 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAU-R1: Visual Language Model for Traffic Anomaly Understanding
Mar 19, 2026Traffic Anomaly Understanding (TAU) is important for traffic safety in Intelligent Transportation Systems. Recent vision-language models (VLMs) have shown strong capabilities in video understanding. However, progress on TAU remains limited due to the lack of benchmarks and task-specific methodologies. To address this limitation, we introduce Roundabout-TAU, a dataset constructed from real-world roundabout videos collected in collaboration with the City of Carmel, Indiana. The dataset contains 342 clips and is annotated with more than 2,000 question-answer pairs covering multiple aspects of traffic anomaly understanding. Building on this benchmark, we propose TAU-R1, a two-layer vision-language framework for TAU. The first layer is a lightweight anomaly classifier that performs coarse anomaly categorisation, while the second layer is a larger anomaly reasoner that generates detailed event summaries. To improve task-specific reasoning, we introduce a two-stage training strategy consisting of decomposed-QA-enhanced supervised fine-tuning followed by TAU-GRPO, a GRPO-based post-training method with TAU-specific reward functions. Experimental results show that TAU-R1 achieves strong performance on both anomaly classification and reasoning tasks while maintaining deployment efficiency. The dataset and code are available at: https://github.com/siri-rouser/TAU-R1
SAE-MCVT: A Real-Time and Scalable Multi-Camera Vehicle Tracking Framework Powered by Edge Computing
Nov 17, 2025In modern Intelligent Transportation Systems (ITS), cameras are a key component due to their ability to provide valuable information for multiple stakeholders. A central task is Multi-Camera Vehicle Tracking (MCVT), which generates vehicle trajectories and enables applications such as anomaly detection, traffic density estimation, and suspect vehicle tracking. However, most existing studies on MCVT emphasize accuracy while overlooking real-time performance and scalability. These two aspects are essential for real-world deployment and become increasingly challenging in city-scale applications as the number of cameras grows. To address this issue, we propose SAE-MCVT, the first scalable real-time MCVT framework. The system includes several edge devices that interact with one central workstation separately. On the edge side, live RTSP video streams are serialized and processed through modules including object detection, object tracking, geo-mapping, and feature extraction. Only lightweight metadata -- vehicle locations and deep appearance features -- are transmitted to the central workstation. On the central side, cross-camera association is calculated under the constraint of spatial-temporal relations between adjacent cameras, which are learned through a self-supervised camera link model. Experiments on the RoundaboutHD dataset show that SAE-MCVT maintains real-time operation on 2K 15 FPS video streams and achieves an IDF1 score of 61.2. To the best of our knowledge, this is the first scalable real-time MCVT framework suitable for city-scale deployment.
Nasal Patches and Curves for Expression-robust 3D Face Recognition
Jan 01, 2019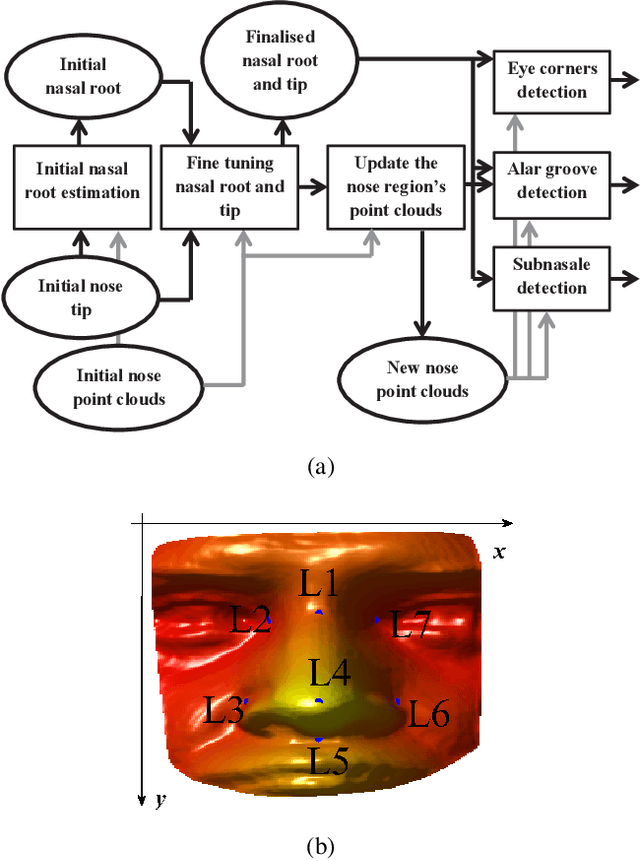
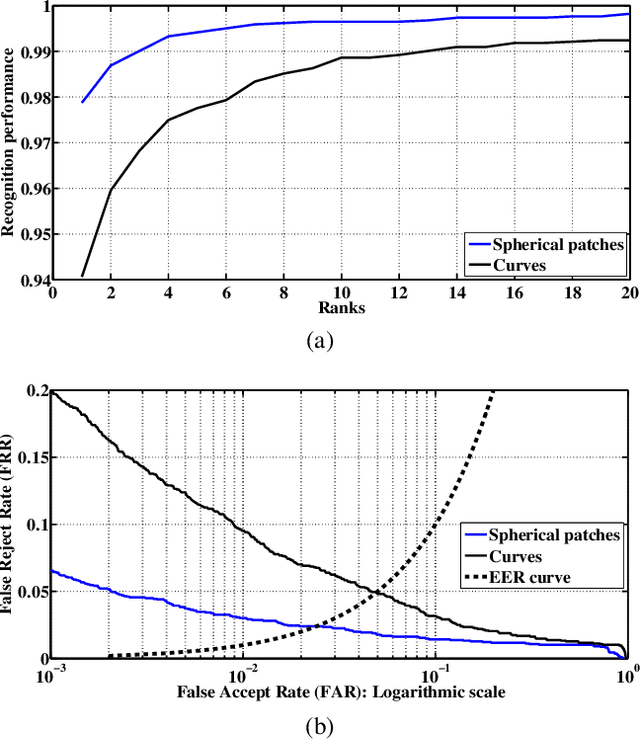
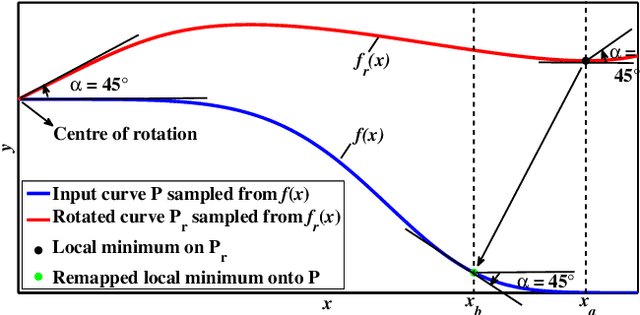
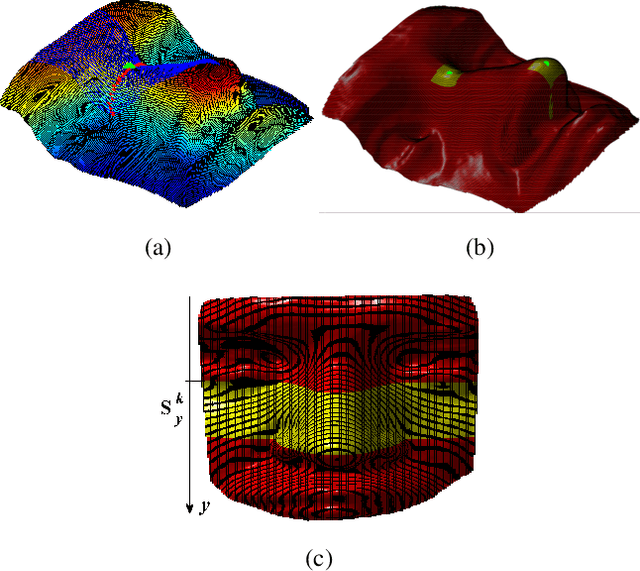
The potential of the nasal region for expression robust 3D face recognition is thoroughly investigated by a novel five-step algorithm. First, the nose tip location is coarsely detected and the face is segmented, aligned and the nasal region cropped. Then, a very accurate and consistent nasal landmarking algorithm detects seven keypoints on the nasal region. In the third step, a feature extraction algorithm based on the surface normals of Gabor-wavelet filtered depth maps is utilised and, then, a set of spherical patches and curves are localised over the nasal region to provide the feature descriptors. The last step applies a genetic algorithm-based feature selector to detect the most stable patches and curves over different facial expressions. The algorithm provides the highest reported nasal region-based recognition ranks on the FRGC, Bosphorus and BU-3DFE datasets. The results are comparable with, and in many cases better than, many state-of-the-art 3D face recognition algorithms, which use the whole facial domain. The proposed method does not rely on sophisticated alignment or denoising steps, is very robust when only one sample per subject is used in the gallery, and does not require a training step for the landmarking algorithm. https://github.com/mehryaragha/NoseBiometrics