 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHATC: Autism Spectrum Disorder identification utilizing multi-head attention encoder along with temporal consolidation modules
Dec 27, 2021
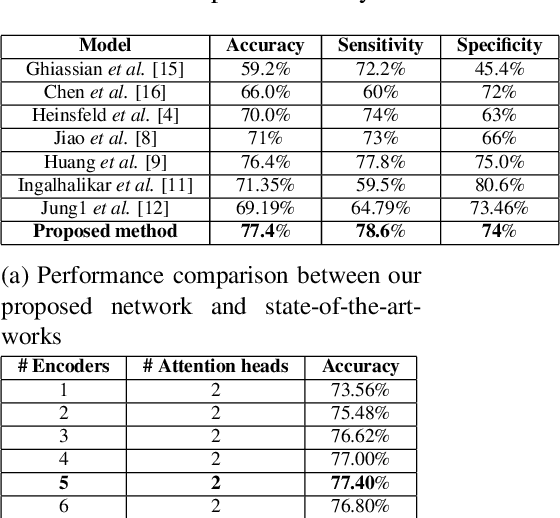
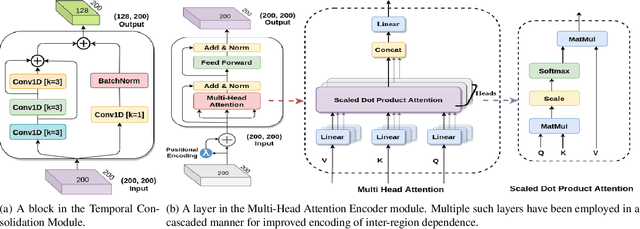
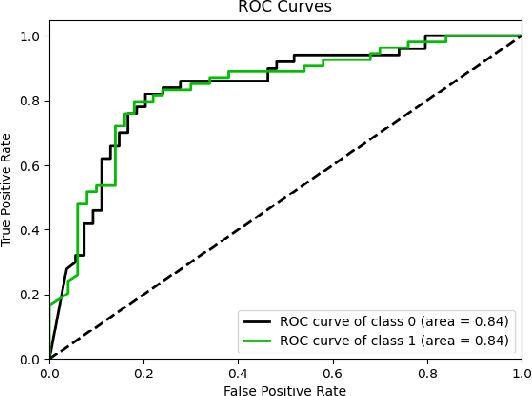
Resting-state fMRI is commonly used for diagnosing Autism Spectrum Disorder (ASD) by using network-based functional connectivity. It has been shown that ASD is associated with brain regions and their inter-connections. However, discriminating based on connectivity patterns among imaging data of the control population and that of ASD patients' brains is a non-trivial task. In order to tackle said classification task, we propose a novel deep learning architecture (MHATC) consisting of multi-head attention and temporal consolidation modules for classifying an individual as a patient of ASD. The devised architecture results from an in-depth analysis of the limitations of current deep neural network solutions for similar applications. Our approach is not only robust but computationally efficient, which can allow its adoption in a variety of other research and clinical settings.
IHashNet: Iris Hashing Network based on efficient multi-index hashing
Dec 07, 2020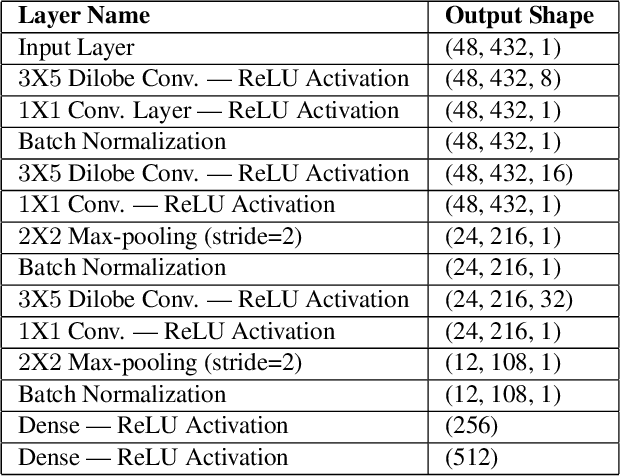
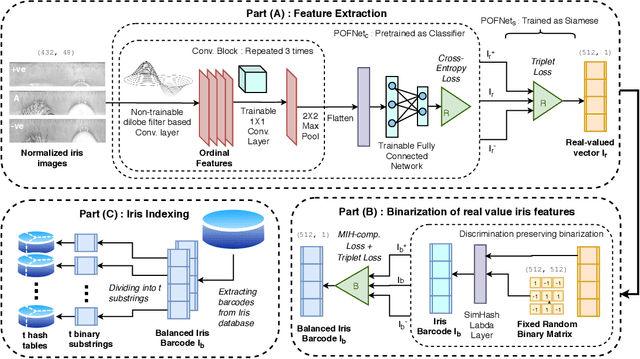
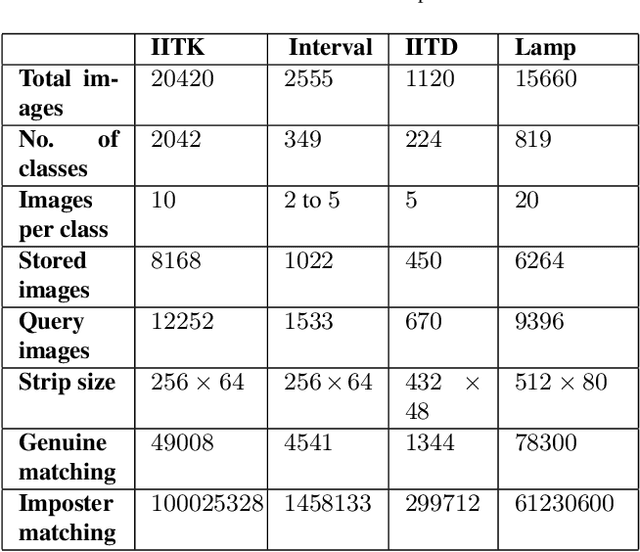
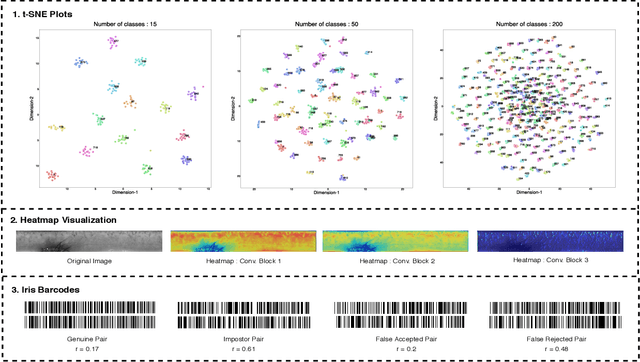
Massive biometric deployments are pervasive in today's world. But despite the high accuracy of biometric systems, their computational efficiency degrades drastically with an increase in the database size. Thus, it is essential to index them. An ideal indexing scheme needs to generate codes that preserve the intra-subject similarity as well as inter-subject dissimilarity. Here, in this paper, we propose an iris indexing scheme using real-valued deep iris features binarized to iris bar codes (IBC) compatible with the indexing structure. Firstly, for extracting robust iris features, we have designed a network utilizing the domain knowledge of ordinal filtering and learning their nonlinear combinations. Later these real-valued features are binarized. Finally, for indexing the iris dataset, we have proposed a loss that can transform the binary feature into an improved feature compatible with the Multi-Index Hashing scheme. This loss function ensures the hamming distance equally distributed among all the contiguous disjoint sub-strings. To the best of our knowledge, this is the first work in the iris indexing domain that presents an end-to-end iris indexing structure. Experimental results on four datasets are presented to depict the efficacy of the proposed approach.
UESegNet: Context Aware Unconstrained ROI Segmentation Networks for Ear Biometric
Oct 08, 2020
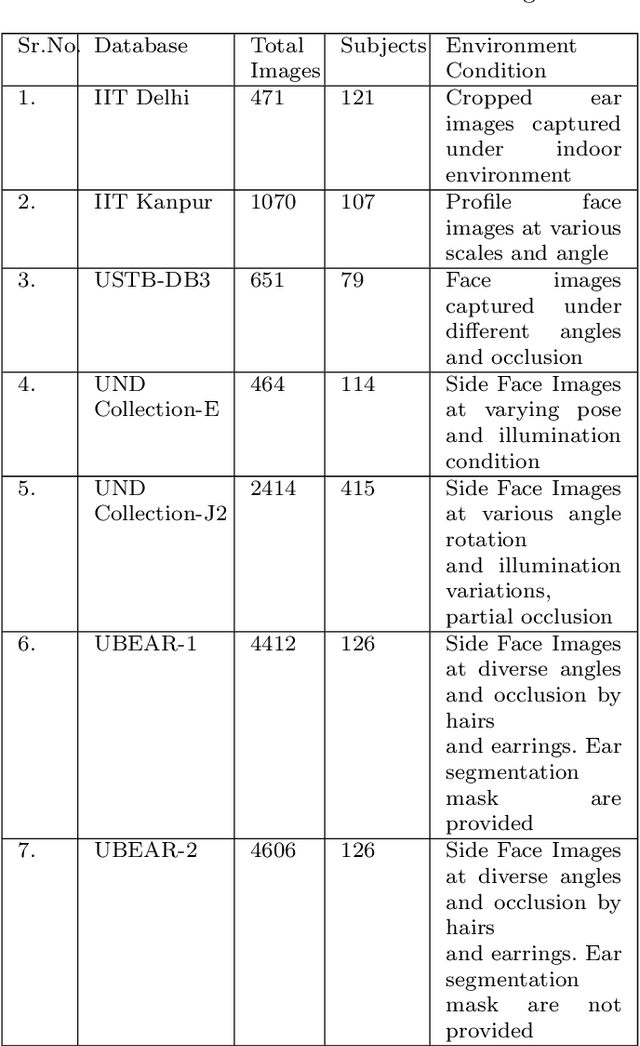
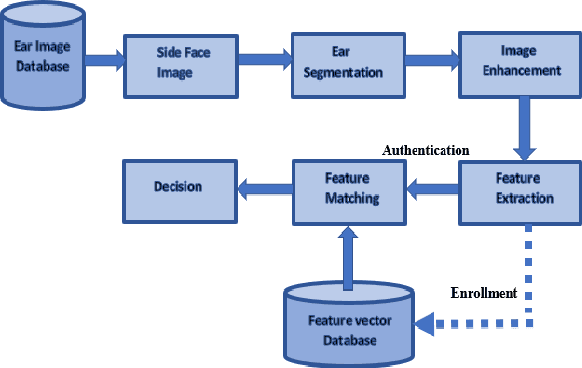
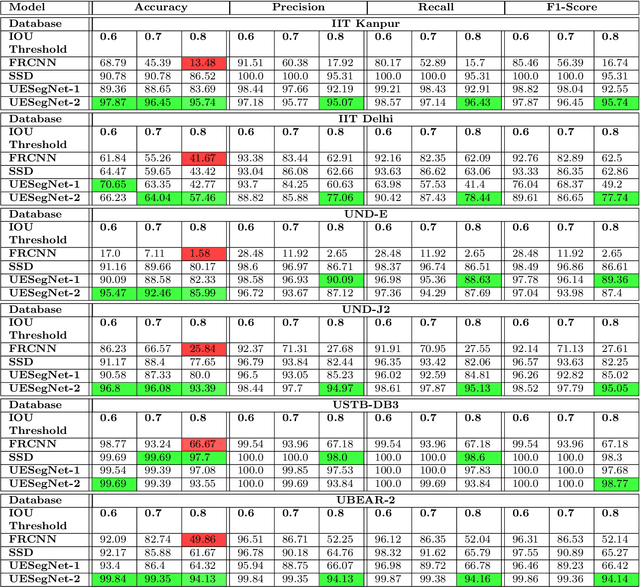
Biometric-based personal authentication systems have seen a strong demand mainly due to the increasing concern in various privacy and security applications. Although the use of each biometric trait is problem dependent, the human ear has been found to have enough discriminating characteristics to allow its use as a strong biometric measure. To locate an ear in a 2D side face image is a challenging task, numerous existing approaches have achieved significant performance, but the majority of studies are based on the constrained environment. However, ear biometrics possess a great level of difficulties in the unconstrained environment, where pose, scale, occlusion, illuminations, background clutter etc. varies to a great extent. To address the problem of ear localization in the wild, we have proposed two high-performance region of interest (ROI) segmentation models UESegNet-1 and UESegNet-2, which are fundamentally based on deep convolutional neural networks and primarily uses contextual information to localize ear in the unconstrained environment. Additionally, we have applied state-of-the-art deep learning models viz; FRCNN (Faster Region Proposal Network) and SSD (Single Shot MultiBox Detecor) for ear localization task. To test the model's generalization, they are evaluated on six different benchmark datasets viz; IITD, IITK, USTB-DB3, UND-E, UND-J2 and UBEAR, all of which contain challenging images. The performance of the models is compared on the basis of object detection performance measure parameters such as IOU (Intersection Over Union), Accuracy, Precision, Recall, and F1-Score. It has been observed that the proposed models UESegNet-1 and UESegNet-2 outperformed the FRCNN and SSD at higher values of IOUs i.e. an accuracy of 100\% is achieved at IOU 0.5 on majority of the databases.
Semantic Features Aided Multi-Scale Reconstruction of Inter-Modality Magnetic Resonance Images
Jun 22, 2020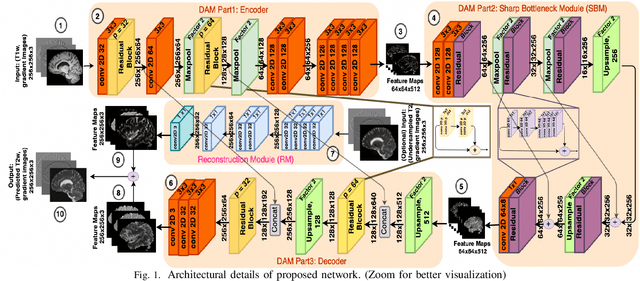
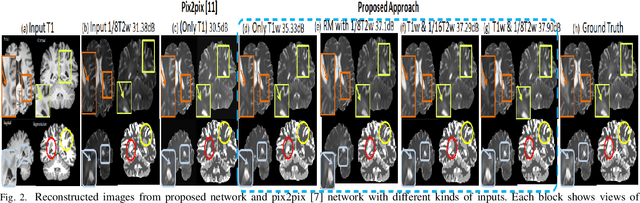
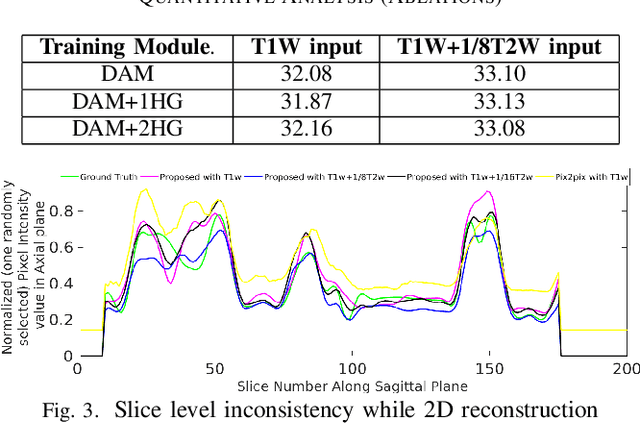

Long acquisition time (AQT) due to series acquisition of multi-modality MR images (especially T2 weighted images (T2WI) with longer AQT), though beneficial for disease diagnosis, is practically undesirable. We propose a novel deep network based solution to reconstruct T2W images from T1W images (T1WI) using an encoder-decoder architecture. The proposed learning is aided with semantic features by using multi-channel input with intensity values and gradient of image in two orthogonal directions. A reconstruction module (RM) augmenting the network along with a domain adaptation module (DAM) which is an encoder-decoder model built-in with sharp bottleneck module (SBM) is trained via modular training. The proposed network significantly reduces the total AQT with negligible qualitative artifacts and quantitative loss (reconstructs one volume in approximately 1 second). The testing is done on publicly available dataset with real MR images, and the proposed network shows (approximately 1dB) increase in PSNR over SOTA.
PoshakNet: Framework for matching dresses from real-life photos using GAN and Siamese Network
Nov 11, 2019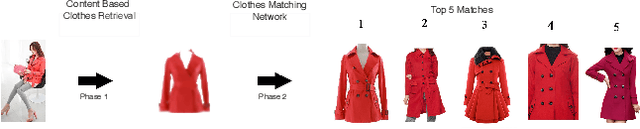
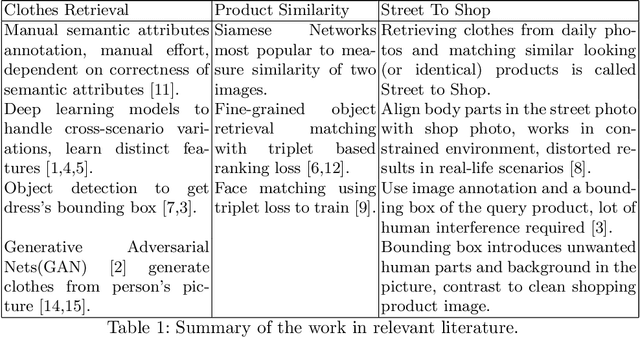

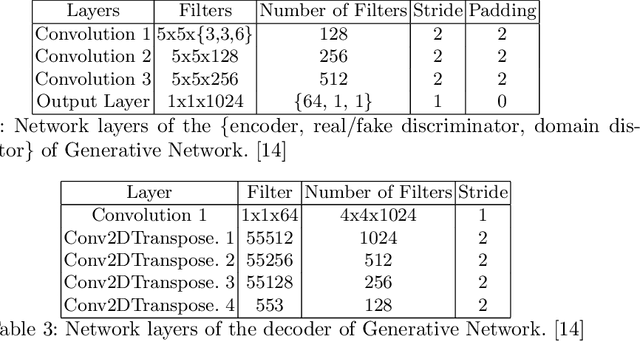
Online garment shopping has gained many customers in recent years. Describing a dress using keywords does not always yield the proper results, which in turn leads to dissatisfaction of customers. A visual search based system will be enormously beneficent to the industry. Hence, we propose a framework that can retrieve similar clothes that can be found in an image. The first task is to extract the garment from the input image (street photo). There are various challenges for that, including pose, illumination, and background clutter. We use a Generative Adversarial Network for the task of retrieving the garment that the person in the image was wearing. It has been shown that GAN can retrieve the garment very efficiently despite the challenges of street photos. Finally, a siamese based matching system takes the retrieved cloth image and matches it with the clothes in the dataset, giving us the top k matches. We take a pre-trained inception-ResNet v1 module as a siamese network (trained using triplet loss for face detection) and fine-tune it on the shopping dataset using center loss. The dataset has been collected inhouse. For training the GAN, we use the LookBook dataset, which is publically available.
SP-NET: One Shot Fingerprint Singular-Point Detector
Aug 13, 2019

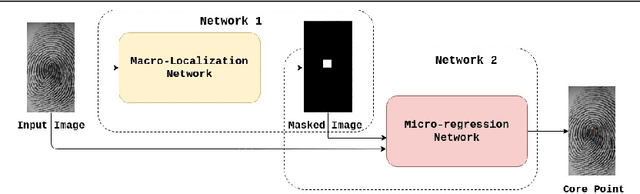

Singular points of a fingerprint image are special locations having high curvature properties. They can play a pivotal role in fingerprint normalization and reliable feature extraction. Accurate and efficient extraction of a singular point plays a major role in successful fingerprint recognition and indexing. In this paper, a novel deep learning based architecture is proposed for one shot (end-to-end) singular point detection from an input fingerprint image. The model consists of a Macro-Localization Network and a Micro-Regression Network along with three stacked hourglass as a bottleneck. The proposed model has been tested on three databases viz. FVC2002 DB1_A, FVC2002 DB2_A and FPL30K and has been found to achieve true detection rate of 98.75%, 97.5% and 92.72% respectively, which is better than any other state-of-the-art technique.
FKIMNet: A Finger Dorsal Image Matching Network Comparing Component (Major, Minor and Nail) Matching with Holistic (Finger Dorsal) Matching
Apr 02, 2019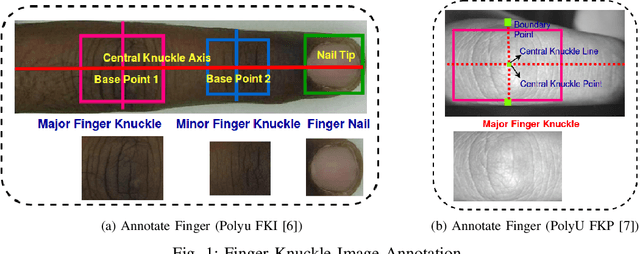
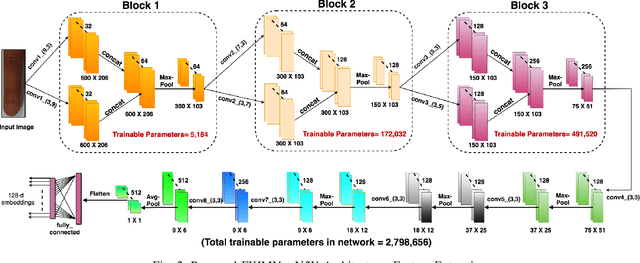
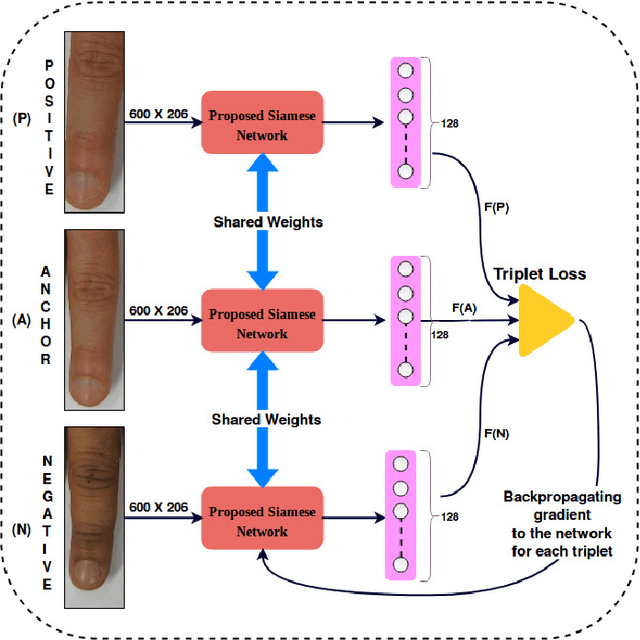
Current finger knuckle image recognition systems, often require users to place fingers' major or minor joints flatly towards the capturing sensor. To extend these systems for user non-intrusive application scenarios, such as consumer electronics, forensic, defence etc, we suggest matching the full dorsal fingers, rather than the major/ minor region of interest (ROI) alone. In particular, this paper makes a comprehensive study on the comparisons between full finger and fusion of finger ROI's for finger knuckle image recognition. These experiments suggest that using full-finger, provides a more elegant solution. Addressing the finger matching problem, we propose a CNN (convolutional neural network) which creates a $128$-D feature embedding of an image. It is trained via. triplet loss function, which enforces the L2 distance between the embeddings of the same subject to be approaching zero, whereas the distance between any 2 embeddings of different subjects to be at least a margin. For precise training of the network, we use dynamic adaptive margin, data augmentation, and hard negative mining. In distinguished experiments, the individual performance of finger, as well as weighted sum score level fusion of major knuckle, minor knuckle, and nail modalities have been computed, justifying our assumption to consider full finger as biometrics instead of its counterparts. The proposed method is evaluated using two publicly available finger knuckle image datasets i.e., PolyU FKP dataset and PolyU Contactless FKI Datasets.
Multiscale CNN based Deep Metric Learning for Bioacoustic Classification: Overcoming Training Data Scarcity Using Dynamic Triplet Loss
Mar 27, 2019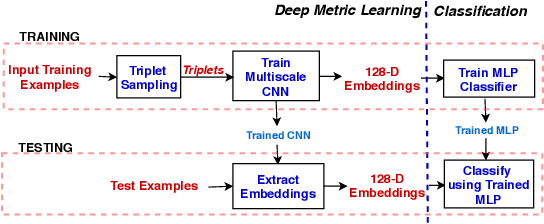
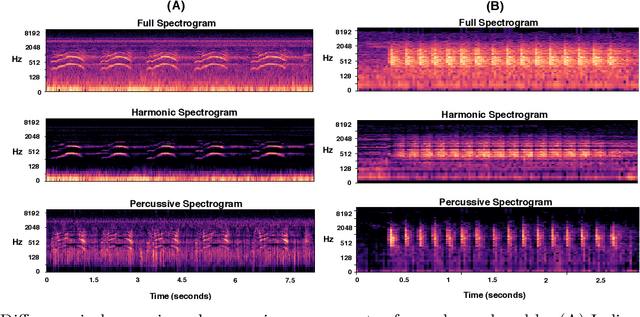
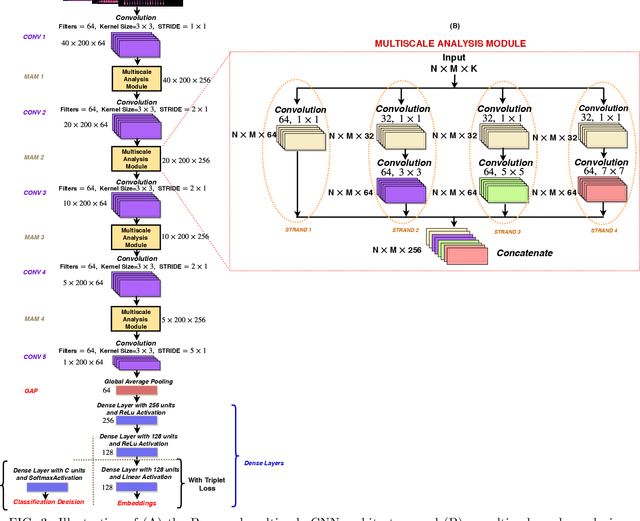
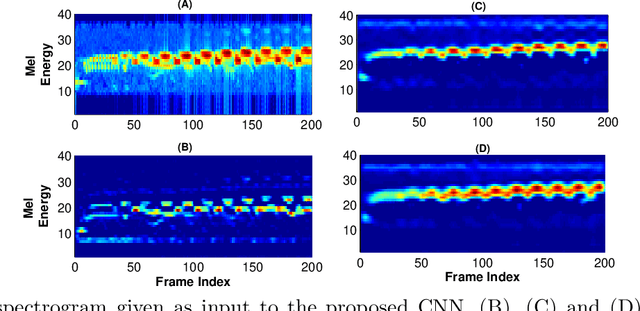
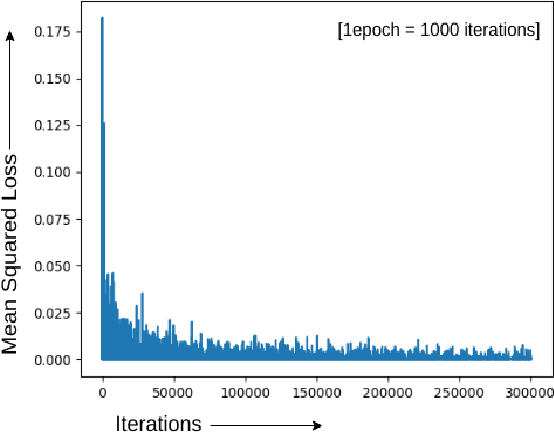
This paper proposes multiscale convolutional neural network (CNN)-based deep metric learning for bioacoustic classification, under low training data conditions. The proposed CNN is characterized by the utilization of four different filter sizes at each level to analyze input feature maps. This multiscale nature helps in describing different bioacoustic events effectively: smaller filters help in learning the finer details of bioacoustic events, whereas, larger filters help in analyzing a larger context leading to global details. A dynamic triplet loss is employed in the proposed CNN architecture to learn a transformation from the input space to the embedding space, where classification is performed. The triplet loss helps in learning this transformation by analyzing three examples, referred to as triplets, at a time where intra-class distance is minimized while maximizing the inter-class separation by a dynamically increasing margin. The number of possible triplets increases cubically with the dataset size, making triplet loss more suitable than the softmax cross-entropy loss in low training data conditions. Experiments on three different publicly available datasets show that the proposed framework performs better than existing bioacoustic classification frameworks. Experimental results also confirm the superiority of the triplet loss over the cross-entropy loss in low training data conditions
FDSNet: Finger dorsal image spoof detection network using light field camera
Dec 18, 2018
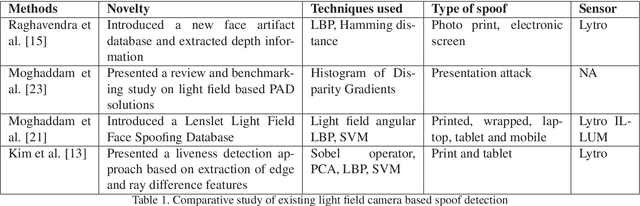
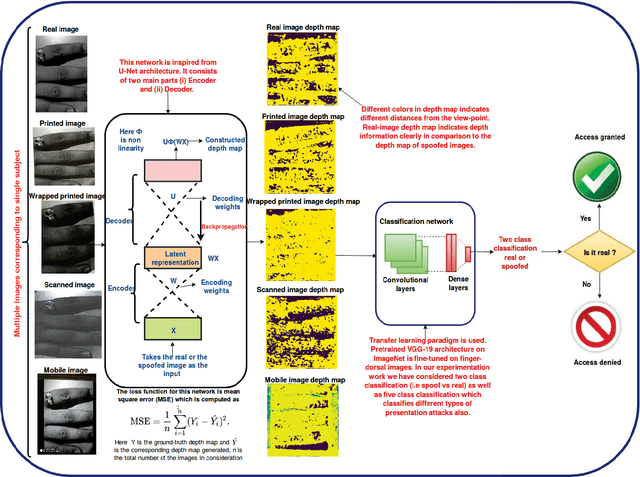
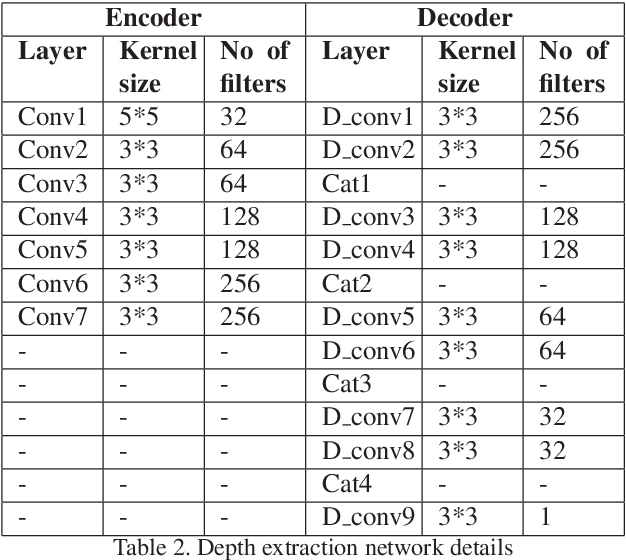
At present spoofing attacks via which biometric system is potentially vulnerable against a fake biometric characteristic, introduces a great challenge to recognition performance. Despite the availability of a broad range of presentation attack detection (PAD) or liveness detection algorithms, fingerprint sensors are vulnerable to spoofing via fake fingers. In such situations, finger dorsal images can be thought of as an alternative which can be captured without much user cooperation and are more appropriate for outdoor security applications. In this paper, we present a first feasibility study of spoofing attack scenarios on finger dorsal authentication system, which include four types of presentation attacks such as printed paper, wrapped printed paper, scan and mobile. This study also presents a CNN based spoofing attack detection method which employ state-of-the-art deep learning techniques along with transfer learning mechanism. We have collected 196 finger dorsal real images from 33 subjects, captured with a Lytro camera and also created a set of 784 finger dorsal spoofing images. Extensive experimental results have been performed that demonstrates the superiority of the proposed approach for various spoofing attacks.
PVSNet: Palm Vein Authentication Siamese Network Trained using Triplet Loss and Adaptive Hard Mining by Learning Enforced Domain Specific Features
Dec 15, 2018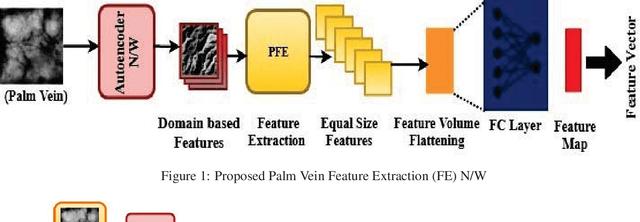
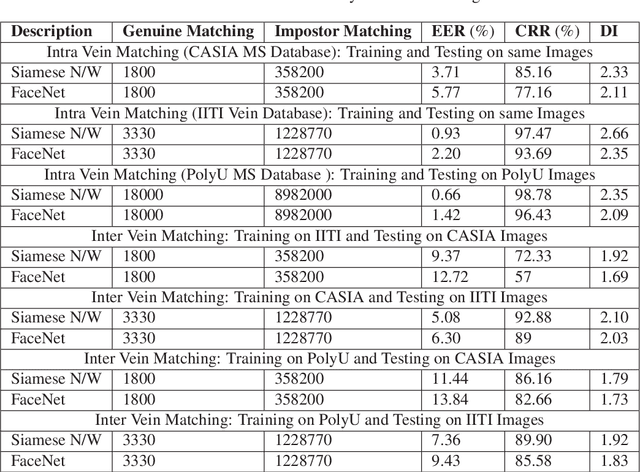
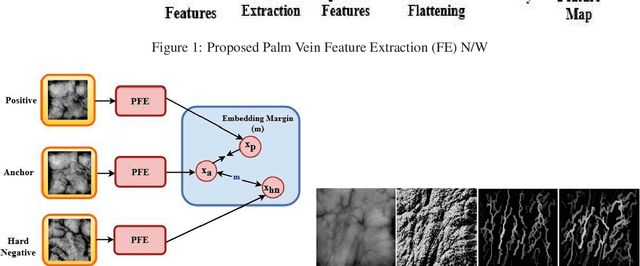

Designing an end-to-end deep learning network to match the biometric features with limited training samples is an extremely challenging task. To address this problem, we propose a new way to design an end-to-end deep CNN framework i.e., PVSNet that works in two major steps: first, an encoder-decoder network is used to learn generative domain-specific features followed by a Siamese network in which convolutional layers are pre-trained in an unsupervised fashion as an autoencoder. The proposed model is trained via triplet loss function that is adjusted for learning feature embeddings in a way that minimizes the distance between embedding-pairs from the same subject and maximizes the distance with those from different subjects, with a margin. In particular, a triplet Siamese matching network using an adaptive margin based hard negative mining has been suggested. The hyper-parameters associated with the training strategy, like the adaptive margin, have been tuned to make the learning more effective on biometric datasets. In extensive experimentation, the proposed network outperforms most of the existing deep learning solutions on three type of typical vein datasets which clearly demonstrates the effectiveness of our proposed method.