 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwiSent: A Multistage System for Analyzing Sentiment in Twitter
Sep 18, 2012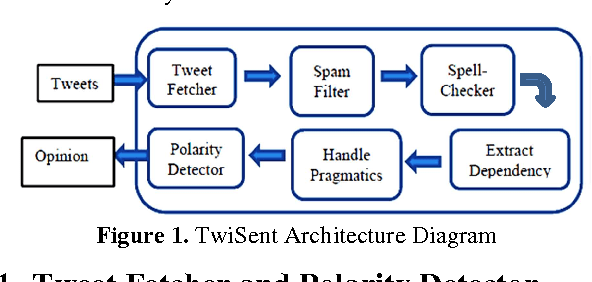
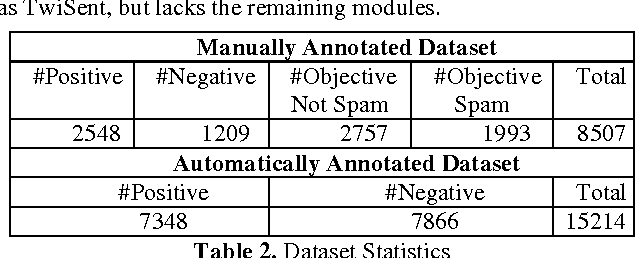
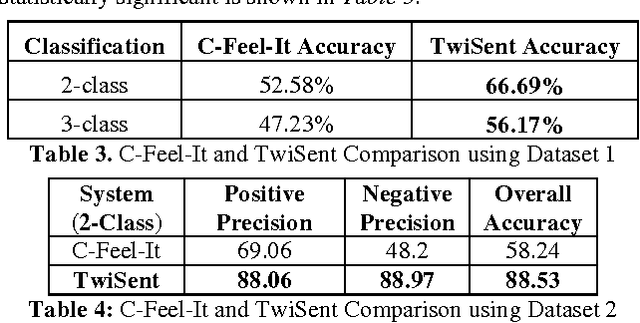
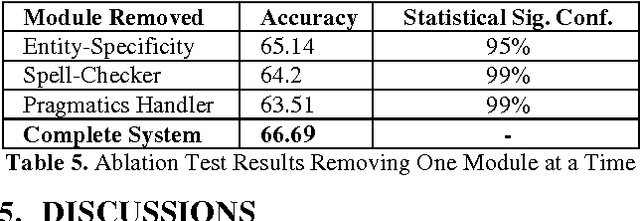
In this paper, we present TwiSent, a sentiment analysis system for Twitter. Based on the topic searched, TwiSent collects tweets pertaining to it and categorizes them into the different polarity classes positive, negative and objective. However, analyzing micro-blog posts have many inherent challenges compared to the other text genres. Through TwiSent, we address the problems of 1) Spams pertaining to sentiment analysis in Twitter, 2) Structural anomalies in the text in the form of incorrect spellings, nonstandard abbreviations, slangs etc., 3) Entity specificity in the context of the topic searched and 4) Pragmatics embedded in text. The system performance is evaluated on manually annotated gold standard data and on an automatically annotated tweet set based on hashtags. It is a common practise to show the efficacy of a supervised system on an automatically annotated dataset. However, we show that such a system achieves lesser classification accurcy when tested on generic twitter dataset. We also show that our system performs much better than an existing system.
* The paper is available at http://subhabrata-mukherjee.webs.com/publications.htm
Leveraging Sentiment to Compute Word Similarity
Sep 18, 2012


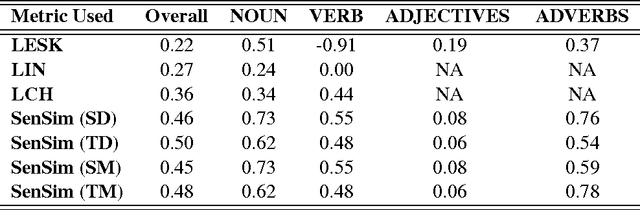
In this paper, we introduce a new WordNet based similarity metric, SenSim, which incorporates sentiment content (i.e., degree of positive or negative sentiment) of the words being compared to measure the similarity between them. The proposed metric is based on the hypothesis that knowing the sentiment is beneficial in measuring the similarity. To verify this hypothesis, we measure and compare the annotator agreement for 2 annotation strategies: 1) sentiment information of a pair of words is considered while annotating and 2) sentiment information of a pair of words is not considered while annotating. Inter-annotator correlation scores show that the agreement is better when the two annotators consider sentiment information while assigning a similarity score to a pair of words. We use this hypothesis to measure the similarity between a pair of words. Specifically, we represent each word as a vector containing sentiment scores of all the content words in the WordNet gloss of the sense of that word. These sentiment scores are derived from a sentiment lexicon. We then measure the cosine similarity between the two vectors. We perform both intrinsic and extrinsic evaluation of SenSim and compare the performance with other widely usedWordNet similarity metrics.
* The paper is available at http://subhabrata-mukherjee.webs.com/publications.htm