 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary-Label Learning for Arbitrary Losses and Models
Oct 10, 2018
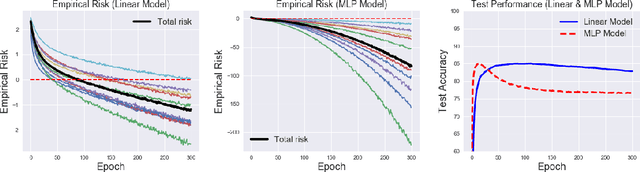
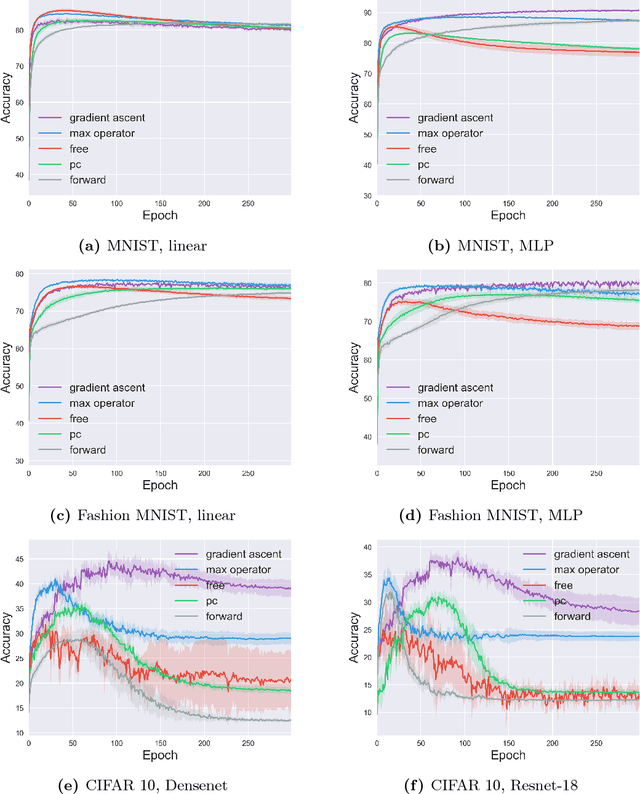
In contrast to the standard classification paradigm where the true (or possibly noisy) class is given to each training pattern, complementary-label learning only uses training patterns each equipped with a complementary label. This only specifies one of the classes that the pattern does not belong to. The seminal paper on complementary-label learning proposed an unbiased estimator of the classification risk that can be computed only from complementarily labeled data. However, it required a restrictive condition on the loss functions, making it impossible to use popular losses such as the softmax cross-entropy loss. Recently, another formulation with the softmax cross-entropy loss was proposed with consistency guarantee. However, this formulation does not explicitly involve a risk estimator. Thus model/hyper-parameter selection is not possible by cross-validation---we may need additional ordinarily labeled data for validation purposes, which is not available in the current setup. In this paper, we give a novel general framework of complementary-label learning, and derive an unbiased risk estimator for arbitrary losses and models. We further improve the risk estimator by non-negative correction and demonstrate its superiority through experiments.
Monge beats Bayes: Hardness Results for Adversarial Training
Sep 12, 2018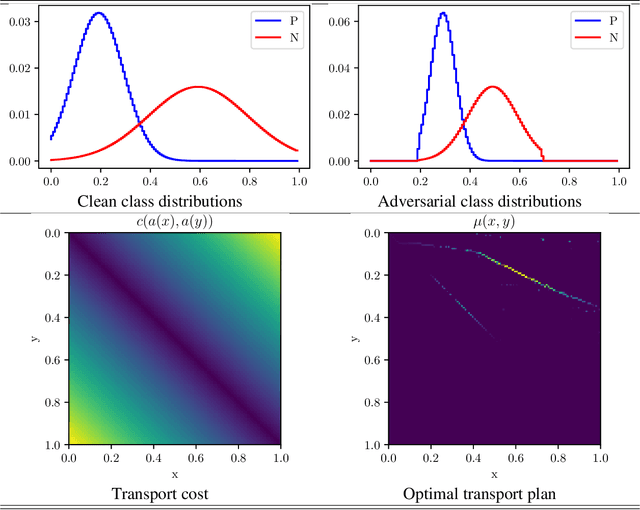
The last few years have seen extensive empirical study of the robustness of neural networks, with a concerning conclusion: several state-of-the-art approaches are highly sensitive to adversarial perturbations of their inputs. There has been an accompanying surge of interest in learning including defense mechanisms against specific adversaries, known as adversarial training. Despite some impressive advances, little remains known on how to best frame a resource-bounded adversary so that it can be severely detrimental to learning, a non-trivial problem which entails at a minimum the choice of loss and classifiers. We suggest here a formal answer to this question, and pin down a simple sufficient property for any given class of adversaries to be detrimental to learning. This property involves a central measure of `harmfulness' which generalizes the well-known class of integral probability metrics. A key feature of our result is that it holds for \textit{all} proper losses, and for a popular subset of these, the optimisation of this central measure appears to be independent of the loss. We show how weakly contractive adversaries for a RKHS can be self-combined to build a maximally detrimental adversary, we show that some implemented existing adversaries involve proxies of our optimal transport adversaries and finally provide a toy experiment assessing such adversaries in a simple context, displaying that additional robustness on testing can be granted through adversarial training.
Anomaly Detection using One-Class Neural Networks
Feb 18, 2018
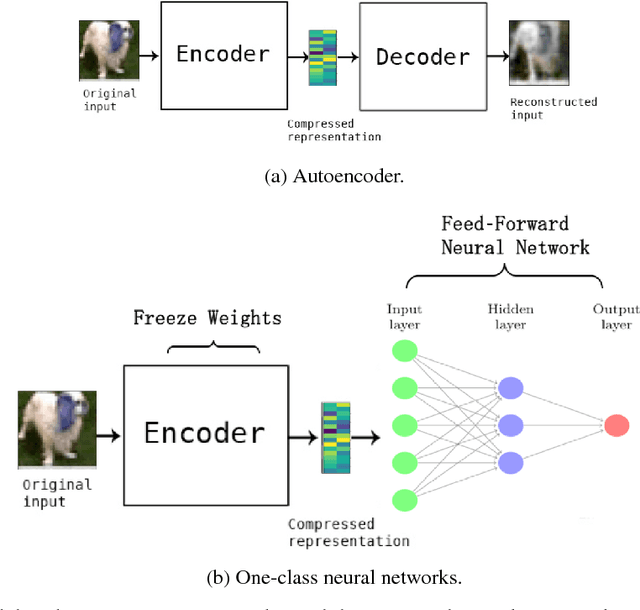
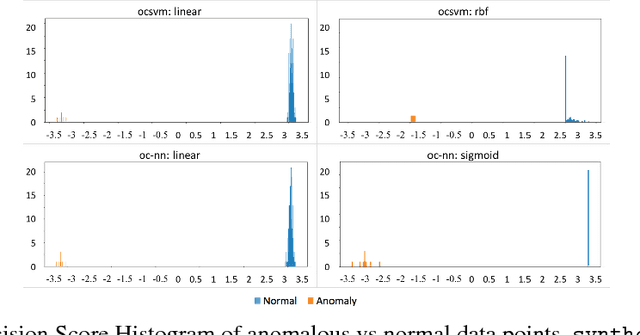
We propose a one-class neural network (OC-NN) model to detect anomalies in complex data sets. OC-NN combines the ability of deep networks to extract progressively rich representation of data with the one-class objective of creating a tight envelope around normal data. The OC-NN approach breaks new ground for the following crucial reason: data representation in the hidden layer is driven by the OC-NN objective and is thus customized for anomaly detection. This is a departure from other approaches which use a hybrid approach of learning deep features using an autoencoder and then feeding the features into a separate anomaly detection method like one-class SVM (OC-SVM). The hybrid OC-SVM approach is suboptimal because it is unable to influence representational learning in the hidden layers. A comprehensive set of experiments demonstrate that on complex data sets (like CIFAR and PFAM), OC-NN significantly outperforms existing state-of-the-art anomaly detection methods.
Revisiting revisits in trajectory recommendation
Aug 17, 2017
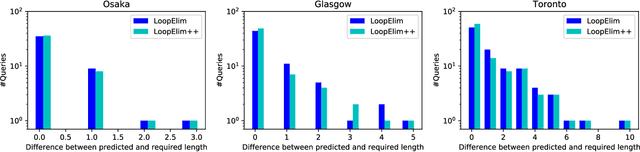
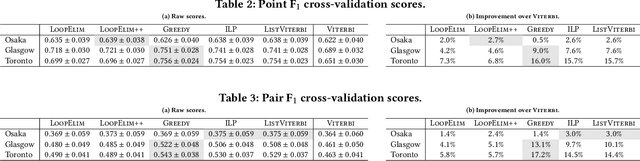
Trajectory recommendation is the problem of recommending a sequence of places in a city for a tourist to visit. It is strongly desirable for the recommended sequence to avoid loops, as tourists typically would not wish to revisit the same location. Given some learned model that scores sequences, how can we then find the highest-scoring sequence that is loop-free? This paper studies this problem, with three contributions. First, we detail three distinct approaches to the problem -- graph-based heuristics, integer linear programming, and list extensions of the Viterbi algorithm -- and qualitatively summarise their strengths and weaknesses. Second, we explicate how two ostensibly different approaches to the list Viterbi algorithm are in fact fundamentally identical. Third, we conduct experiments on real-world trajectory recommendation datasets to identify the tradeoffs imposed by each of the three approaches. Overall, our results indicate that a greedy graph-based heuristic offer excellent performance and runtime, leading us to recommend its use for removing loops at prediction time.
Robust, Deep and Inductive Anomaly Detection
Jul 30, 2017

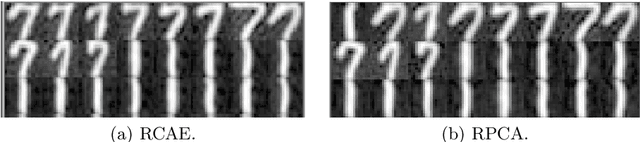
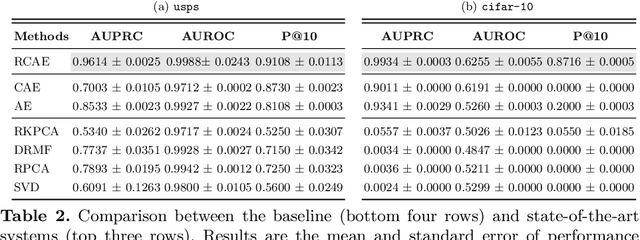
PCA is a classical statistical technique whose simplicity and maturity has seen it find widespread use as an anomaly detection technique. However, it is limited in this regard by being sensitive to gross perturbations of the input, and by seeking a linear subspace that captures normal behaviour. The first issue has been dealt with by robust PCA, a variant of PCA that explicitly allows for some data points to be arbitrarily corrupted, however, this does not resolve the second issue, and indeed introduces the new issue that one can no longer inductively find anomalies on a test set. This paper addresses both issues in a single model, the robust autoencoder. This method learns a nonlinear subspace that captures the majority of data points, while allowing for some data to have arbitrary corruption. The model is simple to train and leverages recent advances in the optimisation of deep neural networks. Experiments on a range of real-world datasets highlight the model's effectiveness.
f-GANs in an Information Geometric Nutshell
Jul 14, 2017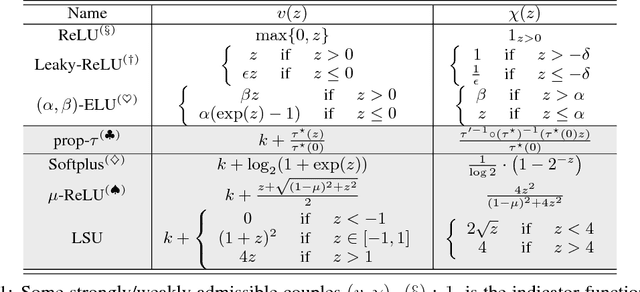

Nowozin \textit{et al} showed last year how to extend the GAN \textit{principle} to all $f$-divergences. The approach is elegant but falls short of a full description of the supervised game, and says little about the key player, the generator: for example, what does the generator actually converge to if solving the GAN game means convergence in some space of parameters? How does that provide hints on the generator's design and compare to the flourishing but almost exclusively experimental literature on the subject? In this paper, we unveil a broad class of distributions for which such convergence happens --- namely, deformed exponential families, a wide superset of exponential families --- and show tight connections with the three other key GAN parameters: loss, game and architecture. In particular, we show that current deep architectures are able to factorize a very large number of such densities using an especially compact design, hence displaying the power of deep architectures and their concinnity in the $f$-GAN game. This result holds given a sufficient condition on \textit{activation functions} --- which turns out to be satisfied by popular choices. The key to our results is a variational generalization of an old theorem that relates the KL divergence between regular exponential families and divergences between their natural parameters. We complete this picture with additional results and experimental insights on how these results may be used to ground further improvements of GAN architectures, via (i) a principled design of the activation functions in the generator and (ii) an explicit integration of proper composite losses' link function in the discriminator.
The cost of fairness in classification
May 25, 2017

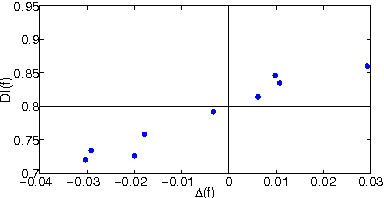
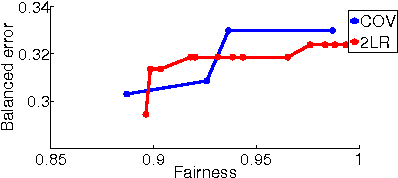
We study the problem of learning classifiers with a fairness constraint, with three main contributions towards the goal of quantifying the problem's inherent tradeoffs. First, we relate two existing fairness measures to cost-sensitive risks. Second, we show that for cost-sensitive classification and fairness measures, the optimal classifier is an instance-dependent thresholding of the class-probability function. Third, we show how the tradeoff between accuracy and fairness is determined by the alignment between the class-probabilities for the target and sensitive features. Underpinning our analysis is a general framework that casts the problem of learning with a fairness requirement as one of minimising the difference of two statistical risks.
A scaled Bregman theorem with applications
Jul 01, 2016
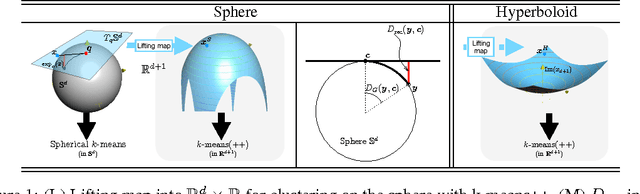

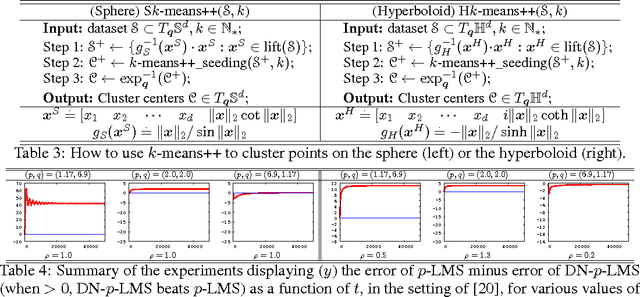
Bregman divergences play a central role in the design and analysis of a range of machine learning algorithms. This paper explores the use of Bregman divergences to establish reductions between such algorithms and their analyses. We present a new scaled isodistortion theorem involving Bregman divergences (scaled Bregman theorem for short) which shows that certain "Bregman distortions'" (employing a potentially non-convex generator) may be exactly re-written as a scaled Bregman divergence computed over transformed data. Admissible distortions include geodesic distances on curved manifolds and projections or gauge-normalisation, while admissible data include scalars, vectors and matrices. Our theorem allows one to leverage to the wealth and convenience of Bregman divergences when analysing algorithms relying on the aforementioned Bregman distortions. We illustrate this with three novel applications of our theorem: a reduction from multi-class density ratio to class-probability estimation, a new adaptive projection free yet norm-enforcing dual norm mirror descent algorithm, and a reduction from clustering on flat manifolds to clustering on curved manifolds. Experiments on each of these domains validate the analyses and suggest that the scaled Bregman theorem might be a worthy addition to the popular handful of Bregman divergence properties that have been pervasive in machine learning.
Learning from Binary Labels with Instance-Dependent Corruption
May 04, 2016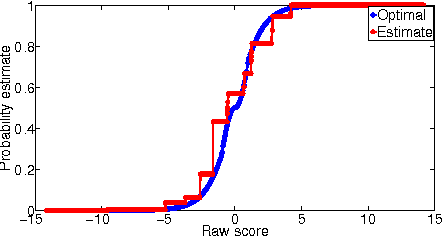
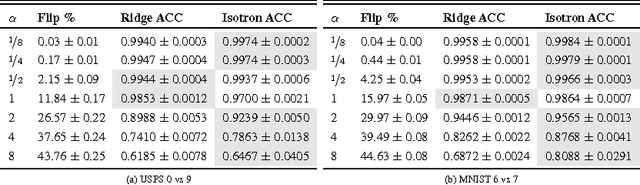
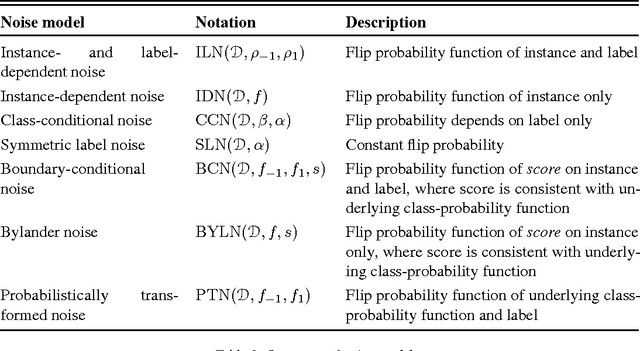
Suppose we have a sample of instances paired with binary labels corrupted by arbitrary instance- and label-dependent noise. With sufficiently many such samples, can we optimally classify and rank instances with respect to the noise-free distribution? We provide a theoretical analysis of this question, with three main contributions. First, we prove that for instance-dependent noise, any algorithm that is consistent for classification on the noisy distribution is also consistent on the clean distribution. Second, we prove that for a broad class of instance- and label-dependent noise, a similar consistency result holds for the area under the ROC curve. Third, for the latter noise model, when the noise-free class-probability function belongs to the generalised linear model family, we show that the Isotron can efficiently and provably learn from the corrupted sample.
An Average Classification Algorithm
Dec 15, 2015
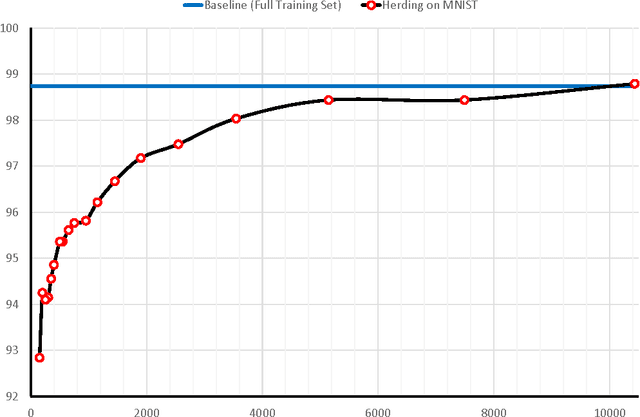
Many classification algorithms produce a classifier that is a weighted average of kernel evaluations. When working with a high or infinite dimensional kernel, it is imperative for speed of evaluation and storage issues that as few training samples as possible are used in the kernel expansion. Popular existing approaches focus on altering standard learning algorithms, such as the Support Vector Machine, to induce sparsity, as well as post-hoc procedures for sparse approximations. Here we adopt the latter approach. We begin with a very simple classifier, given by the kernel mean $$ f(x) = \frac{1}{n} \sum\limits_{i=i}^{n} y_i K(x_i,x) $$ We then find a sparse approximation to this kernel mean via herding. The result is an accurate, easily parallelized algorithm for learning classifiers.