 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarijaBanking: A New Resource for Overcoming Language Barriers in Banking Intent Detection for Moroccan Arabic Speakers
May 26, 2024



Navigating the complexities of language diversity is a central challenge in developing robust natural language processing systems, especially in specialized domains like banking. The Moroccan Dialect (Darija) serves as the common language that blends cultural complexities, historical impacts, and regional differences. The complexities of Darija present a special set of challenges for language models, as it differs from Modern Standard Arabic with strong influence from French, Spanish, and Tamazight, it requires a specific approach for effective communication. To tackle these challenges, this paper introduces \textbf{DarijaBanking}, a novel Darija dataset aimed at enhancing intent classification in the banking domain, addressing the critical need for automatic banking systems (e.g., chatbots) that communicate in the native language of Moroccan clients. DarijaBanking comprises over 1,800 parallel high-quality queries in Darija, Modern Standard Arabic (MSA), English, and French, organized into 24 intent classes. We experimented with various intent classification methods, including full fine-tuning of monolingual and multilingual models, zero-shot learning, retrieval-based approaches, and Large Language Model prompting. One of the main contributions of this work is BERTouch, our BERT-based language model for intent classification in Darija. BERTouch achieved F1-scores of 0.98 for Darija and 0.96 for MSA on DarijaBanking, outperforming the state-of-the-art alternatives including GPT-4 showcasing its effectiveness in the targeted application.
Arabic Text Diacritization In The Age Of Transfer Learning: Token Classification Is All You Need
Jan 09, 2024



Automatic diacritization of Arabic text involves adding diacritical marks (diacritics) to the text. This task poses a significant challenge with noteworthy implications for computational processing and comprehension. In this paper, we introduce PTCAD (Pre-FineTuned Token Classification for Arabic Diacritization, a novel two-phase approach for the Arabic Text Diacritization task. PTCAD comprises a pre-finetuning phase and a finetuning phase, treating Arabic Text Diacritization as a token classification task for pre-trained models. The effectiveness of PTCAD is demonstrated through evaluations on two benchmark datasets derived from the Tashkeela dataset, where it achieves state-of-the-art results, including a 20\% reduction in Word Error Rate (WER) compared to existing benchmarks and superior performance over GPT-4 in ATD tasks.
CS-UM6P at SemEval-2022 Task 6: Transformer-based Models for Intended Sarcasm Detection in English and Arabic
Jun 16, 2022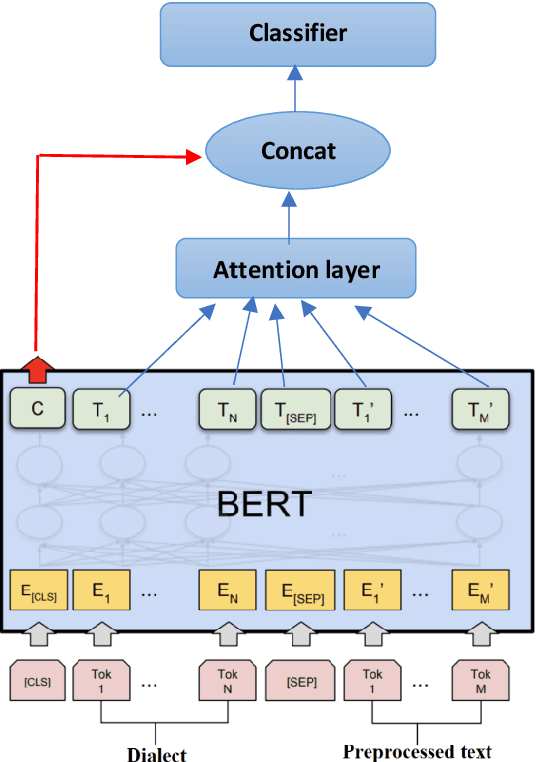
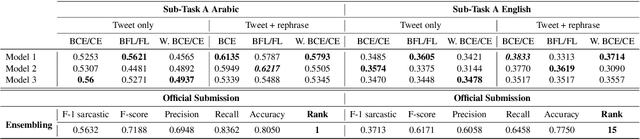

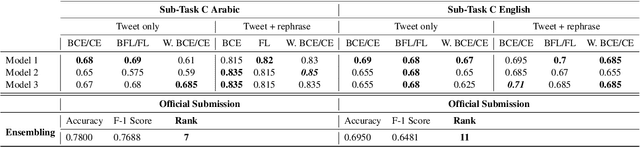
Sarcasm is a form of figurative language where the intended meaning of a sentence differs from its literal meaning. This poses a serious challenge to several Natural Language Processing (NLP) applications such as Sentiment Analysis, Opinion Mining, and Author Profiling. In this paper, we present our participating system to the intended sarcasm detection task in English and Arabic languages. Our system\footnote{The source code of our system is available at \url{https://github.com/AbdelkaderMH/iSarcasmEval}} consists of three deep learning-based models leveraging two existing pre-trained language models for Arabic and English. We have participated in all sub-tasks. Our official submissions achieve the best performance on sub-task A for Arabic language and rank second in sub-task B. For sub-task C, our system is ranked 7th and 11th on Arabic and English datasets, respectively.