 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy do we Trust Chatbots? From Normative Principles to Behavioral Drivers
Feb 09, 2026As chatbots increasingly blur the boundary between automated systems and human conversation, the foundations of trust in these systems warrant closer examination. While regulatory and policy frameworks tend to define trust in normative terms, the trust users place in chatbots often emerges from behavioral mechanisms. In many cases, this trust is not earned through demonstrated trustworthiness but is instead shaped by interactional design choices that leverage cognitive biases to influence user behavior. Based on this observation, we propose reframing chatbots not as companions or assistants, but as highly skilled salespeople whose objectives are determined by the deploying organization. We argue that the coexistence of competing notions of "trust" under a shared term obscures important distinctions between psychological trust formation and normative trustworthiness. Addressing this gap requires further research and stronger support mechanisms to help users appropriately calibrate trust in conversational AI systems.
Aesthetics as Structural Harm: Algorithmic Lookism Across Text-to-Image Generation and Classification
Jan 15, 2026This paper examines algorithmic lookism-the systematic preferential treatment based on physical appearance-in text-to-image (T2I) generative AI and a downstream gender classification task. Through the analysis of 26,400 synthetic faces created with Stable Diffusion 2.1 and 3.5 Medium, we demonstrate how generative AI models systematically associate facial attractiveness with positive attributes and vice-versa, mirroring socially constructed biases rather than evidence-based correlations. Furthermore, we find significant gender bias in three gender classification algorithms depending on the attributes of the input faces. Our findings reveal three critical harms: (1) the systematic encoding of attractiveness-positive attribute associations in T2I models; (2) gender disparities in classification systems, where women's faces, particularly those generated with negative attributes, suffer substantially higher misclassification rates than men's; and (3) intensifying aesthetic constraints in newer models through age homogenization, gendered exposure patterns, and geographic reductionism. These convergent patterns reveal algorithmic lookism as systematic infrastructure operating across AI vision systems, compounding existing inequalities through both representation and recognition. Disclaimer: This work includes visual and textual content that reflects stereotypical associations between physical appearance and socially constructed attributes, including gender, race, and traits associated with social desirability. Any such associations found in this study emerge from the biases embedded in generative AI systems-not from empirical truths or the authors' views.
Normalized Space Alignment: A Versatile Metric for Representation Analysis
Nov 07, 2024We introduce a manifold analysis technique for neural network representations. Normalized Space Alignment (NSA) compares pairwise distances between two point clouds derived from the same source and having the same size, while potentially possessing differing dimensionalities. NSA can act as both an analytical tool and a differentiable loss function, providing a robust means of comparing and aligning representations across different layers and models. It satisfies the criteria necessary for both a similarity metric and a neural network loss function. We showcase NSA's versatility by illustrating its utility as a representation space analysis metric, a structure-preserving loss function, and a robustness analysis tool. NSA is not only computationally efficient but it can also approximate the global structural discrepancy during mini-batching, facilitating its use in a wide variety of neural network training paradigms.
Self-rationalization improves LLM as a fine-grained judge
Oct 07, 2024



LLM-as-a-judge models have been used for evaluating both human and AI generated content, specifically by providing scores and rationales. Rationales, in addition to increasing transparency, help models learn to calibrate its judgments. Enhancing a model's rationale can therefore improve its calibration abilities and ultimately the ability to score content. We introduce Self-Rationalization, an iterative process of improving the rationales for the judge models, which consequently improves the score for fine-grained customizable scoring criteria (i.e., likert-scale scoring with arbitrary evaluation criteria). Self-rationalization works by having the model generate multiple judgments with rationales for the same input, curating a preference pair dataset from its own judgements, and iteratively fine-tuning the judge via DPO. Intuitively, this approach allows the judge model to self-improve by learning from its own rationales, leading to better alignment and evaluation accuracy. After just two iterations -- while only relying on examples in the training set -- human evaluation shows that our judge model learns to produce higher quality rationales, with a win rate of $62\%$ on average compared to models just trained via SFT on rationale . This judge model also achieves high scoring accuracy on BigGen Bench and Reward Bench, outperforming even bigger sized models trained using SFT with rationale, self-consistency or best-of-$N$ sampling by $3\%$ to $9\%$.
Lookism: The overlooked bias in computer vision
Aug 21, 2024

In recent years, there have been significant advancements in computer vision which have led to the widespread deployment of image recognition and generation systems in socially relevant applications, from hiring to security screening. However, the prevalence of biases within these systems has raised significant ethical and social concerns. The most extensively studied biases in this context are related to gender, race and age. Yet, other biases are equally pervasive and harmful, such as lookism, i.e., the preferential treatment of individuals based on their physical appearance. Lookism remains under-explored in computer vision but can have profound implications not only by perpetuating harmful societal stereotypes but also by undermining the fairness and inclusivity of AI technologies. Thus, this paper advocates for the systematic study of lookism as a critical bias in computer vision models. Through a comprehensive review of existing literature, we identify three areas of intersection between lookism and computer vision. We illustrate them by means of examples and a user study. We call for an interdisciplinary approach to address lookism, urging researchers, developers, and policymakers to prioritize the development of equitable computer vision systems that respect and reflect the diversity of human appearances.
Human Shape and Clothing Estimation
Feb 28, 2024



Human shape and clothing estimation has gained significant prominence in various domains, including online shopping, fashion retail, augmented reality (AR), virtual reality (VR), and gaming. The visual representation of human shape and clothing has become a focal point for computer vision researchers in recent years. This paper presents a comprehensive survey of the major works in the field, focusing on four key aspects: human shape estimation, fashion generation, landmark detection, and attribute recognition. For each of these tasks, the survey paper examines recent advancements, discusses their strengths and limitations, and qualitative differences in approaches and outcomes. By exploring the latest developments in human shape and clothing estimation, this survey aims to provide a comprehensive understanding of the field and inspire future research in this rapidly evolving domain.
BIASeD: Bringing Irrationality into Automated System Design
Oct 01, 2022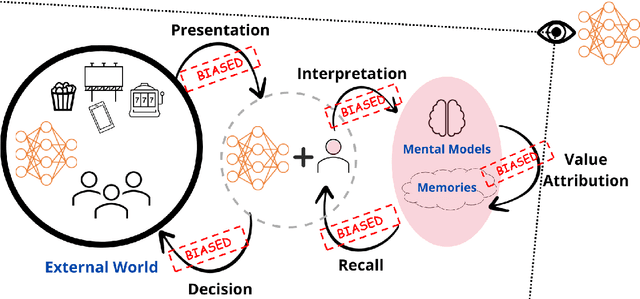
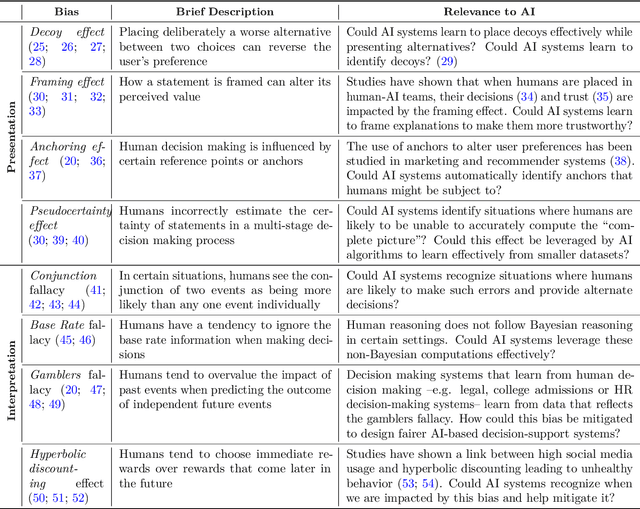
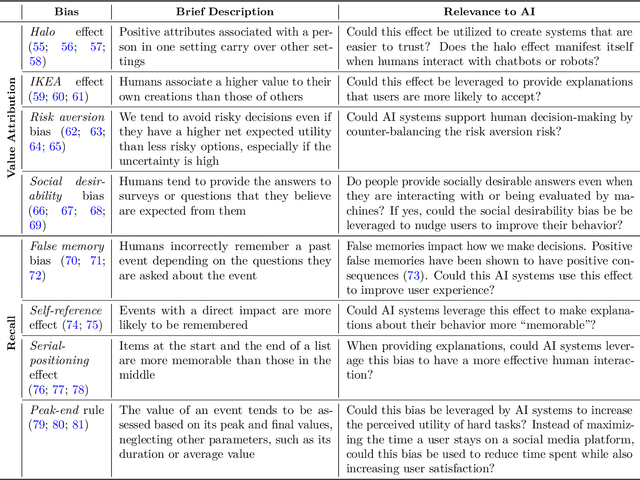
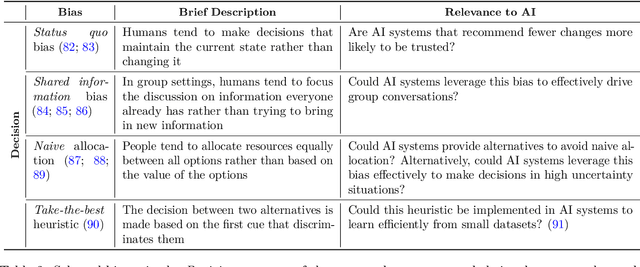
Human perception, memory and decision-making are impacted by tens of cognitive biases and heuristics that influence our actions and decisions. Despite the pervasiveness of such biases, they are generally not leveraged by today's Artificial Intelligence (AI) systems that model human behavior and interact with humans. In this theoretical paper, we claim that the future of human-machine collaboration will entail the development of AI systems that model, understand and possibly replicate human cognitive biases. We propose the need for a research agenda on the interplay between human cognitive biases and Artificial Intelligence. We categorize existing cognitive biases from the perspective of AI systems, identify three broad areas of interest and outline research directions for the design of AI systems that have a better understanding of our own biases.
Interleaving Fast and Slow Decision Making
Oct 30, 2020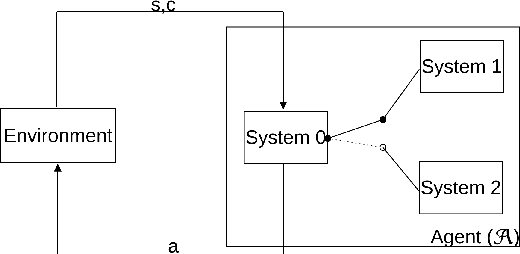
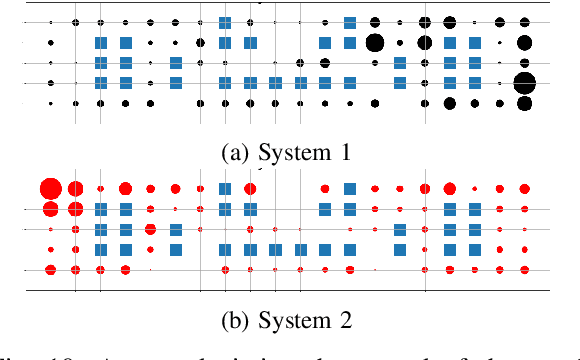
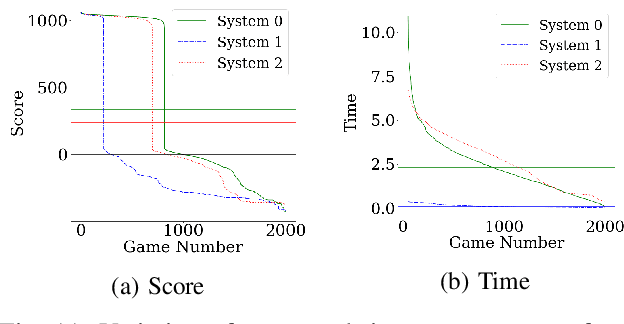
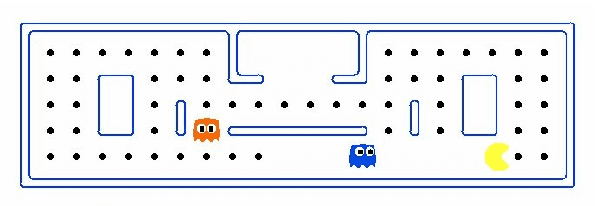
The "Thinking, Fast and Slow" paradigm of Kahneman proposes that we use two different styles of thinking -- a fast and intuitive System 1 for certain tasks, along with a slower but more analytical System 2 for others. While the idea of using this two-system style of thinking is gaining popularity in AI and robotics, our work considers how to interleave the two styles of decision-making, i.e., how System 1 and System 2 should be used together. For this, we propose a novel and general framework which includes a new System 0 to oversee Systems 1 and 2. At every point when a decision needs to be made, System 0 evaluates the situation and quickly hands over the decision-making process to either System 1 or System 2. We evaluate such a framework on a modified version of the classic Pac-Man game, with an already-trained RL algorithm for System 1, a Monte-Carlo tree search for System 2, and several different possible strategies for System 0. As expected, arbitrary switches between Systems 1 and 2 do not work, but certain strategies do well. With System 0, an agent is able to perform better than one that uses only System 1 or System 2.
Accelerating 2PC-based ML with Limited Trusted Hardware
Sep 11, 2020



This paper describes the design, implementation, and evaluation of Otak, a system that allows two non-colluding cloud providers to run machine learning (ML) inference without knowing the inputs to inference. Prior work for this problem mostly relies on advanced cryptography such as two-party secure computation (2PC) protocols that provide rigorous guarantees but suffer from high resource overhead. Otak improves efficiency via a new 2PC protocol that (i) tailors recent primitives such as function and homomorphic secret sharing to ML inference, and (ii) uses trusted hardware in a limited capacity to bootstrap the protocol. At the same time, Otak reduces trust assumptions on trusted hardware by running a small code inside the hardware, restricting its use to a preprocessing step, and distributing trust over heterogeneous trusted hardware platforms from different vendors. An implementation and evaluation of Otak demonstrates that its CPU and network overhead converted to a dollar amount is 5.4$-$385$\times$ lower than state-of-the-art 2PC-based works. Besides, Otak's trusted computing base (code inside trusted hardware) is only 1,300 lines of code, which is 14.6$-$29.2$\times$ lower than the code-size in prior trusted hardware-based works.