 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating aggregation strategy selection in federated learning
Apr 09, 2026Federated Learning enables collaborative model training without centralising data, but its effectiveness varies with the selection of the aggregation strategy. This choice is non-trivial, as performance varies widely across datasets, heterogeneity levels, and compute constraints. We present an end-to-end framework that automates, streamlines, and adapts aggregation strategy selection for federated learning. The framework operates in two modes: a single-trial mode, where large language models infer suitable strategies from user-provided or automatically detected data characteristics, and a multi-trial mode, where a lightweight genetic search efficiently explores alternatives under constrained budgets. Extensive experiments across diverse datasets show that our approach enhances robustness and generalisation under non-IID conditions while reducing the need for manual intervention. Overall, this work advances towards accessible and adaptive federated learning by automating one of its most critical design decisions, the choice of an aggregation strategy.
A multimodal slice discovery framework for systematic failure detection and explanation in medical image classification
Feb 27, 2026Despite advances in machine learning-based medical image classifiers, the safety and reliability of these systems remain major concerns in practical settings. Existing auditing approaches mainly rely on unimodal features or metadata-based subgroup analyses, which are limited in interpretability and often fail to capture hidden systematic failures. To address these limitations, we introduce the first automated auditing framework that extends slice discovery methods to multimodal representations specifically for medical applications. Comprehensive experiments were conducted under common failure scenarios using the MIMIC-CXR-JPG dataset, demonstrating the framework's strong capability in both failure discovery and explanation generation. Our results also show that multimodal information generally allows more comprehensive and effective auditing of classifiers, while unimodal variants beyond image-only inputs exhibit strong potential in scenarios where resources are constrained.
Reducing Textural Bias Improves Robustness of Deep Segmentation CNNs
Nov 30, 2020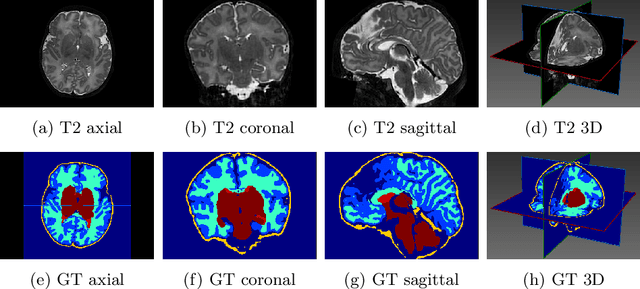

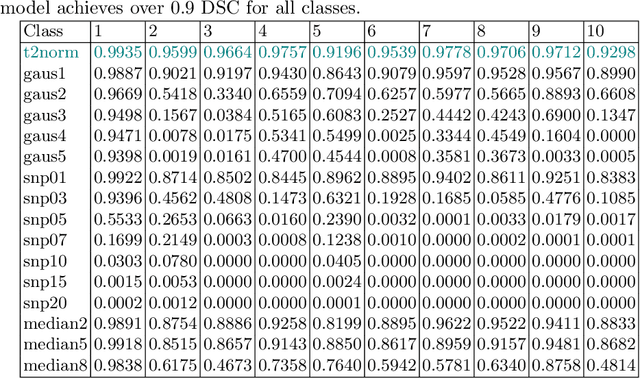
Despite current advances in deep learning, domain shift remains a common problem in medical imaging settings. Recent findings on natural images suggest that deep neural models can show a textural bias when carrying out image classification tasks, which goes against the common understanding of convolutional neural networks (CNNs) recognising objects through increasingly complex representations of shape. This study draws inspiration from recent findings on natural images and aims to investigate ways in which addressing the textural bias phenomenon could be used to bring up the robustness and transferability of deep segmentation models when applied to three-dimensional (3D) medical data. To achieve this, publicly available MRI scans from the Developing Human Connectome Project are used to investigate ways in which simulating textural noise can help train robust models in a complex segmentation task. Our findings illustrate how applying specific types of textural filters prior to training the models can increase their ability to segment scans corrupted by previously unseen noise.