 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Tiny Recursion Model (ViTRM): Parameter-Efficient Image Classification via Recursive State Refinement
Mar 19, 2026The success of deep learning in computer vision has been driven by models of increasing scale, from deep Convolutional Neural Networks (CNN) to large Vision Transformers (ViT). While effective, these architectures are parameter-intensive and demand significant computational resources, limiting deployment in resource-constrained environments. Inspired by Tiny Recursive Models (TRM), which show that small recursive networks can solve complex reasoning tasks through iterative state refinement, we introduce the \textbf{Vision Tiny Recursion Model (ViTRM)}: a parameter-efficient architecture that replaces the $L$-layer ViT encoder with a single tiny $k$-layer block ($k{=}3$) applied recursively $N$ times. Despite using up to $6 \times $ and $84 \times$ fewer parameters than CNN based models and ViT respectively, ViTRM maintains competitive performance on CIFAR-10 and CIFAR-100. This demonstrates that recursive computation is a viable, parameter-efficient alternative to architectural depth in vision.
Analysis and Comparison of Two-Level KFAC Methods for Training Deep Neural Networks
Apr 03, 2023As a second-order method, the Natural Gradient Descent (NGD) has the ability to accelerate training of neural networks. However, due to the prohibitive computational and memory costs of computing and inverting the Fisher Information Matrix (FIM), efficient approximations are necessary to make NGD scalable to Deep Neural Networks (DNNs). Many such approximations have been attempted. The most sophisticated of these is KFAC, which approximates the FIM as a block-diagonal matrix, where each block corresponds to a layer of the neural network. By doing so, KFAC ignores the interactions between different layers. In this work, we investigate the interest of restoring some low-frequency interactions between the layers by means of two-level methods. Inspired from domain decomposition, several two-level corrections to KFAC using different coarse spaces are proposed and assessed. The obtained results show that incorporating the layer interactions in this fashion does not really improve the performance of KFAC. This suggests that it is safe to discard the off-diagonal blocks of the FIM, since the block-diagonal approach is sufficiently robust, accurate and economical in computation time.
Efficient Approximations of the Fisher Matrix in Neural Networks using Kronecker Product Singular Value Decomposition
Feb 02, 2022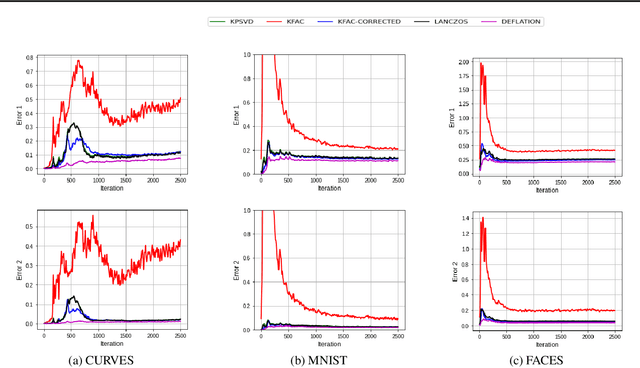
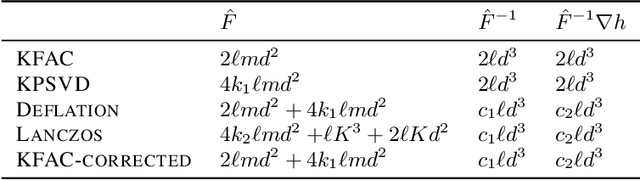
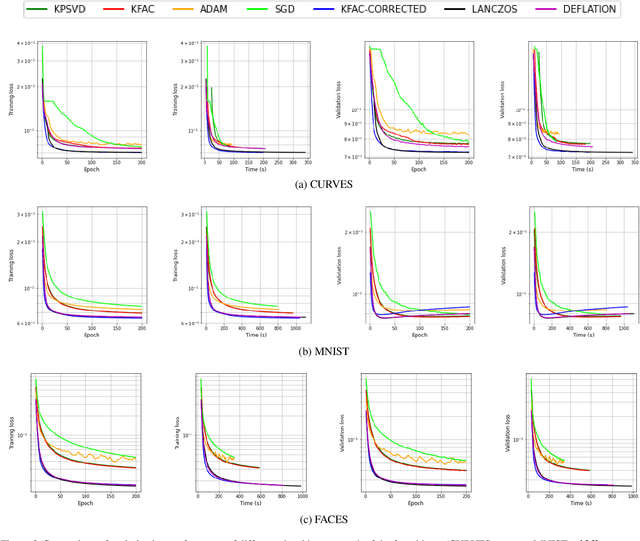
Several studies have shown the ability of natural gradient descent to minimize the objective function more efficiently than ordinary gradient descent based methods. However, the bottleneck of this approach for training deep neural networks lies in the prohibitive cost of solving a large dense linear system corresponding to the Fisher Information Matrix (FIM) at each iteration. This has motivated various approximations of either the exact FIM or the empirical one. The most sophisticated of these is KFAC, which involves a Kronecker-factored block diagonal approximation of the FIM. With only a slight additional cost, a few improvements of KFAC from the standpoint of accuracy are proposed. The common feature of the four novel methods is that they rely on a direct minimization problem, the solution of which can be computed via the Kronecker product singular value decomposition technique. Experimental results on the three standard deep auto-encoder benchmarks showed that they provide more accurate approximations to the FIM. Furthermore, they outperform KFAC and state-of-the-art first-order methods in terms of optimization speed.