 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP Techniques for Water Quality Analysis in Social Media Content
Nov 30, 2021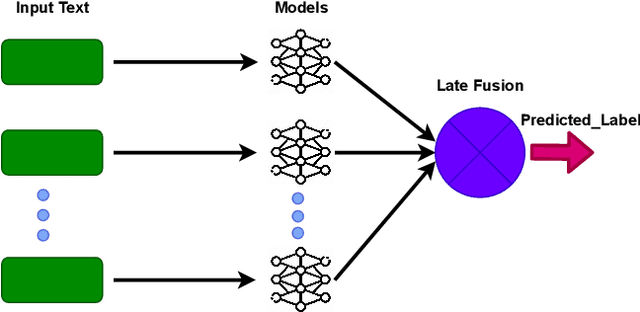
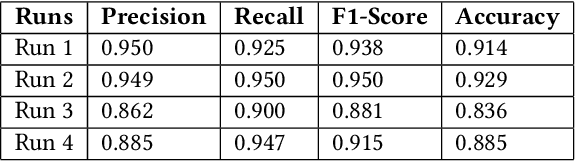
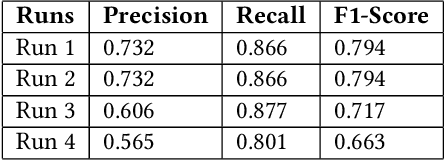
This paper presents our contributions to the MediaEval 2021 task namely "WaterMM: Water Quality in Social Multimedia". The task aims at analyzing social media posts relevant to water quality with particular focus on the aspects like watercolor, smell, taste, and related illnesses. To this aim, a multimodal dataset containing both textual and visual information along with meta-data is provided. Considering the quality and quantity of available content, we mainly focus on textual information by employing three different models individually and jointly in a late-fusion manner. These models include (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and a (iii) custom Long short-term memory (LSTM) model obtaining an overall F1-score of 0.794, 0.717, 0.663 on the official test set, respectively. In the fusion scheme, all the models are treated equally and no significant improvement is observed in the performance over the best performing individual model.
Deep Models for Visual Sentiment Analysis of Disaster-related Multimedia Content
Nov 30, 2021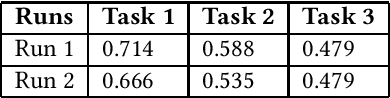
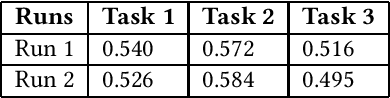
This paper presents a solutions for the MediaEval 2021 task namely "Visual Sentiment Analysis: A Natural Disaster Use-case". The task aims to extract and classify sentiments perceived by viewers and the emotional message conveyed by natural disaster-related images shared on social media. The task is composed of three sub-tasks including, one single label multi-class image classification task, and, two multi-label multi-class image classification tasks, with different sets of labels. In our proposed solutions, we rely mainly on two different state-of-the-art models namely, Inception-v3 and VggNet-19, pre-trained on ImageNet, which are fine-tuned for each of the three task using different strategies. Overall encouraging results are obtained on all the three tasks. On the single-label classification task (i.e. Task 1), we obtained the weighted average F1-scores of 0.540 and 0.526 for the Inception-v3 and VggNet-19 based solutions, respectively. On the multi-label classification i.e., Task 2 and Task 3, the weighted F1-score of our Inception-v3 based solutions was 0.572 and 0.516, respectively. Similarly, the weighted F1-score of our VggNet-19 based solution on Task 2 and Task 3 was 0.584 and 0.495, respectively.
Visual Sentiment Analysis: A Natural DisasterUse-case Task at MediaEval 2021
Nov 22, 2021The Visual Sentiment Analysis task is being offered for the first time at MediaEval. The main purpose of the task is to predict the emotional response to images of natural disasters shared on social media. Disaster-related images are generally complex and often evoke an emotional response, making them an ideal use case of visual sentiment analysis. We believe being able to perform meaningful analysis of natural disaster-related data could be of great societal importance, and a joint effort in this regard can open several interesting directions for future research. The task is composed of three sub-tasks, each aiming to explore a different aspect of the challenge. In this paper, we provide a detailed overview of the task, the general motivation of the task, and an overview of the dataset and the metrics to be used for the evaluation of the proposed solutions.
Adversarial Attacks and Defenses for Social Network Text Processing Applications: Techniques, Challenges and Future Research Directions
Oct 26, 2021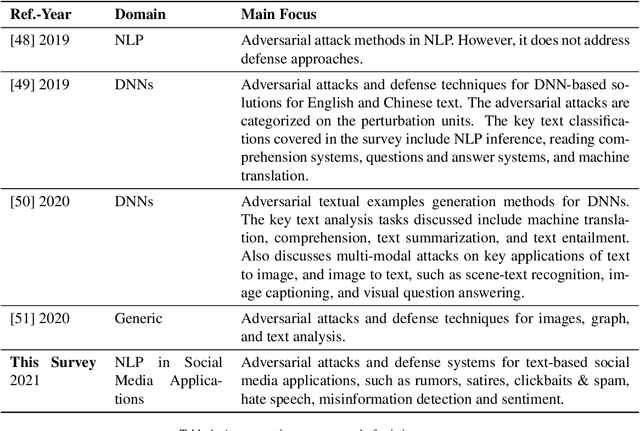
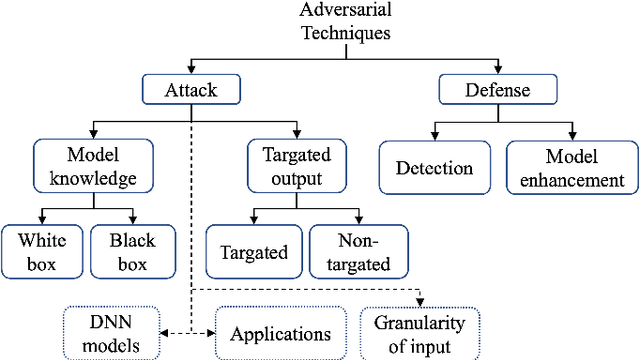
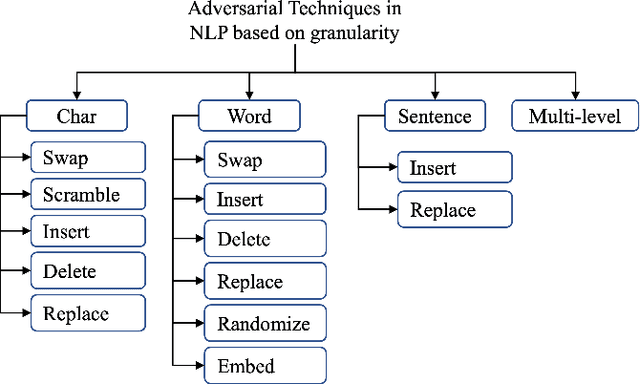

The growing use of social media has led to the development of several Machine Learning (ML) and Natural Language Processing(NLP) tools to process the unprecedented amount of social media content to make actionable decisions. However, these MLand NLP algorithms have been widely shown to be vulnerable to adversarial attacks. These vulnerabilities allow adversaries to launch a diversified set of adversarial attacks on these algorithms in different applications of social media text processing. In this paper, we provide a comprehensive review of the main approaches for adversarial attacks and defenses in the context of social media applications with a particular focus on key challenges and future research directions. In detail, we cover literature on six key applications, namely (i) rumors detection, (ii) satires detection, (iii) clickbait & spams identification, (iv) hate speech detection, (v)misinformation detection, and (vi) sentiment analysis. We then highlight the concurrent and anticipated future research questions and provide recommendations and directions for future work.
Explainable Event Recognition
Oct 10, 2021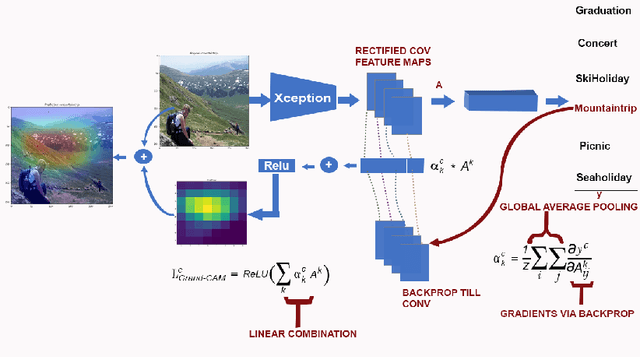
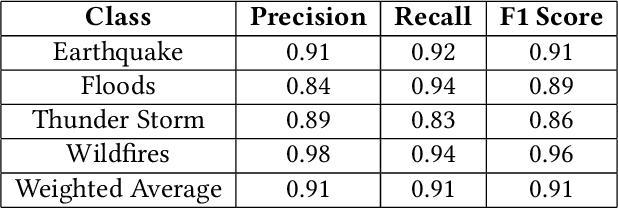

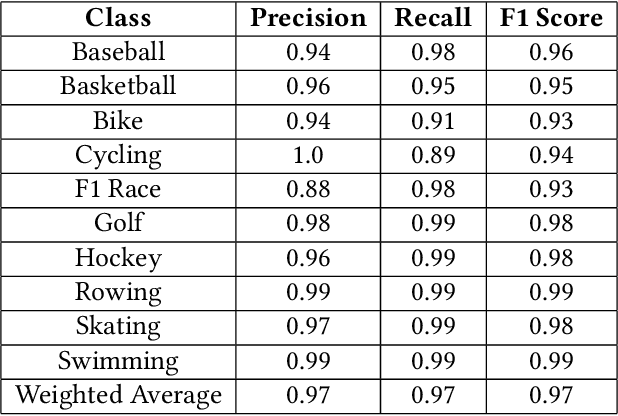
The literature shows outstanding capabilities for CNNs in event recognition in images. However, fewer attempts are made to analyze the potential causes behind the decisions of the models and exploring whether the predictions are based on event-salient objects or regions? To explore this important aspect of event recognition, in this work, we propose an explainable event recognition framework relying on Grad-CAM and an Xception architecture-based CNN model. Experiments are conducted on three large-scale datasets covering a diversified set of natural disasters, social, and sports events. Overall, the model showed outstanding generalization capabilities obtaining overall F1-scores of 0.91, 0.94, and 0.97 on natural disasters, social, and sports events, respectively. Moreover, for subjective analysis of activation maps generated through Grad-CAM for the predicted samples of the model, a crowdsourcing study is conducted to analyze whether the model's predictions are based on event-related objects/regions or not? The results of the study indicate that 78%, 84%, and 78% of the model decisions on natural disasters, sports, and social events datasets, respectively, are based onevent-related objects or regions.
Client Selection Approach in Support of Clustered Federated Learning over Wireless Edge Networks
Aug 16, 2021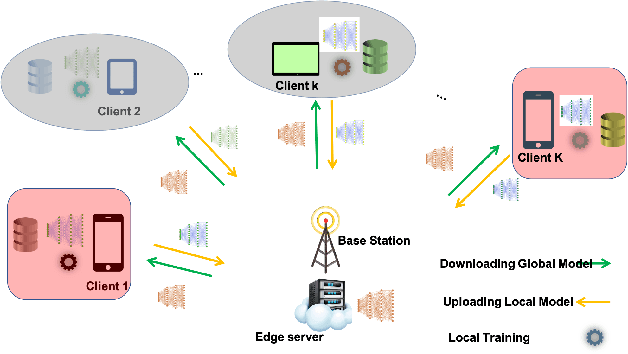
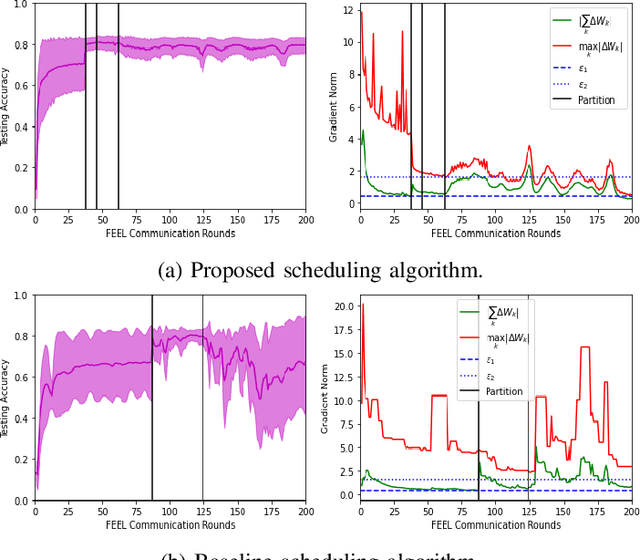
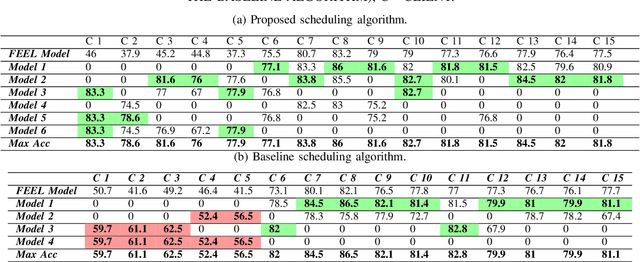
Clustered Federated Multitask Learning (CFL) was introduced as an efficient scheme to obtain reliable specialized models when data is imbalanced and distributed in a non-i.i.d. (non-independent and identically distributed) fashion amongst clients. While a similarity measure metric, like the cosine similarity, can be used to endow groups of the client with a specialized model, this process can be arduous as the server should involve all clients in each of the federated learning rounds. Therefore, it is imperative that a subset of clients is selected periodically due to the limited bandwidth and latency constraints at the network edge. To this end, this paper proposes a new client selection algorithm that aims to accelerate the convergence rate for obtaining specialized machine learning models that achieve high test accuracies for all client groups. Specifically, we introduce a client selection approach that leverages the devices' heterogeneity to schedule the clients based on their round latency and exploits the bandwidth reuse for clients that consume more time to update the model. Then, the server performs model averaging and clusters the clients based on predefined thresholds. When a specific cluster reaches a stationary point, the proposed algorithm uses a greedy scheduling algorithm for that group by selecting the clients with less latency to update the model. Extensive experiments show that the proposed approach lowers the training time and accelerates the convergence rate by up to 50% while imbuing each client with a specialized model that is fit for its local data distribution.
Fine-Grained Data Selection for Improved Energy Efficiency of Federated Edge Learning
Jun 20, 2021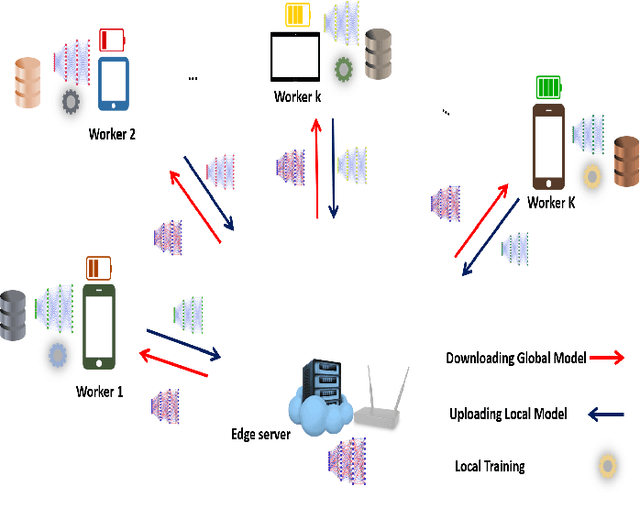
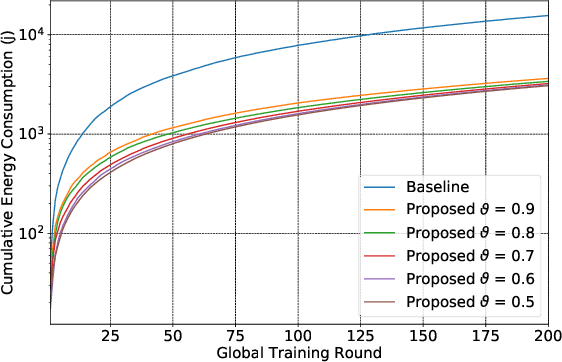
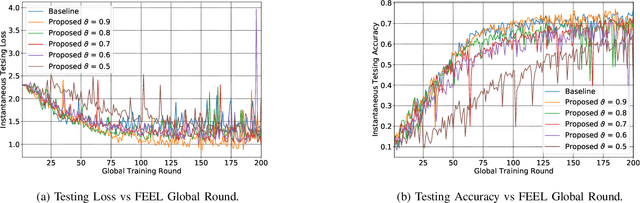
In Federated edge learning (FEEL), energy-constrained devices at the network edge consume significant energy when training and uploading their local machine learning models, leading to a decrease in their lifetime. This work proposes novel solutions for energy-efficient FEEL by jointly considering local training data, available computation, and communications resources, and deadline constraints of FEEL rounds to reduce energy consumption. This paper considers a system model where the edge server is equipped with multiple antennas employing beamforming techniques to communicate with the local users through orthogonal channels. Specifically, we consider a problem that aims to find the optimal user's resources, including the fine-grained selection of relevant training samples, bandwidth, transmission power, beamforming weights, and processing speed with the goal of minimizing the total energy consumption given a deadline constraint on the communication rounds of FEEL. Then, we devise tractable solutions by first proposing a novel fine-grained training algorithm that excludes less relevant training samples and effectively chooses only the samples that improve the model's performance. After that, we derive closed-form solutions, followed by a Golden-Section-based iterative algorithm to find the optimal computation and communication resources that minimize energy consumption. Experiments using MNIST and CIFAR-10 datasets demonstrate that our proposed algorithms considerably outperform the state-of-the-art solutions as energy consumption decreases by 79% for MNIST and 73% for CIFAR-10 datasets.
Deep Reinforcement Learning for Radio Resource Allocation and Management in Next Generation Heterogeneous Wireless Networks: A Survey
May 25, 2021Next generation wireless networks are expected to be extremely complex due to their massive heterogeneity in terms of the types of network architectures they incorporate, the types and numbers of smart IoT devices they serve, and the types of emerging applications they support. In such large-scale and heterogeneous networks (HetNets), radio resource allocation and management (RRAM) becomes one of the major challenges encountered during system design and deployment. In this context, emerging Deep Reinforcement Learning (DRL) techniques are expected to be one of the main enabling technologies to address the RRAM in future wireless HetNets. In this paper, we conduct a systematic in-depth, and comprehensive survey of the applications of DRL techniques in RRAM for next generation wireless networks. Towards this, we first overview the existing traditional RRAM methods and identify their limitations that motivate the use of DRL techniques in RRAM. Then, we provide a comprehensive review of the most widely used DRL algorithms to address RRAM problems, including the value- and policy-based algorithms. The advantages, limitations, and use-cases for each algorithm are provided. We then conduct a comprehensive and in-depth literature review and classify existing related works based on both the radio resources they are addressing and the type of wireless networks they are investigating. To this end, we carefully identify the types of DRL algorithms utilized in each related work, the elements of these algorithms, and the main findings of each related work. Finally, we highlight important open challenges and provide insights into several future research directions in the context of DRL-based RRAM. This survey is intentionally designed to guide and stimulate more research endeavors towards building efficient and fine-grained DRL-based RRAM schemes for future wireless networks.
The Duo of Artificial Intelligence and Big Data for Industry 4.0: Review of Applications, Techniques, Challenges, and Future Research Directions
Apr 07, 2021
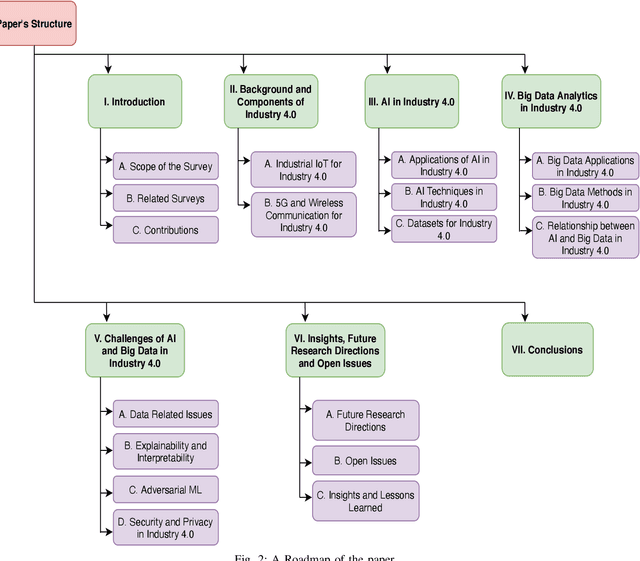
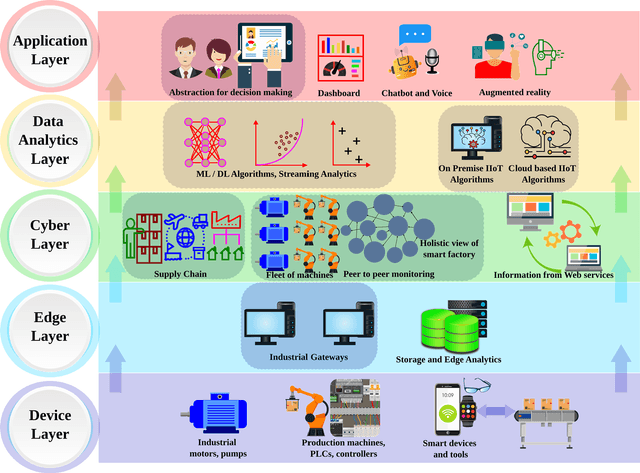
The increasing need for economic, safe, and sustainable smart manufacturing combined with novel technological enablers, has paved the way for Artificial Intelligence (AI) and Big Data in support of smart manufacturing. This implies a substantial integration of AI, Industrial Internet of Things (IIoT), Robotics, Big data, Blockchain, 5G communications, in support of smart manufacturing and the dynamical processes in modern industries. In this paper, we provide a comprehensive overview of different aspects of AI and Big Data in Industry 4.0 with a particular focus on key applications, techniques, the concepts involved, key enabling technologies, challenges, and research perspective towards deployment of Industry 5.0. In detail, we highlight and analyze how the duo of AI and Big Data is helping in different applications of Industry 4.0. We also highlight key challenges in a successful deployment of AI and Big Data methods in smart industries with a particular emphasis on data-related issues, such as availability, bias, auditing, management, interpretability, communication, and different adversarial attacks and security issues. In a nutshell, we have explored the significance of AI and Big data towards Industry 4.0 applications through panoramic reviews and discussions. We believe, this work will provide a baseline for future research in the domain.
Intelligent Building Control Systems for Thermal Comfort and Energy-Efficiency: A Systematic Review of Artificial Intelligence-Assisted Techniques
Apr 06, 2021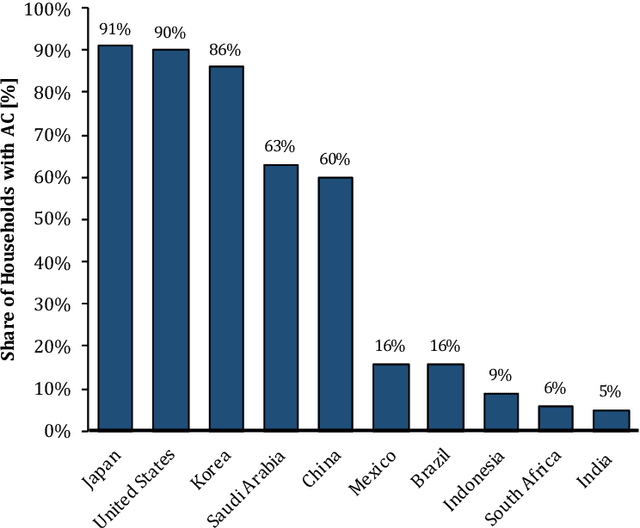

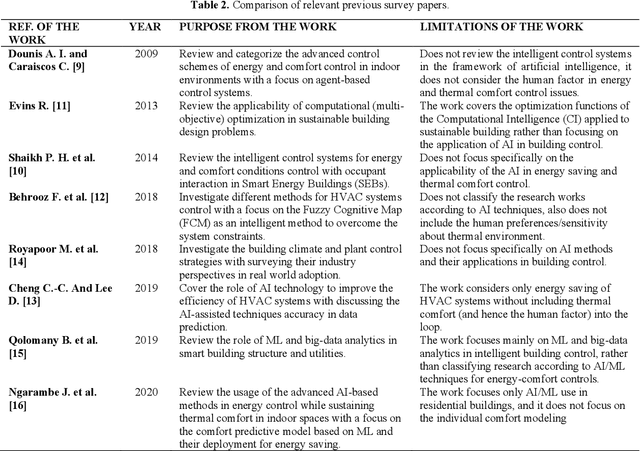
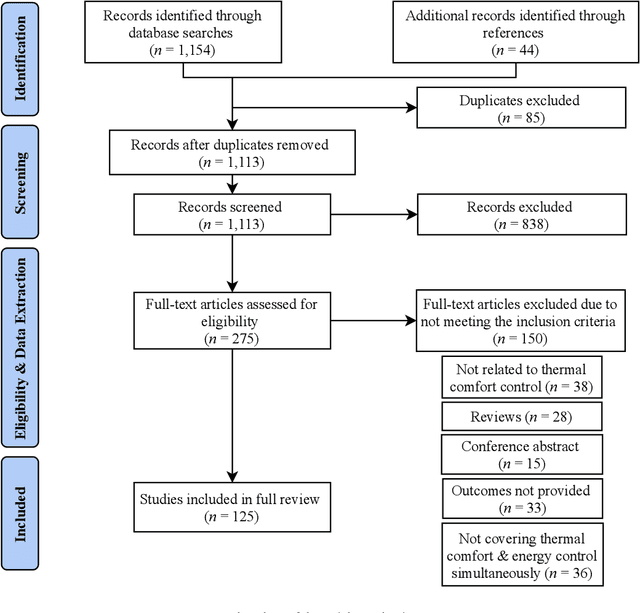
Building operations represent a significant percentage of the total primary energy consumed in most countries due to the proliferation of Heating, Ventilation and Air-Conditioning (HVAC) installations in response to the growing demand for improved thermal comfort. Reducing the associated energy consumption while maintaining comfortable conditions in buildings are conflicting objectives and represent a typical optimization problem that requires intelligent system design. Over the last decade, different methodologies based on the Artificial Intelligence (AI) techniques have been deployed to find the sweet spot between energy use in HVAC systems and suitable indoor comfort levels to the occupants. This paper performs a comprehensive and an in-depth systematic review of AI-based techniques used for building control systems by assessing the outputs of these techniques, and their implementations in the reviewed works, as well as investigating their abilities to improve the energy-efficiency, while maintaining thermal comfort conditions. This enables a holistic view of (1) the complexities of delivering thermal comfort to users inside buildings in an energy-efficient way, and (2) the associated bibliographic material to assist researchers and experts in the field in tackling such a challenge. Among the 20 AI tools developed for both energy consumption and comfort control, functions such as identification and recognition patterns, optimization, predictive control. Based on the findings of this work, the application of AI technology in building control is a promising area of research and still an ongoing, i.e., the performance of AI-based control is not yet completely satisfactory. This is mainly due in part to the fact that these algorithms usually need a large amount of high-quality real-world data, which is lacking in the building or, more precisely, the energy sector.