 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attribute-Based Measure of Video Complexity
May 30, 2026A new framework for the estimation of the complexity posed by video-question pairs to video-LLMs, Video Attribute-Based Complexity (VideoABC), is proposed. Video complexity is defined as the probability of failure of a video-LLM for a given video-question pair. VideoABC is a non-parametric complexity measure, using a reference video dataset and a pre-defined vocabulary of video attributes informative of complexity, \eg the scene complexity or the speed of the video event informative of the question. In a training phase, reference videos are projected into the space of these attributes, which is then quantized. The expected ABC of each quantization cell is then computed. Given a new video and its projection into the attribute space, complexity is estimated by the expected ABC of the associated quantization cell. To enable the use of VideoABC with small reference video datasets, two quantizers are combined: a k-means quantizer that enables accurate complexity estimates for samples in the distribution of the reference dataset and a universal lattice quantizer that guarantees generalization to out-of-distribution samples. A synthetic video generation procedure, inspired by target-distractor manipulations of psychophysics studies, is proposed to populate the cells of the lattice quantizer during training, enabling the computation of their expected ABCs. Experimental results show that VideoABCis effective even with very low-dimensional attribute representations, substantially outperforming approaches like `video-LLM as judge' with much less complexity. Finally, the explainable nature of the VideoABC score, in terms of well-defined attributes, is shown to provide insights on how the attribute composition of benchmarks affects their complexity.
Leveraging Data to Say No: Memory Augmented Plug-and-Play Selective Prediction
Jan 30, 2026Selective prediction aims to endow predictors with a reject option, to avoid low confidence predictions. However, existing literature has primarily focused on closed-set tasks, such as visual question answering with predefined options or fixed-category classification. This paper considers selective prediction for visual language foundation models, addressing a taxonomy of tasks ranging from closed to open set and from finite to unbounded vocabularies, as in image captioning. We seek training-free approaches of low-complexity, applicable to any foundation model and consider methods based on external vision-language model embeddings, like CLIP. This is denoted as Plug-and-Play Selective Prediction (PaPSP). We identify two key challenges: (1) instability of the visual-language representations, leading to high variance in image-text embeddings, and (2) poor calibration of similarity scores. To address these issues, we propose a memory augmented PaPSP (MA-PaPSP) model, which augments PaPSP with a retrieval dataset of image-text pairs. This is leveraged to reduce embedding variance by averaging retrieved nearest-neighbor pairs and is complemented by the use of contrastive normalization to improve score calibration. Through extensive experiments on multiple datasets, we show that MA-PaPSP outperforms PaPSP and other selective prediction baselines for selective captioning, image-text matching, and fine-grained classification. Code is publicly available at https://github.com/kingston-aditya/MA-PaPSP.
Virtual Screening of Pharmaceutical Compounds with hERG Inhibitory Activity (Cardiotoxicity) using Ensemble Learning
Jun 05, 2021
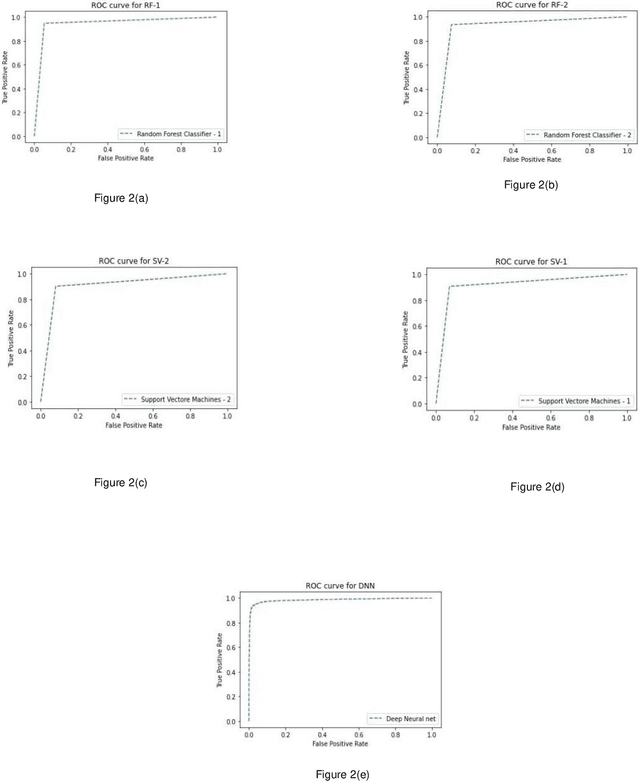
In silico prediction of cardiotoxicity with high sensitivity and specificity for potential drug molecules can be of immense value. Hence, building machine learning classification models, based on some features extracted from the molecular structure of drugs, which are capable of efficiently predicting cardiotoxicity is critical. In this paper, we consider the application of various machine learning approaches, and then propose an ensemble classifier for the prediction of molecular activity on a Drug Discovery Hackathon (DDH) (1st reference) dataset. We have used only 2-D descriptors of SMILE notations for our prediction. Our ensemble classification uses 5 classifiers (2 Random Forest Classifiers, 2 Support Vector Machines and a Dense Neural Network) and uses Max-Voting technique and Weighted-Average technique for final decision.
* 23 pages, 2 figures, 5 tables