 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Automated Discovery of Artistic Influence
Aug 14, 2014
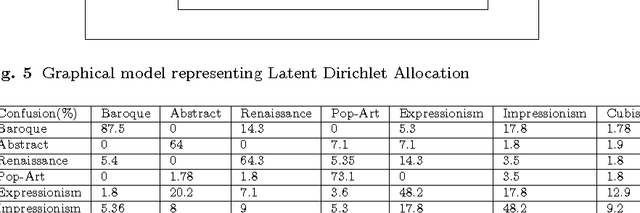

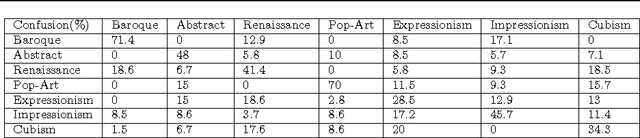
Considering the huge amount of art pieces that exist, there is valuable information to be discovered. Examining a painting, an expert can determine its style, genre, and the time period that the painting belongs. One important task for art historians is to find influences and connections between artists. Is influence a task that a computer can measure? The contribution of this paper is in exploring the problem of computer-automated suggestion of influences between artists, a problem that was not addressed before in a general setting. We first present a comparative study of different classification methodologies for the task of fine-art style classification. A two-level comparative study is performed for this classification problem. The first level reviews the performance of discriminative vs. generative models, while the second level touches the features aspect of the paintings and compares semantic-level features vs. low-level and intermediate-level features present in the painting. Then, we investigate the question "Who influenced this artist?" by looking at his masterpieces and comparing them to others. We pose this interesting question as a knowledge discovery problem. For this purpose, we investigated several painting-similarity and artist-similarity measures. As a result, we provide a visualization of artists (Map of Artists) based on the similarity between their works
Collaborative Discriminant Locality Preserving Projections With its Application to Face Recognition
Feb 08, 2014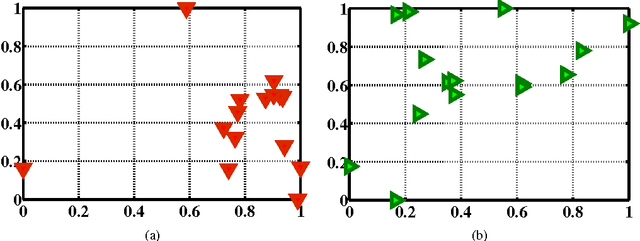
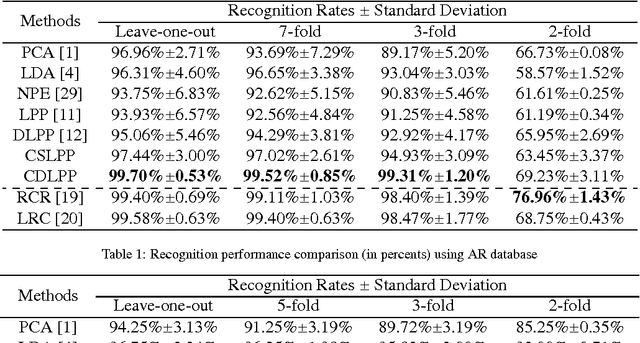

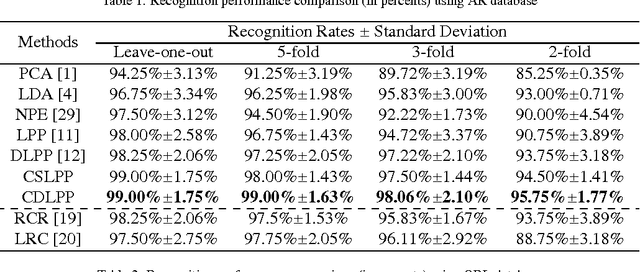
We present a novel Discriminant Locality Preserving Projections (DLPP) algorithm named Collaborative Discriminant Locality Preserving Projection (CDLPP). In our algorithm, the discriminating power of DLPP are further exploited from two aspects. On the one hand, the global optimum of class scattering is guaranteed via using the between-class scatter matrix to replace the original denominator of DLPP. On the other hand, motivated by collaborative representation, an $L_2$-norm constraint is imposed to the projections to discover the collaborations of dimensions in the sample space. We apply our algorithm to face recognition. Three popular face databases, namely AR, ORL and LFW-A, are employed for evaluating the performance of CDLPP. Extensive experimental results demonstrate that CDLPP significantly improves the discriminating power of DLPP and outperforms the state-of-the-arts.
Visual-Semantic Scene Understanding by Sharing Labels in a Context Network
Sep 16, 2013

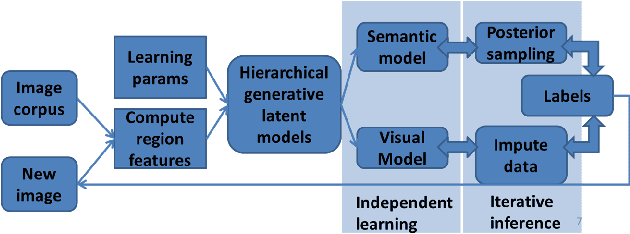

We consider the problem of naming objects in complex, natural scenes containing widely varying object appearance and subtly different names. Informed by cognitive research, we propose an approach based on sharing context based object hypotheses between visual and lexical spaces. To this end, we present the Visual Semantic Integration Model (VSIM) that represents object labels as entities shared between semantic and visual contexts and infers a new image by updating labels through context switching. At the core of VSIM is a semantic Pachinko Allocation Model and a visual nearest neighbor Latent Dirichlet Allocation Model. For inference, we derive an iterative Data Augmentation algorithm that pools the label probabilities and maximizes the joint label posterior of an image. Our model surpasses the performance of state-of-art methods in several visual tasks on the challenging SUN09 dataset.
Learning Hypergraph Labeling for Feature Matching
Jul 13, 2011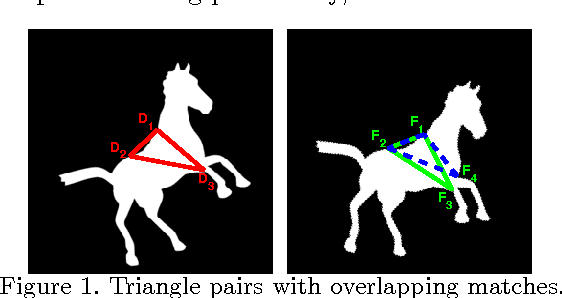
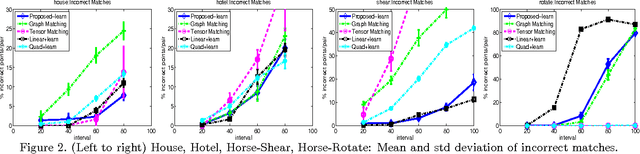

This study poses the feature correspondence problem as a hypergraph node labeling problem. Candidate feature matches and their subsets (usually of size larger than two) are considered to be the nodes and hyperedges of a hypergraph. A hypergraph labeling algorithm, which models the subset-wise interaction by an undirected graphical model, is applied to label the nodes (feature correspondences) as correct or incorrect. We describe a method to learn the cost function of this labeling algorithm from labeled examples using a graphical model training algorithm. The proposed feature matching algorithm is different from the most of the existing learning point matching methods in terms of the form of the objective function, the cost function to be learned and the optimization method applied to minimize it. The results on standard datasets demonstrate how learning over a hypergraph improves the matching performance over existing algorithms, notably one that also uses higher order information without learning.