experimentation. Here, we present NAPPO, a pytorch-based library for RL which provides scalable proximal policy optimization (PPO) implementations in a simple, modular package. We validate it by replicating previous results on Mujoco and Atari environments. Furthermore, we provide insights on how a variety of distributed training schemes with synchronous and asynchronous communication patterns perform. Finally we showcase NAPPO by obtaining the highest to-date test performance on the Obstacle Tower Unity3D challenge environment. The full source code is available.