 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassical Machine Learning Baselines for Deepfake Audio Detection on the Fake-or-Real Dataset
Apr 15, 2026Deep learning has enabled highly realistic synthetic speech, raising concerns about fraud, impersonation, and disinformation. Despite rapid progress in neural detectors, transparent baselines are needed to reveal which acoustic cues reliably separate real from synthetic speech. This paper presents an interpretable classical machine learning baseline for deepfake audio detection using the Fake-or-Real (FoR) dataset. We extract prosodic, voice-quality, and spectral features from two-second clips at 44.1 kHz (high-fidelity) and 16 kHz (telephone-quality) sampling rates. Statistical analysis (ANOVA, correlation heatmaps) identifies features that differ significantly between real and fake speech. We then train multiple classifiers -- Logistic Regression, LDA, QDA, Gaussian Naive Bayes, SVMs, and GMMs -- and evaluate performance using accuracy, ROC-AUC, EER, and DET curves. Pairwise McNemar's tests confirm statistically significant differences between models. The best model, an RBF SVM, achieves ~93% test accuracy and ~7% EER on both sampling rates, while linear models reach ~75% accuracy. Feature analysis reveals that pitch variability and spectral richness (spectral centroid, bandwidth) are key discriminative cues. These results provide a strong, interpretable baseline for future deepfake audio detectors.
A Comparative Evaluation of Deep Learning Models for Speech Enhancement in Real-World Noisy Environments
Jun 17, 2025
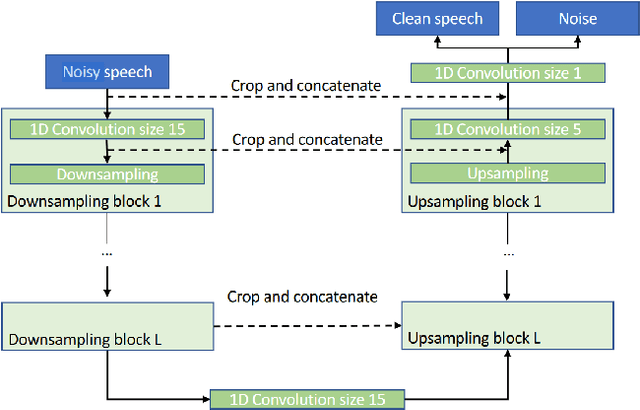

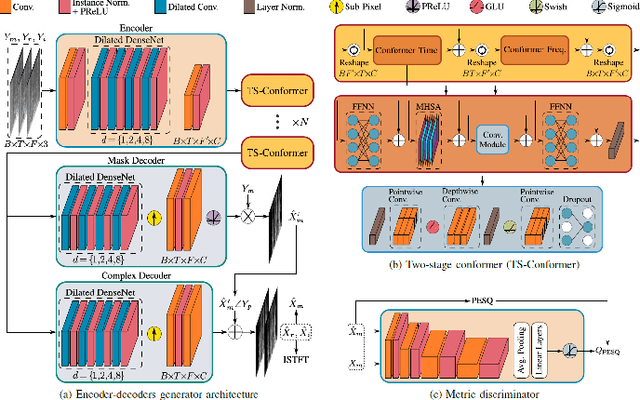
Speech enhancement, particularly denoising, is vital in improving the intelligibility and quality of speech signals for real-world applications, especially in noisy environments. While prior research has introduced various deep learning models for this purpose, many struggle to balance noise suppression, perceptual quality, and speaker-specific feature preservation, leaving a critical research gap in their comparative performance evaluation. This study benchmarks three state-of-the-art models Wave-U-Net, CMGAN, and U-Net, on diverse datasets such as SpEAR, VPQAD, and Clarkson datasets. These models were chosen due to their relevance in the literature and code accessibility. The evaluation reveals that U-Net achieves high noise suppression with SNR improvements of +71.96% on SpEAR, +64.83% on VPQAD, and +364.2% on the Clarkson dataset. CMGAN outperforms in perceptual quality, attaining the highest PESQ scores of 4.04 on SpEAR and 1.46 on VPQAD, making it well-suited for applications prioritizing natural and intelligible speech. Wave-U-Net balances these attributes with improvements in speaker-specific feature retention, evidenced by VeriSpeak score gains of +10.84% on SpEAR and +27.38% on VPQAD. This research indicates how advanced methods can optimize trade-offs between noise suppression, perceptual quality, and speaker recognition. The findings may contribute to advancing voice biometrics, forensic audio analysis, telecommunication, and speaker verification in challenging acoustic conditions.