 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
Oct 06, 2021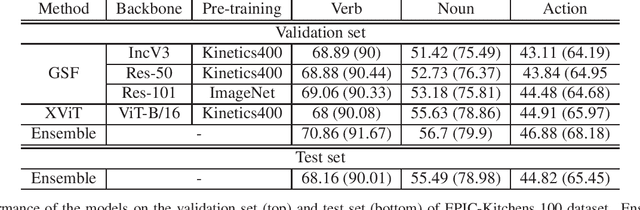
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: GSF and XViT. GSF is an efficient spatio-temporal feature extracting module that can be plugged into 2D CNNs for video action recognition. XViT is a convolution free video feature extractor based on transformer architecture. We design an ensemble of GSF and XViT model families with different backbones and pretraining to generate the prediction scores. Our submission, visible on the public leaderboard, achieved a top-1 action recognition accuracy of 44.82%, using only RGB.
Space-time Mixing Attention for Video Transformer
Jun 11, 2021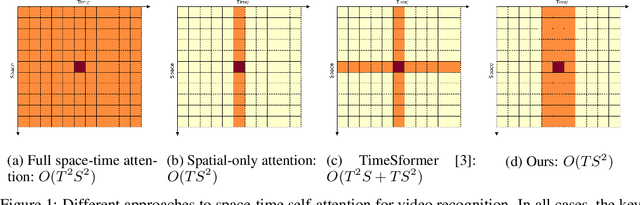
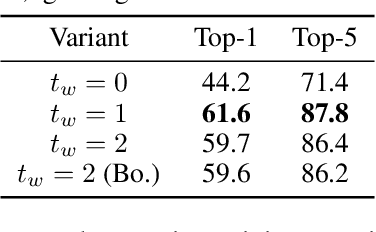
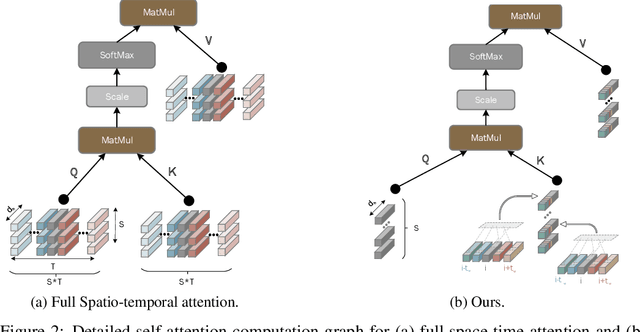
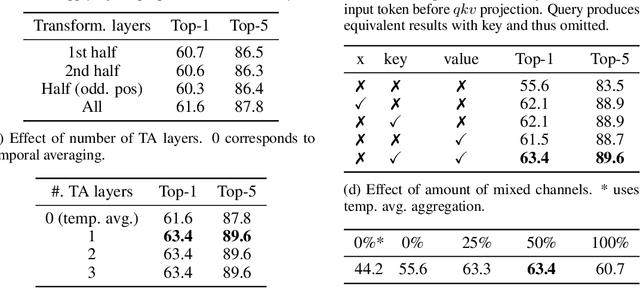
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
Bit-Mixer: Mixed-precision networks with runtime bit-width selection
Mar 31, 2021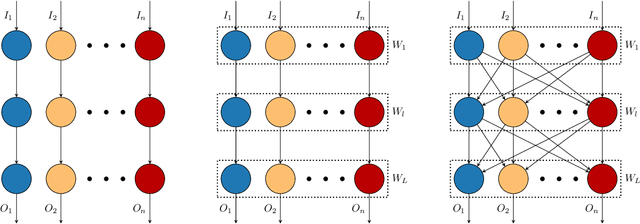

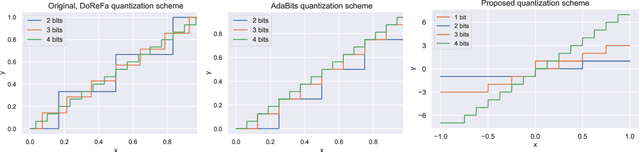
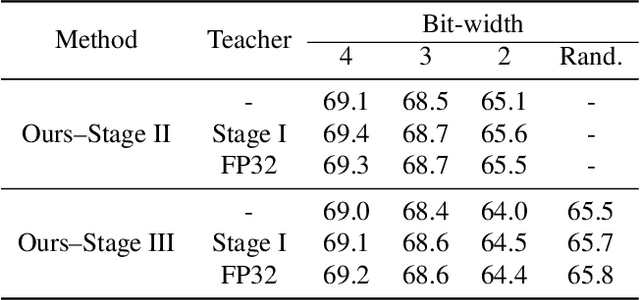
Mixed-precision networks allow for a variable bit-width quantization for every layer in the network. A major limitation of existing work is that the bit-width for each layer must be predefined during training time. This allows little flexibility if the characteristics of the device on which the network is deployed change during runtime. In this work, we propose Bit-Mixer, the very first method to train a meta-quantized network where during test time any layer can change its bid-width without affecting at all the overall network's ability for highly accurate inference. To this end, we make 2 key contributions: (a) Transitional Batch-Norms, and (b) a 3-stage optimization process which is shown capable of training such a network. We show that our method can result in mixed precision networks that exhibit the desirable flexibility properties for on-device deployment without compromising accuracy. Code will be made available.
Pre-training strategies and datasets for facial representation learning
Mar 30, 2021
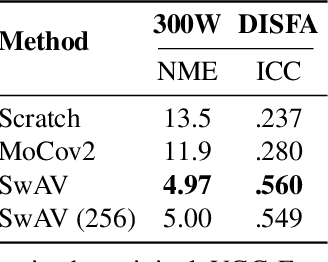
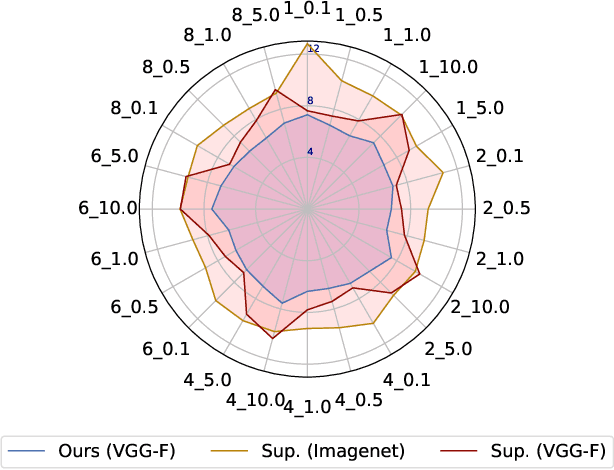
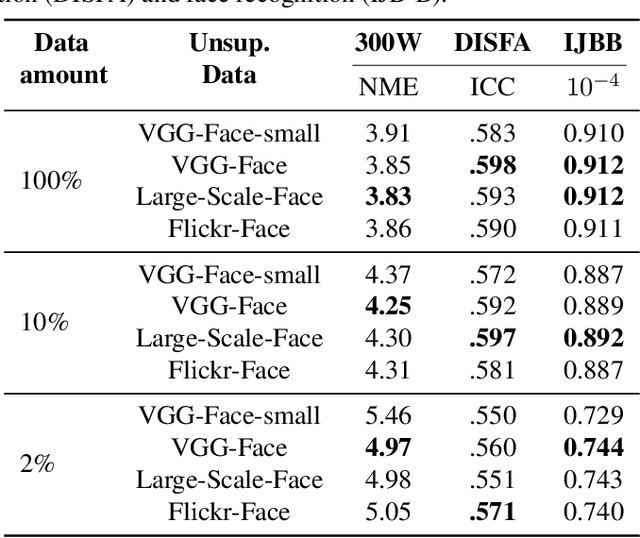
What is the best way to learn a universal face representation? Recent work on Deep Learning in the area of face analysis has focused on supervised learning for specific tasks of interest (e.g. face recognition, facial landmark localization etc.) but has overlooked the overarching question of how to find a facial representation that can be readily adapted to several facial analysis tasks and datasets. To this end, we make the following 4 contributions: (a) we introduce, for the first time, a comprehensive evaluation benchmark for facial representation learning consisting of 5 important face analysis tasks. (b) We systematically investigate two ways of large-scale representation learning applied to faces: supervised and unsupervised pre-training. Importantly, we focus our evaluations on the case of few-shot facial learning. (c) We investigate important properties of the training datasets including their size and quality (labelled, unlabelled or even uncurated). (d) To draw our conclusions, we conducted a very large number of experiments. Our main two findings are: (1) Unsupervised pre-training on completely in-the-wild, uncurated data provides consistent and, in some cases, significant accuracy improvements for all facial tasks considered. (2) Many existing facial video datasets seem to have a large amount of redundancy. We will release code, pre-trained models and data to facilitate future research.
Improving memory banks for unsupervised learning with large mini-batch, consistency and hard negative mining
Feb 08, 2021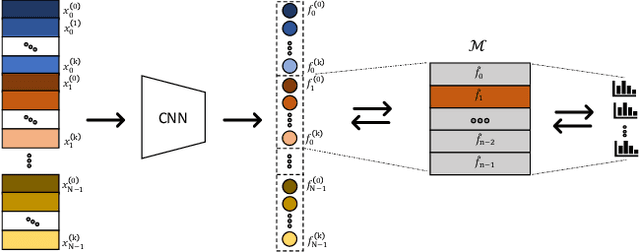
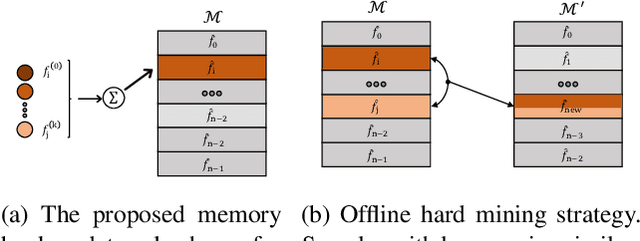


An important component of unsupervised learning by instance-based discrimination is a memory bank for storing a feature representation for each training sample in the dataset. In this paper, we introduce 3 improvements to the vanilla memory bank-based formulation which brings massive accuracy gains: (a) Large mini-batch: we pull multiple augmentations for each sample within the same batch and show that this leads to better models and enhanced memory bank updates. (b) Consistency: we enforce the logits obtained by different augmentations of the same sample to be close without trying to enforce discrimination with respect to negative samples as proposed by previous approaches. (c) Hard negative mining: since instance discrimination is not meaningful for samples that are too visually similar, we devise a novel nearest neighbour approach for improving the memory bank that gradually merges extremely similar data samples that were previously forced to be apart by the instance level classification loss. Overall, our approach greatly improves the vanilla memory-bank based instance discrimination and outperforms all existing methods for both seen and unseen testing categories with cosine similarity.
Semi-supervised Facial Action Unit Intensity Estimation with Contrastive Learning
Nov 04, 2020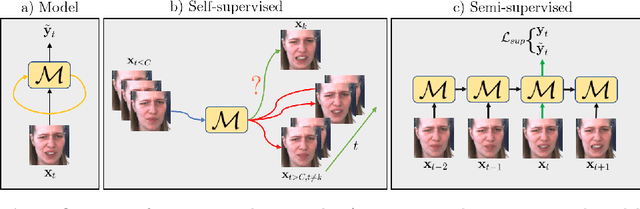
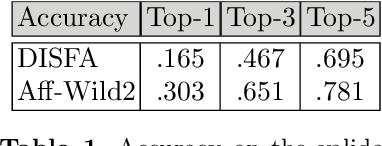
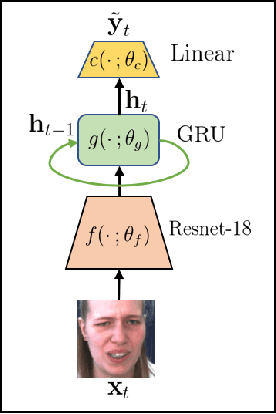
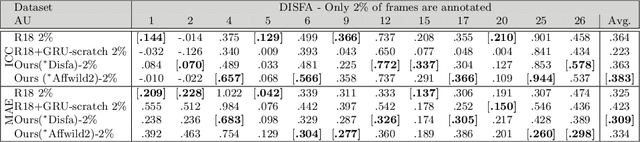
This paper tackles the challenging problem of estimating the intensity of Facial Action Units with few labeled images. Contrary to previous works, our method does not require to manually select key frames, and produces state-of-the-art results with as little as $2\%$ of annotated frames, which are \textit{randomly chosen}. To this end, we propose a semi-supervised learning approach where a spatio-temporal model combining a feature extractor and a temporal module are learned in two stages. The first stage uses datasets of unlabeled videos to learn a strong spatio-temporal representation of facial behavior dynamics based on contrastive learning. To our knowledge we are the first to build upon this framework for modeling facial behavior in an unsupervised manner. The second stage uses another dataset of randomly chosen labeled frames to train a regressor on top of our spatio-temporal model for estimating the AU intensity. We show that although backpropagation through time is applied only with respect to the output of the network for extremely sparse and randomly chosen labeled frames, our model can be effectively trained to estimate AU intensity accurately, thanks to the unsupervised pre-training of the first stage. We experimentally validate that our method outperforms existing methods when working with as little as $2\%$ of randomly chosen data for both DISFA and BP4D datasets, without a careful choice of labeled frames, a time-consuming task still required in previous approaches.
High-Capacity Expert Binary Networks
Oct 07, 2020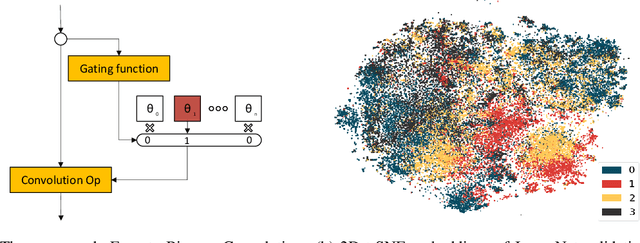
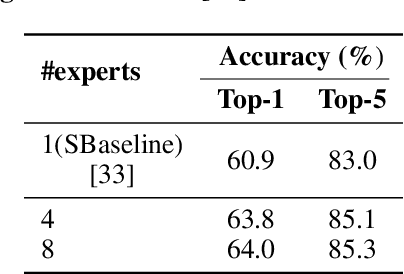
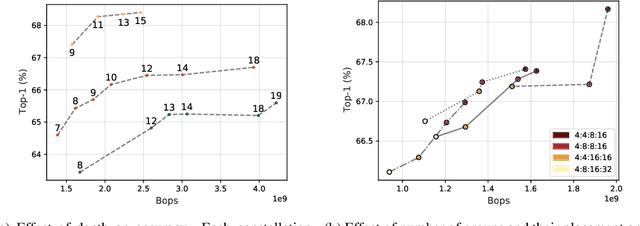
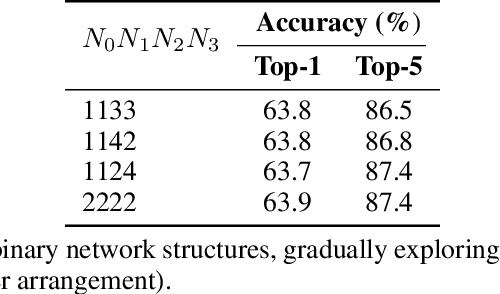
Network binarization is a promising hardware-aware direction for creating efficient deep models. Despite its memory and computational advantages, reducing the accuracy gap between such models and their real-valued counterparts remains an unsolved challenging research problem. To this end, we make the following 3 contributions: (a) To increase model capacity, we propose Expert Binary Convolution, which, for the first time, tailors conditional computing to binary networks by learning to select one data-specific expert binary filter at a time conditioned on input features. (b) To increase representation capacity, we propose to address the inherent information bottleneck in binary networks by introducing an efficient width expansion mechanism which keeps the binary operations within the same budget. (c) To improve network design, we propose a principled binary network growth mechanism that unveils a set of network topologies of favorable properties. Overall, our method improves upon prior work, with no increase in computational cost by ~6%, reaching a groundbreaking ~71% on ImageNet classification.
A Transfer Learning approach to Heatmap Regression for Action Unit intensity estimation
Apr 14, 2020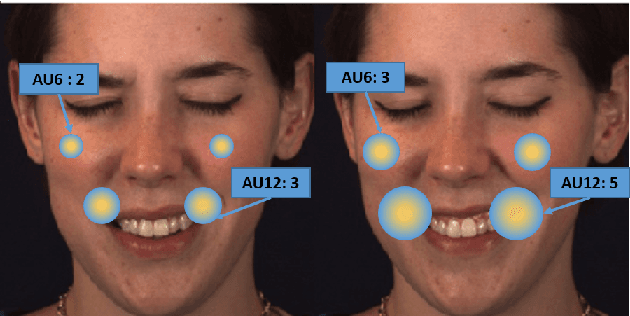
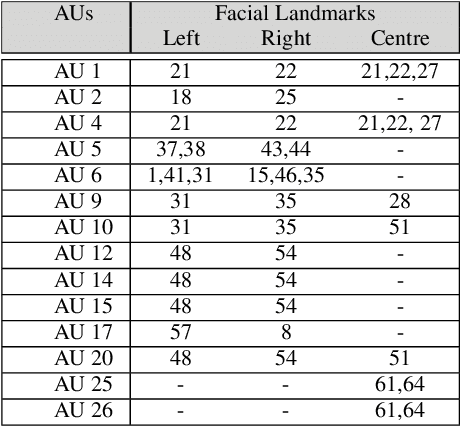
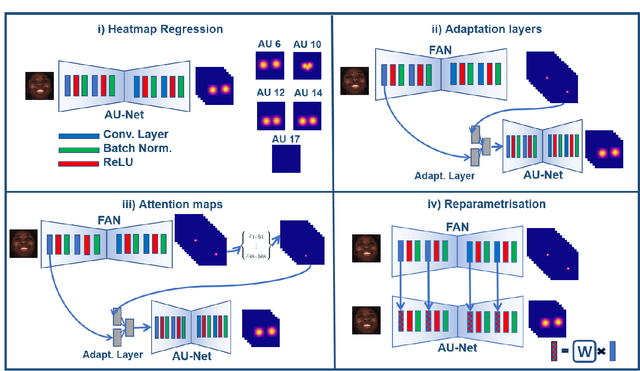
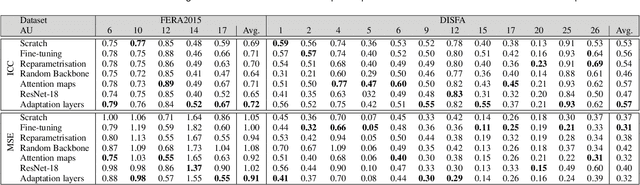
Action Units (AUs) are geometrically-based atomic facial muscle movements known to produce appearance changes at specific facial locations. Motivated by this observation we propose a novel AU modelling problem that consists of jointly estimating their localisation and intensity. To this end, we propose a simple yet efficient approach based on Heatmap Regression that merges both problems into a single task. A Heatmap models whether an AU occurs or not at a given spatial location. To accommodate the joint modelling of AUs intensity, we propose variable size heatmaps, with their amplitude and size varying according to the labelled intensity. Using Heatmap Regression, we can inherit from the progress recently witnessed in facial landmark localisation. Building upon the similarities between both problems, we devise a transfer learning approach where we exploit the knowledge of a network trained on large-scale facial landmark datasets. In particular, we explore different alternatives for transfer learning through a) fine-tuning, b) adaptation layers, c) attention maps, and d) reparametrisation. Our approach effectively inherits the rich facial features produced by a strong face alignment network, with minimal extra computational cost. We empirically validate that our system sets a new state-of-the-art on three popular datasets, namely BP4D, DISFA, and FERA2017.
Training Binary Neural Networks with Real-to-Binary Convolutions
Mar 25, 2020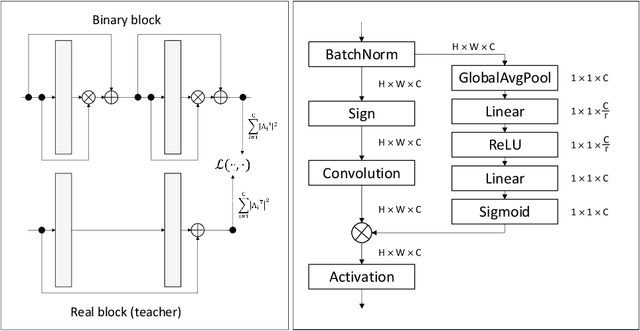
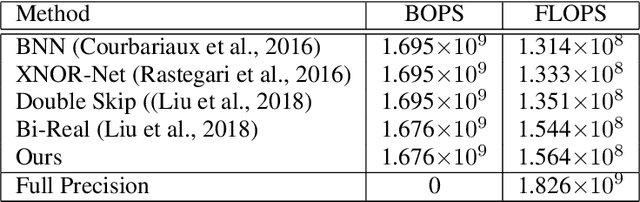
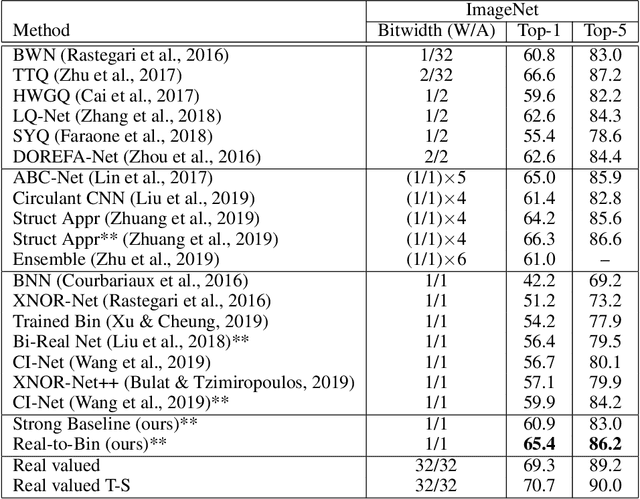
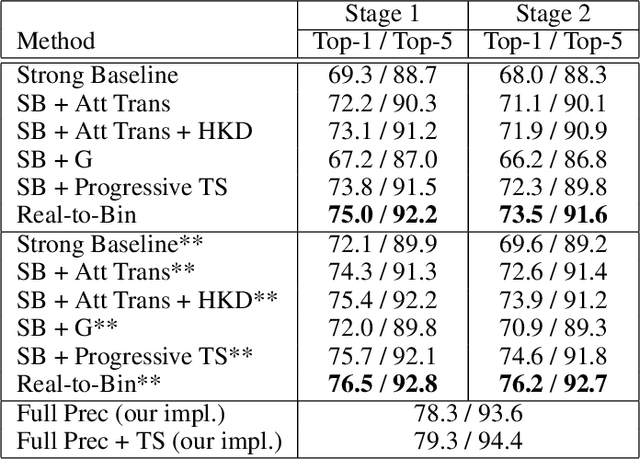
This paper shows how to train binary networks to within a few percent points ($\sim 3-5 \%$) of the full precision counterpart. We first show how to build a strong baseline, which already achieves state-of-the-art accuracy, by combining recently proposed advances and carefully adjusting the optimization procedure. Secondly, we show that by attempting to minimize the discrepancy between the output of the binary and the corresponding real-valued convolution, additional significant accuracy gains can be obtained. We materialize this idea in two complementary ways: (1) with a loss function, during training, by matching the spatial attention maps computed at the output of the binary and real-valued convolutions, and (2) in a data-driven manner, by using the real-valued activations, available during inference prior to the binarization process, for re-scaling the activations right after the binary convolution. Finally, we show that, when putting all of our improvements together, the proposed model beats the current state of the art by more than 5% top-1 accuracy on ImageNet and reduces the gap to its real-valued counterpart to less than 3% and 5% top-1 accuracy on CIFAR-100 and ImageNet respectively when using a ResNet-18 architecture. Code available at https://github.com/brais-martinez/real2binary.
Knowledge distillation via adaptive instance normalization
Mar 09, 2020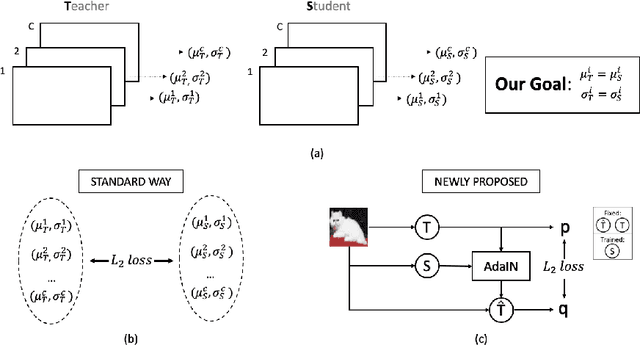
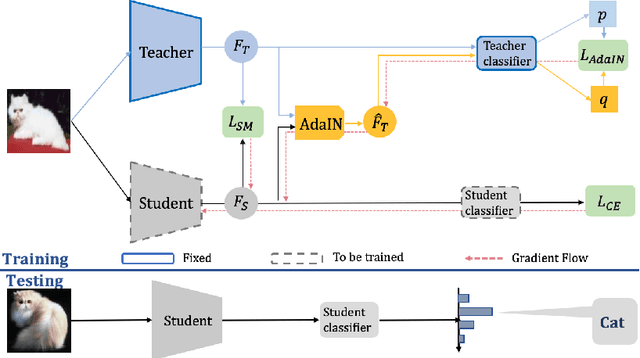
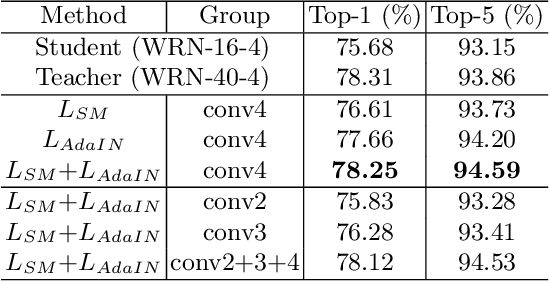
This paper addresses the problem of model compression via knowledge distillation. To this end, we propose a new knowledge distillation method based on transferring feature statistics, specifically the channel-wise mean and variance, from the teacher to the student. Our method goes beyond the standard way of enforcing the mean and variance of the student to be similar to those of the teacher through an $L_2$ loss, which we found it to be of limited effectiveness. Specifically, we propose a new loss based on adaptive instance normalization to effectively transfer the feature statistics. The main idea is to transfer the learned statistics back to the teacher via adaptive instance normalization (conditioned on the student) and let the teacher network "evaluate" via a loss whether the statistics learned by the student are reliably transferred. We show that our distillation method outperforms other state-of-the-art distillation methods over a large set of experimental settings including different (a) network architectures, (b) teacher-student capacities, (c) datasets, and (d) domains.