 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetropolis-Hastings algorithm in joint-attention naming game: Experimental semiotics study
May 31, 2023In this study, we explore the emergence of symbols during interactions between individuals through an experimental semiotic study. Previous studies investigate how humans organize symbol systems through communication using artificially designed subjective experiments. In this study, we have focused on a joint attention-naming game (JA-NG) in which participants independently categorize objects and assign names while assuming their joint attention. In the theory of the Metropolis-Hastings naming game (MHNG), listeners accept provided names according to the acceptance probability computed using the Metropolis-Hastings (MH) algorithm. The theory of MHNG suggests that symbols emerge as an approximate decentralized Bayesian inference of signs, which is represented as a shared prior variable if the conditions of MHNG are satisfied. This study examines whether human participants exhibit behavior consistent with MHNG theory when playing JA-NG. By comparing human acceptance decisions of a partner's naming with acceptance probabilities computed in the MHNG, we tested whether human behavior is consistent with the MHNG theory. The main contributions of this study are twofold. First, we reject the null hypothesis that humans make acceptance judgments with a constant probability, regardless of the acceptance probability calculated by the MH algorithm. This result suggests that people followed the acceptance probability computed by the MH algorithm to some extent. Second, the MH-based model predicted human acceptance/rejection behavior more accurately than the other four models: Constant, Numerator, Subtraction, and Binary. This result indicates that symbol emergence in JA-NG can be explained using MHNG and is considered an approximate decentralized Bayesian inference.
Recursive Metropolis-Hastings Naming Game: Symbol Emergence in a Multi-agent System based on Probabilistic Generative Models
May 31, 2023



In the studies on symbol emergence and emergent communication in a population of agents, a computational model was employed in which agents participate in various language games. Among these, the Metropolis-Hastings naming game (MHNG) possesses a notable mathematical property: symbol emergence through MHNG is proven to be a decentralized Bayesian inference of representations shared by the agents. However, the previously proposed MHNG is limited to a two-agent scenario. This paper extends MHNG to an N-agent scenario. The main contributions of this paper are twofold: (1) we propose the recursive Metropolis-Hastings naming game (RMHNG) as an N-agent version of MHNG and demonstrate that RMHNG is an approximate Bayesian inference method for the posterior distribution over a latent variable shared by agents, similar to MHNG; and (2) we empirically evaluate the performance of RMHNG on synthetic and real image data, enabling multiple agents to develop and share a symbol system. Furthermore, we introduce two types of approximations -- one-sample and limited-length -- to reduce computational complexity while maintaining the ability to explain communication in a population of agents. The experimental findings showcased the efficacy of RMHNG as a decentralized Bayesian inference for approximating the posterior distribution concerning latent variables, which are jointly shared among agents, akin to MHNG. Moreover, the utilization of RMHNG elucidated the agents' capacity to exchange symbols. Furthermore, the study discovered that even the computationally simplified version of RMHNG could enable symbols to emerge among the agents.
Active Exploration based on Information Gain by Particle Filter for Efficient Spatial Concept Formation
Nov 20, 2022Autonomous robots are required to actively and adaptively learn the categories and words of various places by exploring the surrounding environment and interacting with users. In semantic mapping and spatial language acquisition conducted using robots, it is costly and labor-intensive to prepare training datasets that contain linguistic instructions from users. Therefore, we aimed to enable mobile robots to learn spatial concepts through autonomous active exploration. This study is characterized by interpreting the `action' of the robot that asks the user the question `What kind of place is this?' in the context of active inference. We propose an active inference method, spatial concept formation with information gain-based active exploration (SpCoAE), that combines sequential Bayesian inference by particle filters and position determination based on information gain in a probabilistic generative model. Our experiment shows that the proposed method can efficiently determine a position to form appropriate spatial concepts in home environments. In particular, it is important to conduct efficient exploration that leads to appropriate concept formation and quickly covers the environment without adopting a haphazard exploration strategy.
Brain-inspired probabilistic generative model for double articulation analysis of spoken language
Jul 06, 2022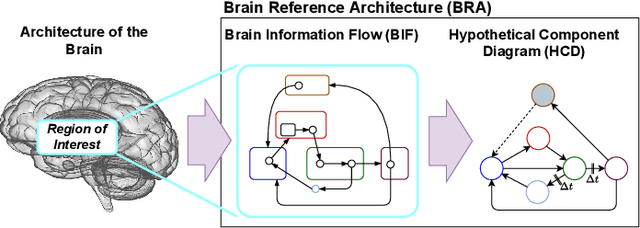
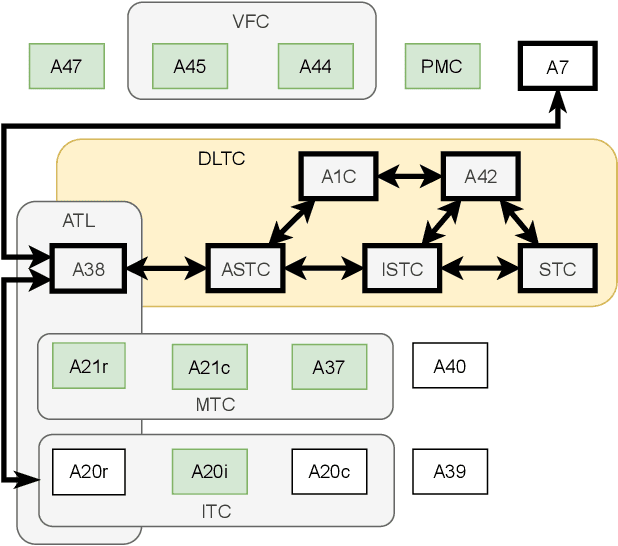
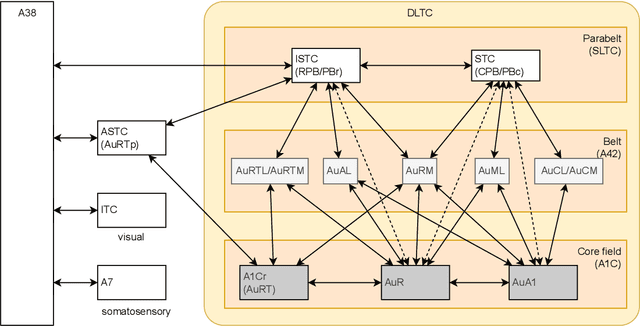
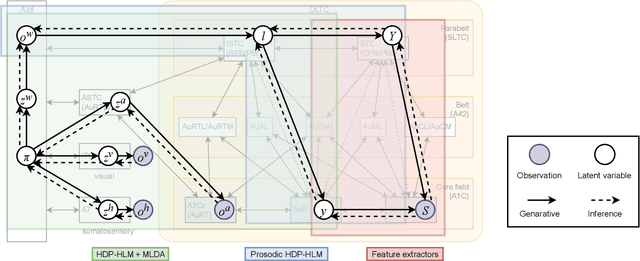
The human brain, among its several functions, analyzes the double articulation structure in spoken language, i.e., double articulation analysis (DAA). A hierarchical structure in which words are connected to form a sentence and words are composed of phonemes or syllables is called a double articulation structure. Where and how DAA is performed in the human brain has not been established, although some insights have been obtained. In addition, existing computational models based on a probabilistic generative model (PGM) do not incorporate neuroscientific findings, and their consistency with the brain has not been previously discussed. This study compared, mapped, and integrated these existing computational models with neuroscientific findings to bridge this gap, and the findings are relevant for future applications and further research. This study proposes a PGM for a DAA hypothesis that can be realized in the brain based on the outcomes of several neuroscientific surveys. The study involved (i) investigation and organization of anatomical structures related to spoken language processing, and (ii) design of a PGM that matches the anatomy and functions of the region of interest. Therefore, this study provides novel insights that will be foundational to further exploring DAA in the brain.
Symbol Emergence as Inter-personal Categorization with Head-to-head Latent Word
May 24, 2022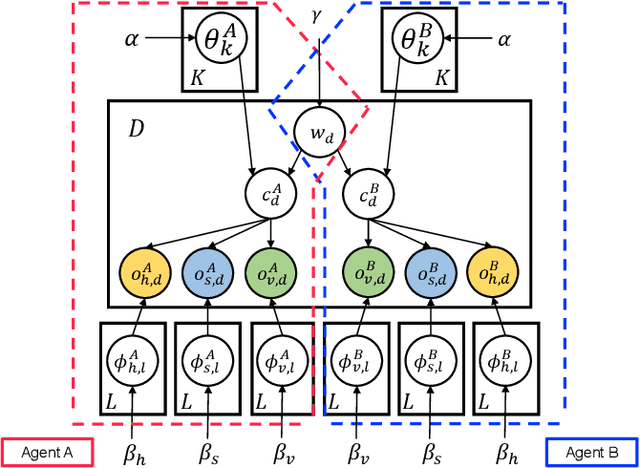
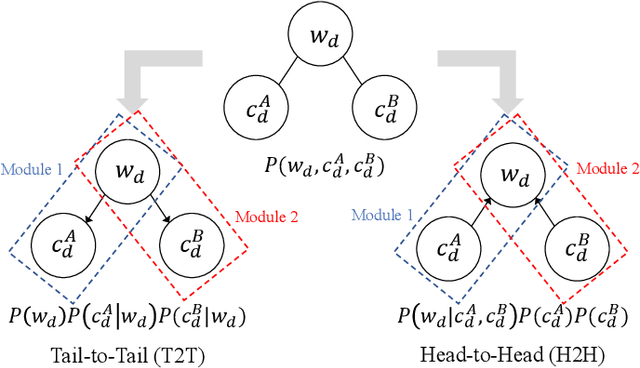
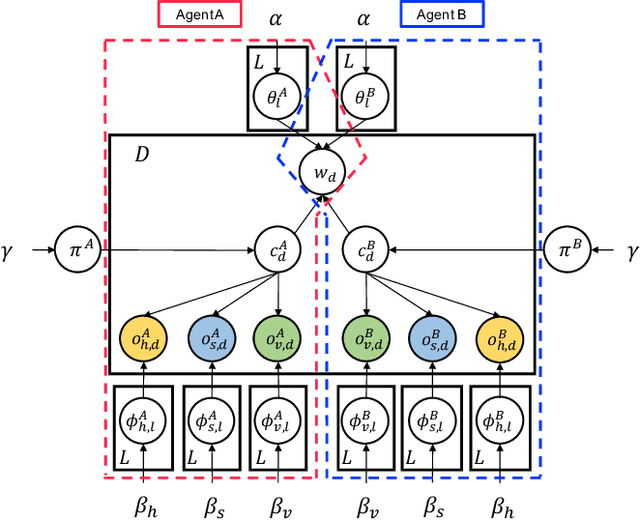
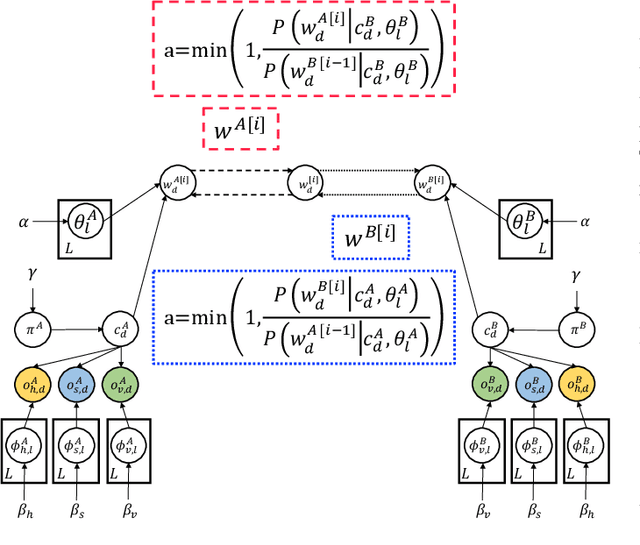
In this study, we propose a head-to-head type (H2H-type) inter-personal multimodal Dirichlet mixture (Inter-MDM) by modifying the original Inter-MDM, which is a probabilistic generative model that represents the symbol emergence between two agents as multiagent multimodal categorization. A Metropolis--Hastings method-based naming game based on the Inter-MDM enables two agents to collaboratively perform multimodal categorization and share signs with a solid mathematical foundation of convergence. However, the conventional Inter-MDM presumes a tail-to-tail connection across a latent word variable, causing inflexibility of the further extension of Inter-MDM for modeling a more complex symbol emergence. Therefore, we propose herein a head-to-head type (H2H-type) Inter-MDM that treats a latent word variable as a child node of an internal variable of each agent in the same way as many prior studies of multimodal categorization. On the basis of the H2H-type Inter-MDM, we propose a naming game in the same way as the conventional Inter-MDM. The experimental results show that the H2H-type Inter-MDM yields almost the same performance as the conventional Inter-MDM from the viewpoint of multimodal categorization and sign sharing.
Emergent Communication through Metropolis-Hastings Naming Game with Deep Generative Models
May 24, 2022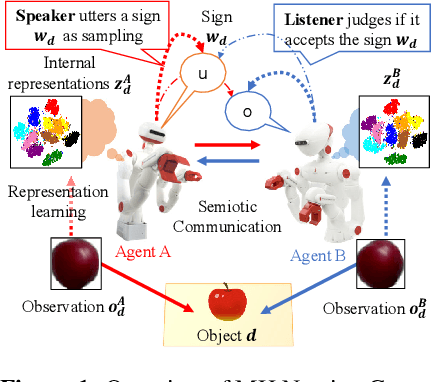
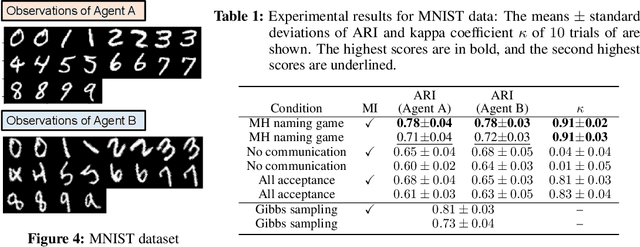
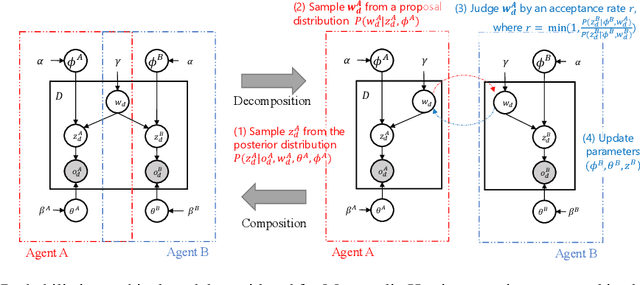
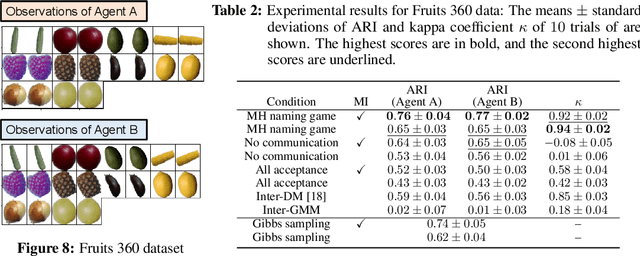
Emergent communication, also known as symbol emergence, seeks to investigate computational models that can better explain human language evolution and the creation of symbol systems. This study aims to provide a new model for emergent communication, which is based on a probabilistic generative model. We define the Metropolis-Hastings (MH) naming game by generalizing a model proposed by Hagiwara et al. \cite{hagiwara2019symbol}. The MH naming game is a sort of MH algorithm for an integrative probabilistic generative model that combines two agents playing the naming game. From this viewpoint, symbol emergence is regarded as decentralized Bayesian inference, and semiotic communication is regarded as inter-personal cross-modal inference. We also offer Inter-GMM+VAE, a deep generative model for simulating emergent communication, in which two agents create internal representations and categories and share signs (i.e., names of objects) from raw visual images observed from different viewpoints. The model has been validated on MNIST and Fruits 360 datasets. Experiment findings show that categories are formed from real images observed by agents, and signs are correctly shared across agents by successfully utilizing both of the agents' views via the MH naming game. Furthermore, it has been verified that the visual images were recalled from the signs uttered by the agents. Notably, emergent communication without supervision and reward feedback improved the performance of unsupervised representation learning.
Spatial Concept-based Topometric Semantic Mapping for Hierarchical Path-planning from Speech Instructions
Mar 21, 2022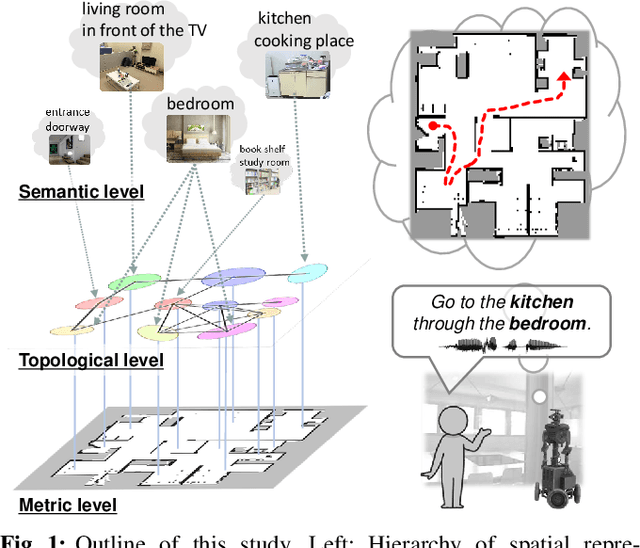
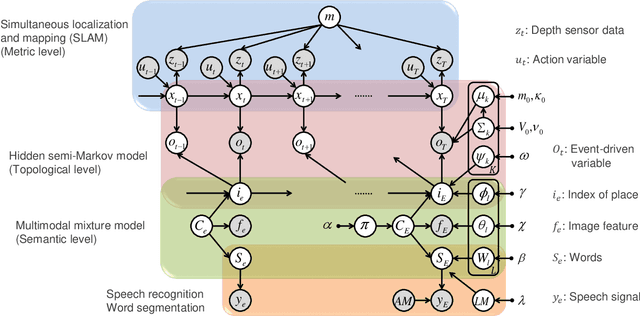
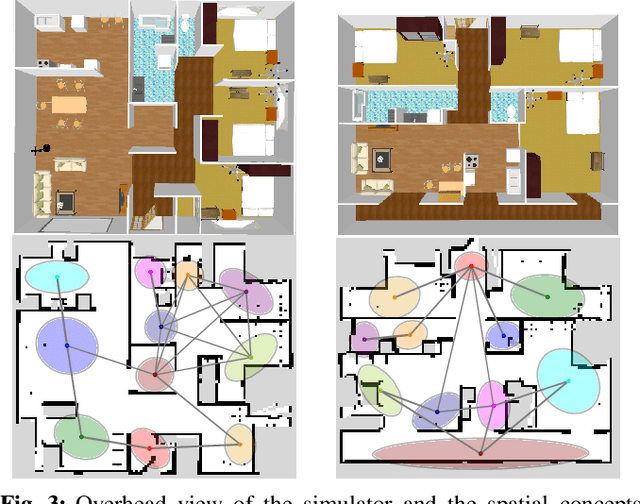
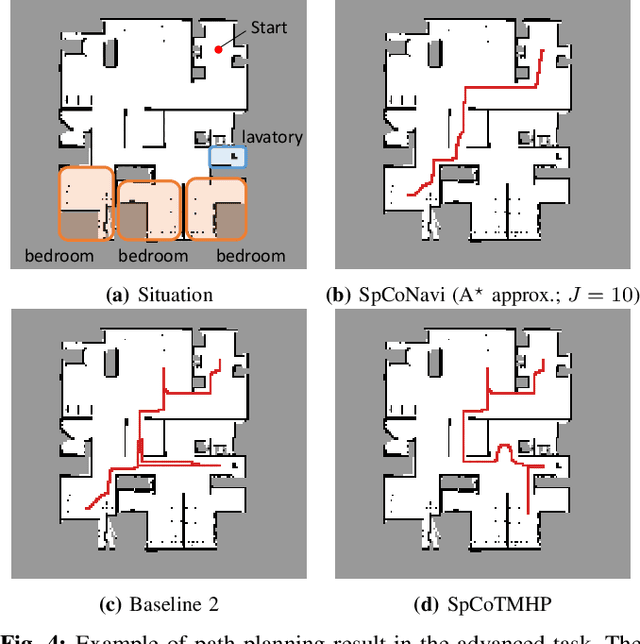
Navigating to destinations using human speech instructions is an important task for autonomous mobile robots that operate in the real world. Spatial representations include a semantic level that represents an abstracted location category, a topological level that represents their connectivity, and a metric level that depends on the structure of the environment. The purpose of this study is to realize a hierarchical spatial representation using a topometric semantic map and planning efficient paths through human-robot interactions. We propose a novel probabilistic generative model, SpCoTMHP, that forms a topometric semantic map that adapts to the environment and leads to hierarchical path planning. We also developed approximate inference methods for path planning, where the levels of the hierarchy can influence each other. The proposed path planning method is theoretically supported by deriving a formulation based on control as probabilistic inference. The navigation experiment using human speech instruction shows that the proposed spatial concept-based hierarchical path planning improves the performance and reduces the calculation cost compared with conventional methods. Hierarchical spatial representation provides a mutually understandable form for humans and robots to render language-based navigation tasks feasible.
Unsupervised Multimodal Word Discovery based on Double Articulation Analysis with Co-occurrence cues
Jan 18, 2022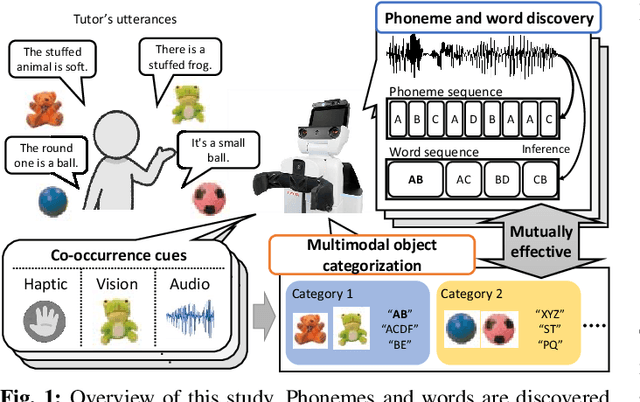
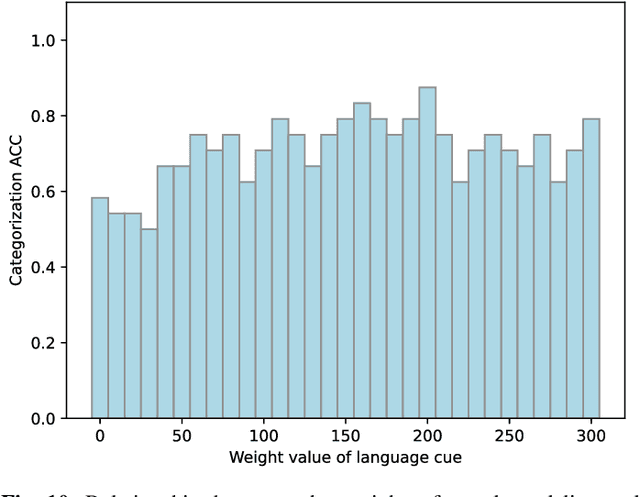
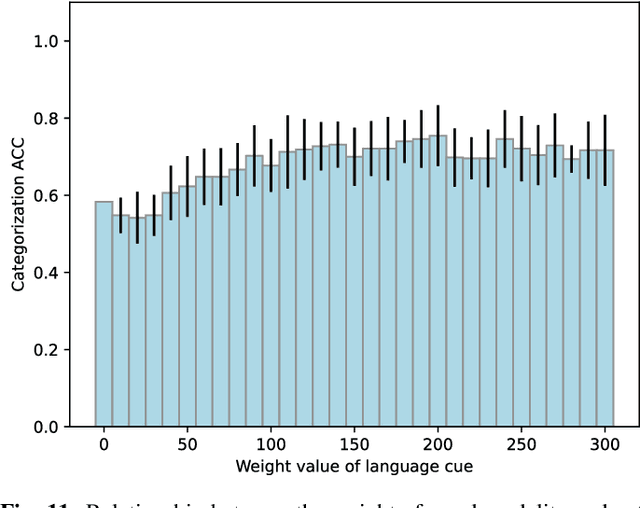
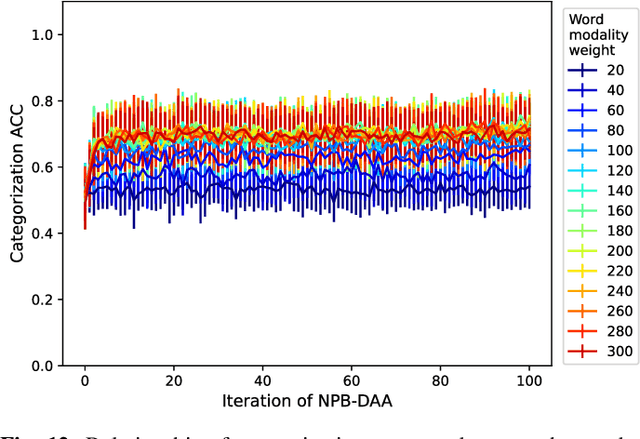
Human infants acquire their verbal lexicon from minimal prior knowledge of language based on the statistical properties of phonological distributions and the co-occurrence of other sensory stimuli. In this study, we propose a novel fully unsupervised learning method discovering speech units by utilizing phonological information as a distributional cue and object information as a co-occurrence cue. The proposed method can not only (1) acquire words and phonemes from speech signals using unsupervised learning, but can also (2) utilize object information based on multiple modalities (i.e., vision, tactile, and auditory) simultaneously. The proposed method is based on the Nonparametric Bayesian Double Articulation Analyzer (NPB-DAA) discovering phonemes and words from phonological features, and Multimodal Latent Dirichlet Allocation (MLDA) categorizing multimodal information obtained from objects. In the experiment, the proposed method showed higher word discovery performance than the baseline methods. In particular, words that expressed the characteristics of the object (i.e., words corresponding to nouns and adjectives) were segmented accurately. Furthermore, we examined how learning performance is affected by differences in the importance of linguistic information. When the weight of the word modality was increased, the performance was further improved compared to the fixed condition.
Multiagent Multimodal Categorization for Symbol Emergence: Emergent Communication via Interpersonal Cross-modal Inference
Sep 15, 2021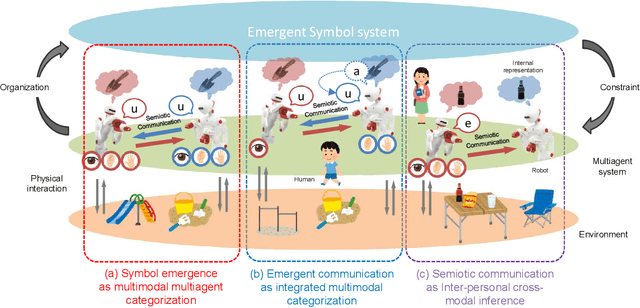
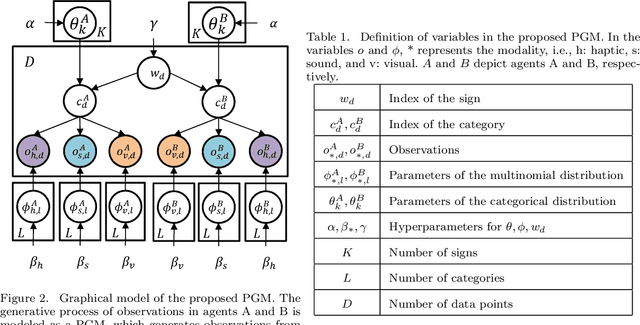
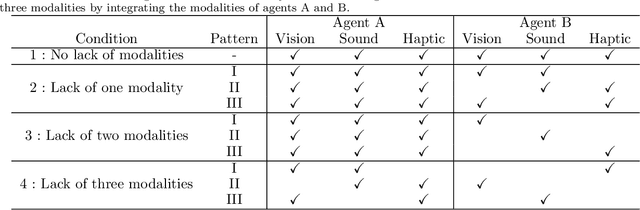
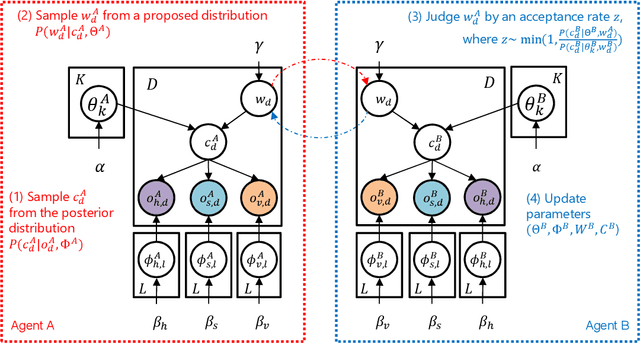
This paper describes a computational model of multiagent multimodal categorization that realizes emergent communication. We clarify whether the computational model can reproduce the following functions in a symbol emergence system, comprising two agents with different sensory modalities playing a naming game. (1) Function for forming a shared lexical system that comprises perceptual categories and corresponding signs, formed by agents through individual learning and semiotic communication between agents. (2) Function to improve the categorization accuracy in an agent via semiotic communication with another agent, even when some sensory modalities of each agent are missing. (3) Function that an agent infers unobserved sensory information based on a sign sampled from another agent in the same manner as cross-modal inference. We propose an interpersonal multimodal Dirichlet mixture (Inter-MDM), which is derived by dividing an integrative probabilistic generative model, which is obtained by integrating two Dirichlet mixtures (DMs). The Markov chain Monte Carlo algorithm realizes emergent communication. The experimental results demonstrated that Inter-MDM enables agents to form multimodal categories and appropriately share signs between agents. It is shown that emergent communication improves categorization accuracy, even when some sensory modalities are missing. Inter-MDM enables an agent to predict unobserved information based on a shared sign.
StarGAN-VC+ASR: StarGAN-based Non-Parallel Voice Conversion Regularized by Automatic Speech Recognition
Aug 10, 2021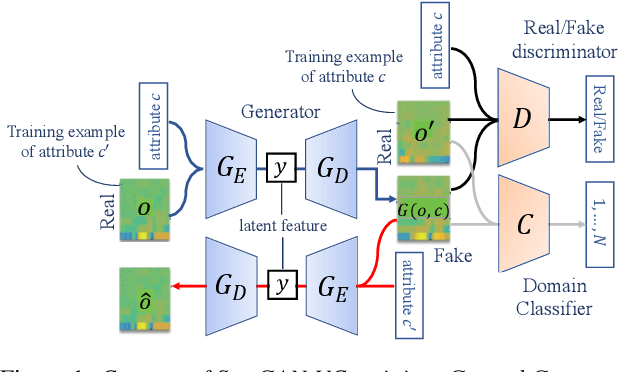
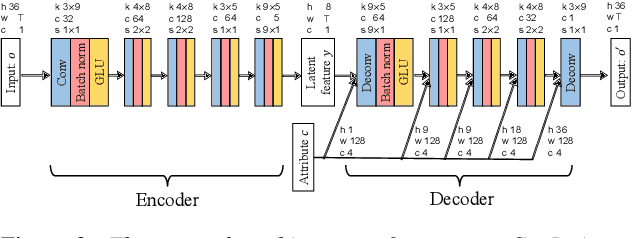
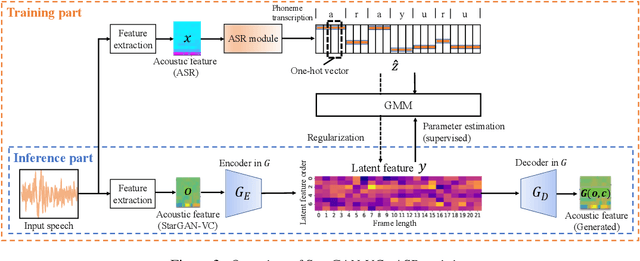
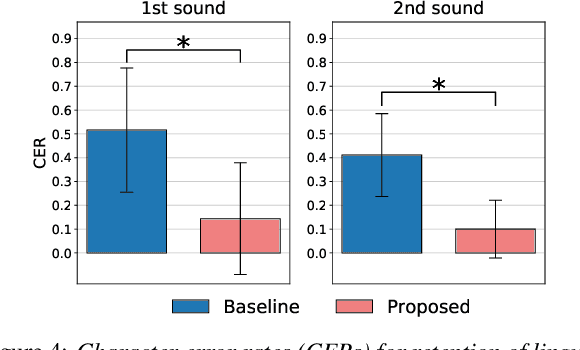
Preserving the linguistic content of input speech is essential during voice conversion (VC). The star generative adversarial network-based VC method (StarGAN-VC) is a recently developed method that allows non-parallel many-to-many VC. Although this method is powerful, it can fail to preserve the linguistic content of input speech when the number of available training samples is extremely small. To overcome this problem, we propose the use of automatic speech recognition to assist model training, to improve StarGAN-VC, especially in low-resource scenarios. Experimental results show that using our proposed method, StarGAN-VC can retain more linguistic information than vanilla StarGAN-VC.