 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyML-Enabled IoT for Sustainable Precision Irrigation
Jan 19, 2026Small-scale farming communities are disproportionately affected by water scarcity, erratic climate patterns, and a lack of access to advanced, affordable agricultural technologies. To address these challenges, this paper presents a novel, edge-first IoT framework that integrates Tiny Machine Learning (TinyML) for intelligent, offline-capable precision irrigation. The proposed four-layer architecture leverages low-cost hardware, an ESP32 microcontroller as an edge inference node, and a Raspberry Pi as a local edge server to enable autonomous decision-making without cloud dependency. The system utilizes capacitive soil moisture, temperature, humidity, pH, and ambient light sensors for environmental monitoring. A rigorous comparative analysis of ensemble models identified gradient boosting as superior, achieving an R^2 score of 0.9973 and a Mean Absolute Percentage Error (MAPE) of 0.99%, outperforming a random forest model (R^2 = 0.9916, MAPE = 1.81%). This optimized model was converted and deployed as a lightweight TinyML inference engine on the ESP32 and predicts irrigation needs with exceptional accuracy (MAPE < 1%). Local communication is facilitated by an MQTT-based LAN protocol, ensuring reliable operation in areas with limited or no internet connectivity. Experimental validation in a controlled environment demonstrated a significant reduction in water usage compared to traditional methods, while the system's low-power design and offline functionality confirm its viability for sustainable, scalable deployment in resource-constrained rural settings. This work provides a practical, cost-effective blueprint for bridging the technological divide in agriculture and enhancing water-use efficiency through on-device artificial intelligence.
An Ubuntu-Guided Large Language Model Framework for Cognitive Behavioral Mental Health Dialogue
Jan 11, 2026South Africa's escalating mental health crisis, compounded by limited access to culturally responsive care, calls for innovative and contextually grounded interventions. While large language models show considerable promise for mental health support, their predominantly Western-centric training data limit cultural and linguistic applicability in African contexts. This study introduces a proof-of-concept framework that integrates cognitive behavioral therapy with the African philosophy of Ubuntu to create a culturally sensitive, emotionally intelligent, AI-driven mental health dialogue system. Guided by a design science research methodology, the framework applies both deep theoretical and therapeutic adaptations as well as surface-level linguistic and communicative cultural adaptations. Key CBT techniques, including behavioral activation and cognitive restructuring, were reinterpreted through Ubuntu principles that emphasize communal well-being, spiritual grounding, and interconnectedness. A culturally adapted dataset was developed through iterative processes of language simplification, spiritual contextualization, and Ubuntu-based reframing. The fine-tuned model was evaluated through expert-informed case studies, employing UniEval for conversational quality assessment alongside additional measures of CBT reliability and cultural linguistic alignment. Results demonstrate that the model effectively engages in empathetic, context-aware dialogue aligned with both therapeutic and cultural objectives. Although real-time end-user testing has not yet been conducted, the model underwent rigorous review and supervision by domain specialist clinical psychologists. The findings highlight the potential of culturally embedded emotional intelligence to enhance the contextual relevance, inclusivity, and effectiveness of AI-driven mental health interventions across African settings.
Classical Machine Learning: Seventy Years of Algorithmic Learning Evolution
Aug 03, 2024



Machine learning (ML) has transformed numerous fields, but understanding its foundational research is crucial for its continued progress. This paper presents an overview of the significant classical ML algorithms and examines the state-of-the-art publications spanning twelve decades through an extensive bibliometric analysis study. We analyzed a dataset of highly cited papers from prominent ML conferences and journals, employing citation and keyword analyses to uncover critical insights. The study further identifies the most influential papers and authors, reveals the evolving collaborative networks within the ML community, and pinpoints prevailing research themes and emerging focus areas. Additionally, we examine the geographic distribution of highly cited publications, highlighting the leading countries in ML research. This study provides a comprehensive overview of the evolution of traditional learning algorithms and their impacts. It discusses challenges and opportunities for future development, focusing on the Global South. The findings from this paper offer valuable insights for both ML experts and the broader research community, enhancing understanding of the field's trajectory and its significant influence on recent advances in learning algorithms.
A Comprehensive Study of Groundbreaking Machine Learning Research: Analyzing Highly Cited and Impactful Publications across Six Decades
Aug 01, 2023



Machine learning (ML) has emerged as a prominent field of research in computer science and other related fields, thereby driving advancements in other domains of interest. As the field continues to evolve, it is crucial to understand the landscape of highly cited publications to identify key trends, influential authors, and significant contributions made thus far. In this paper, we present a comprehensive bibliometric analysis of highly cited ML publications. We collected a dataset consisting of the top-cited papers from reputable ML conferences and journals, covering a period of several years from 1959 to 2022. We employed various bibliometric techniques to analyze the data, including citation analysis, co-authorship analysis, keyword analysis, and publication trends. Our findings reveal the most influential papers, highly cited authors, and collaborative networks within the machine learning community. We identify popular research themes and uncover emerging topics that have recently gained significant attention. Furthermore, we examine the geographical distribution of highly cited publications, highlighting the dominance of certain countries in ML research. By shedding light on the landscape of highly cited ML publications, our study provides valuable insights for researchers, policymakers, and practitioners seeking to understand the key developments and trends in this rapidly evolving field.
Breast Cancer Detection and Diagnosis: A comparative study of state-of-the-arts deep learning architectures
May 31, 2023



Breast cancer is a prevalent form of cancer among women, with over 1.5 million women being diagnosed each year. Unfortunately, the survival rates for breast cancer patients in certain third-world countries, like South Africa, are alarmingly low, with only 40% of diagnosed patients surviving beyond five years. The inadequate availability of resources, including qualified pathologists, delayed diagnoses, and ineffective therapy planning, contribute to this low survival rate. To address this pressing issue, medical specialists and researchers have turned to domain-specific AI approaches, specifically deep learning models, to develop end-to-end solutions that can be integrated into computer-aided diagnosis (CAD) systems. By improving the workflow of pathologists, these AI models have the potential to enhance the detection and diagnosis of breast cancer. This research focuses on evaluating the performance of various cutting-edge convolutional neural network (CNN) architectures in comparison to a relatively new model called the Vision Trans-former (ViT). The objective is to determine the superiority of these models in terms of their accuracy and effectiveness. The experimental results reveal that the ViT models outperform the other selected state-of-the-art CNN architectures, achieving an impressive accuracy rate of 95.15%. This study signifies a significant advancement in the field, as it explores the utilization of data augmentation and other relevant preprocessing techniques in conjunction with deep learning models for the detection and diagnosis of breast cancer using datasets of Breast Cancer Histopathological Image Classification.
Machine Learning Research Trends in Africa: A 30 Years Overview with Bibliometric Analysis Review
Apr 18, 2023In this paper, a critical bibliometric analysis study is conducted, coupled with an extensive literature survey on recent developments and associated applications in machine learning research with a perspective on Africa. The presented bibliometric analysis study consists of 2761 machine learning-related documents, of which 98% were articles with at least 482 citations published in 903 journals during the past 30 years. Furthermore, the collated documents were retrieved from the Science Citation Index EXPANDED, comprising research publications from 54 African countries between 1993 and 2021. The bibliometric study shows the visualization of the current landscape and future trends in machine learning research and its application to facilitate future collaborative research and knowledge exchange among authors from different research institutions scattered across the African continent.
Ebola Optimization Search Algorithm (EOSA): A new metaheuristic algorithm based on the propagation model of Ebola virus disease
Jun 19, 2021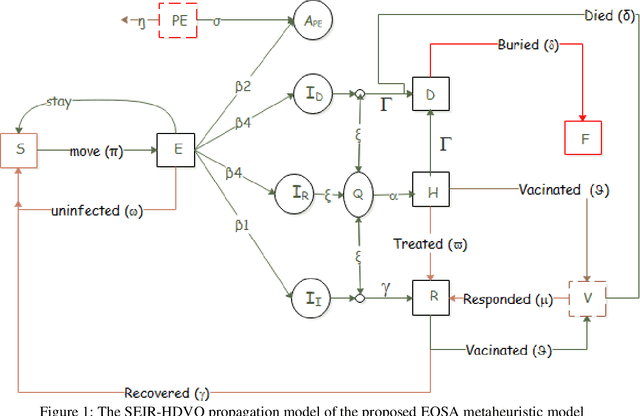

The Ebola virus and the disease in effect tend to randomly move individuals in the population around susceptible, infected, quarantined, hospitalized, recovered, and dead sub-population. Motivated by the effectiveness in propagating the disease through the virus, a new bio-inspired and population-based optimization algorithm is proposed. This paper presents a novel metaheuristic algorithm named Ebola optimization algorithm (EOSA). To correctly achieve this, this study models the propagation mechanism of the Ebola virus disease, emphasising all consistent states of the propagation. The model was further represented using a mathematical model based on first-order differential equations. After that, the combined propagation and mathematical models were adapted for developing the new metaheuristic algorithm. To evaluate the proposed method's performance and capability compared with other optimization methods, the underlying propagation and mathematical models were first investigated to determine how they successfully simulate the EVD. Furthermore, two sets of benchmark functions consisting of forty-seven (47) classical and over thirty (30) constrained IEEE CEC-2017 benchmark functions are investigated numerically. The results indicate that the performance of the proposed algorithm is competitive with other state-of-the-art optimization methods based on scalability analysis, convergence analysis, and sensitivity analysis. Extensive simulation results indicate that the EOSA outperforms other state-of-the-art popular metaheuristic optimization algorithms such as the Particle Swarm Optimization Algorithm (PSO), Genetic Algorithm (GA), and Artificial Bee Colony Algorithm (ABC) on some shifted, high dimensional and large search range problems.
Hybrid symbiotic organisms search feedforward neural network model for stock price prediction
Jun 27, 2019
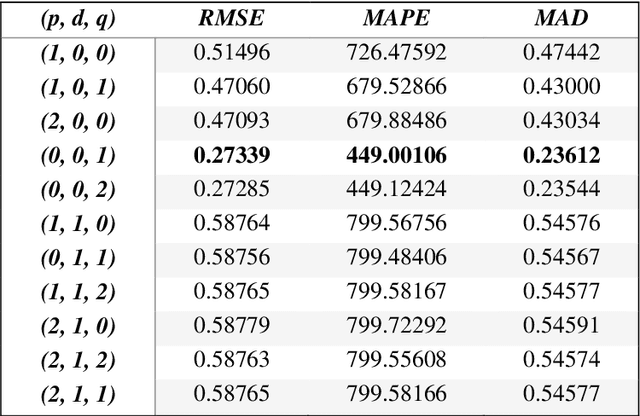
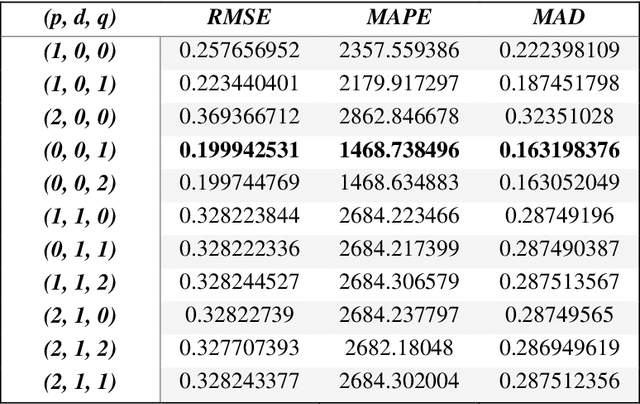
The prediction of stock prices is an important task in economics, investment and financial decision-making. It has for several decades, spurred the interest of many researchers to design stock price predictive models. In this paper, the symbiotic organisms search algorithm, a new metaheuristic algorithm is employed as an efficient method for training feedforward neural networks (FFNN). The training process is used to build a better stock price predictive model. The Straits Times Index, Nikkei 225, NASDAQ Composite, S&P 500, and Dow Jones Industrial Average indices were utilized as time series data sets for training and testing proposed predic-tive model. Three evaluation methods namely, Root Mean Squared Error, Mean Absolute Percentage Error and Mean Absolution Deviation are used to compare the results of the implemented model. The computational results obtained revealed that the hybrid Symbiotic Organisms Search Algorithm exhibited outstanding predictive performance when compared to the hybrid Particle Swarm Optimization, Genetic Algorithm, and ARIMA based models. The new model is a promising predictive technique for solving high dimensional nonlinear time series data that are difficult to capture by traditional models.