 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment Multicalibration for Uncertainty Estimation
Aug 18, 2020We show how to achieve the notion of "multicalibration" from H\'ebert-Johnson et al. [2018] not just for means, but also for variances and other higher moments. Informally, it means that we can find regression functions which, given a data point, can make point predictions not just for the expectation of its label, but for higher moments of its label distribution as well-and those predictions match the true distribution quantities when averaged not just over the population as a whole, but also when averaged over an enormous number of finely defined subgroups. It yields a principled way to estimate the uncertainty of predictions on many different subgroups-and to diagnose potential sources of unfairness in the predictive power of features across subgroups. As an application, we show that our moment estimates can be used to derive marginal prediction intervals that are simultaneously valid as averaged over all of the (sufficiently large) subgroups for which moment multicalibration has been obtained.
Descent-to-Delete: Gradient-Based Methods for Machine Unlearning
Jul 06, 2020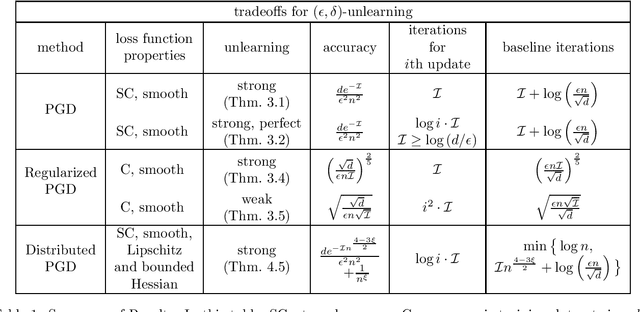
We study the data deletion problem for convex models. By leveraging techniques from convex optimization and reservoir sampling, we give the first data deletion algorithms that are able to handle an arbitrarily long sequence of adversarial updates while promising both per-deletion run-time and steady-state error that do not grow with the length of the update sequence. We also introduce several new conceptual distinctions: for example, we can ask that after a deletion, the entire state maintained by the optimization algorithm is statistically indistinguishable from the state that would have resulted had we retrained, or we can ask for the weaker condition that only the observable output is statistically indistinguishable from the observable output that would have resulted from retraining. We are able to give more efficient deletion algorithms under this weaker deletion criterion.
Algorithms and Learning for Fair Portfolio Design
Jun 12, 2020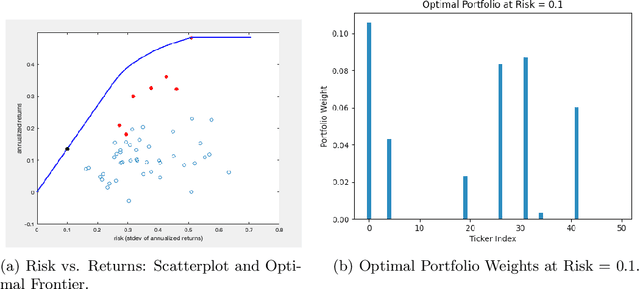
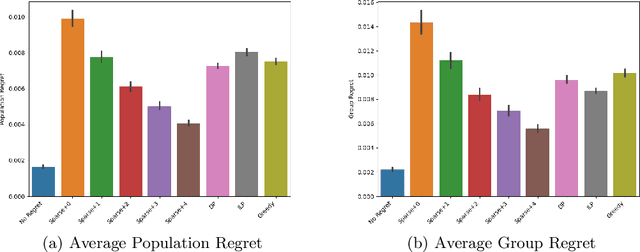
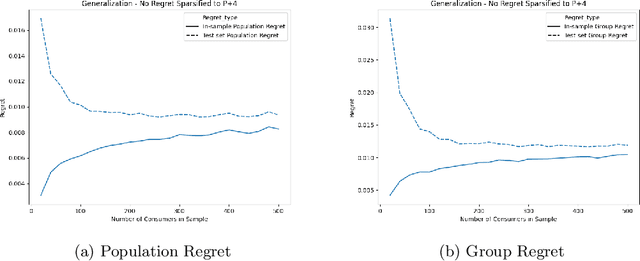
We consider a variation on the classical finance problem of optimal portfolio design. In our setting, a large population of consumers is drawn from some distribution over risk tolerances, and each consumer must be assigned to a portfolio of lower risk than her tolerance. The consumers may also belong to underlying groups (for instance, of demographic properties or wealth), and the goal is to design a small number of portfolios that are fair across groups in a particular and natural technical sense. Our main results are algorithms for optimal and near-optimal portfolio design for both social welfare and fairness objectives, both with and without assumptions on the underlying group structure. We describe an efficient algorithm based on an internal two-player zero-sum game that learns near-optimal fair portfolios ex ante and show experimentally that it can be used to obtain a small set of fair portfolios ex post as well. For the special but natural case in which group structure coincides with risk tolerances (which models the reality that wealthy consumers generally tolerate greater risk), we give an efficient and optimal fair algorithm. We also provide generalization guarantees for the underlying risk distribution that has no dependence on the number of portfolios and illustrate the theory with simulation results.
Fair Prediction with Endogenous Behavior
Feb 18, 2020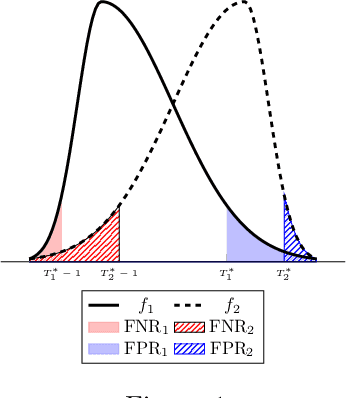
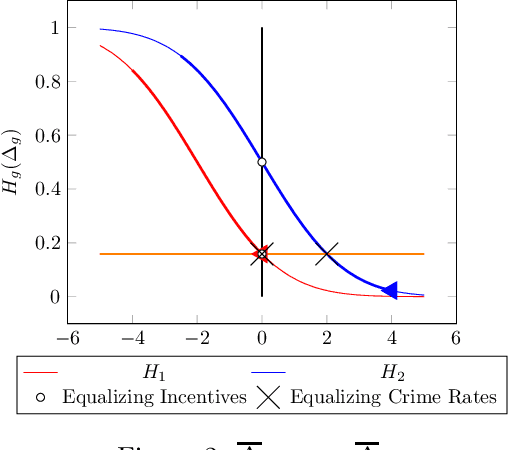
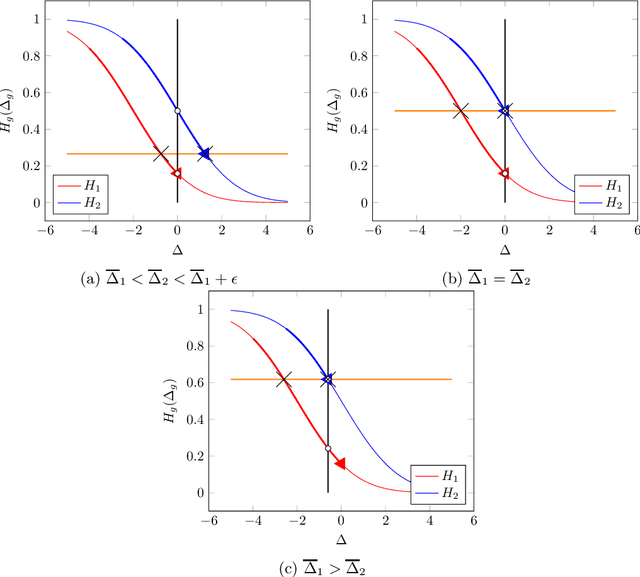
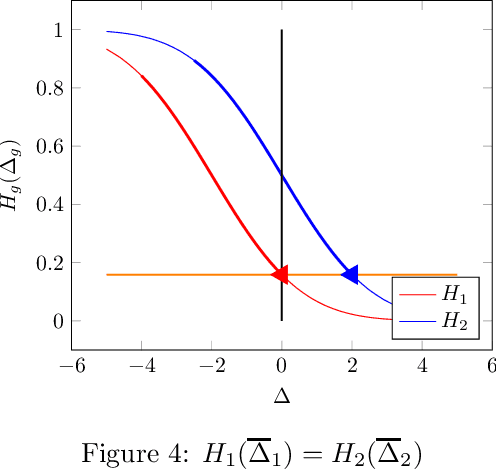
There is increasing regulatory interest in whether machine learning algorithms deployed in consequential domains (e.g. in criminal justice) treat different demographic groups "fairly." However, there are several proposed notions of fairness, typically mutually incompatible. Using criminal justice as an example, we study a model in which society chooses an incarceration rule. Agents of different demographic groups differ in their outside options (e.g. opportunity for legal employment) and decide whether to commit crimes. We show that equalizing type I and type II errors across groups is consistent with the goal of minimizing the overall crime rate; other popular notions of fairness are not.
Pipeline Interventions
Feb 16, 2020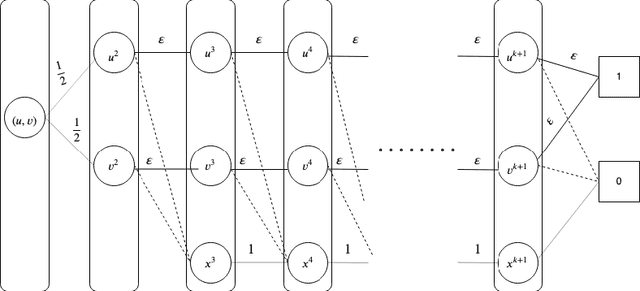
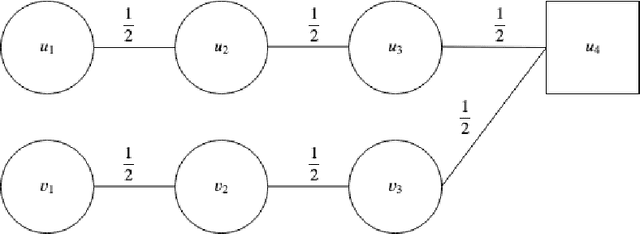
We introduce the \emph{pipeline intervention} problem, defined by a layered directed acyclic graph and a set of stochastic matrices governing transitions between successive layers. The graph is a stylized model for how people from different populations are presented opportunities, eventually leading to some reward. In our model, individuals are born into an initial position (i.e. some node in the first layer of the graph) according to a fixed probability distribution, and then stochastically progress through the graph according to the transition matrices, until they reach a node in the final layer of the graph; each node in the final layer has a \emph{reward} associated with it. The pipeline intervention problem asks how to best make costly changes to the transition matrices governing people's stochastic transitions through the graph, subject to a budget constraint. We consider two objectives: social welfare maximization, and a fairness-motivated maximin objective that seeks to maximize the value to the population (starting node) with the \emph{least} expected value. We consider two variants of the maximin objective that turn out to be distinct, depending on whether we demand a deterministic solution or allow randomization. For each objective, we give an efficient approximation algorithm (an additive FPTAS) for constant width networks. We also tightly characterize the "price of fairness" in our setting: the ratio between the highest achievable social welfare and the highest social welfare consistent with a maximin optimal solution. Finally we show that for polynomial width networks, even approximating the maximin objective to any constant factor is NP hard, even for networks with constant depth. This shows that the restriction on the width in our positive results is essential.
Optimal, Truthful, and Private Securities Lending
Dec 12, 2019We consider a fundamental dynamic allocation problem motivated by the problem of $\textit{securities lending}$ in financial markets, the mechanism underlying the short selling of stocks. A lender would like to distribute a finite number of identical copies of some scarce resource to $n$ clients, each of whom has a private demand that is unknown to the lender. The lender would like to maximize the usage of the resource $\mbox{---}$ avoiding allocating more to a client than her true demand $\mbox{---}$ but is constrained to sell the resource at a pre-specified price per unit, and thus cannot use prices to incentivize truthful reporting. We first show that the Bayesian optimal algorithm for the one-shot problem $\mbox{---}$ which maximizes the resource's expected usage according to the posterior expectation of demand, given reports $\mbox{---}$ actually incentivizes truthful reporting as a dominant strategy. Because true demands in the securities lending problem are often sensitive information that the client would like to hide from competitors, we then consider the problem under the additional desideratum of (joint) differential privacy. We give an algorithm, based on simple dynamics for computing market equilibria, that is simultaneously private, approximately optimal, and approximately dominant-strategy truthful. Finally, we leverage this private algorithm to construct an approximately truthful, optimal mechanism for the extensive form multi-round auction where the lender does not have access to the true joint distributions between clients' requests and demands.
A New Analysis of Differential Privacy's Generalization Guarantees
Sep 09, 2019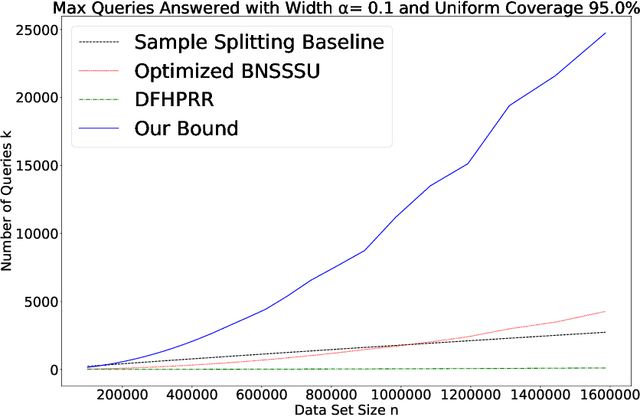
We give a new proof of the "transfer theorem" underlying adaptive data analysis: that any mechanism for answering adaptively chosen statistical queries that is differentially private and sample-accurate is also accurate out-of-sample. Our new proof is elementary and gives structural insights that we expect will be useful elsewhere. We show: 1) that differential privacy ensures that the expectation of any query on the posterior distribution on datasets induced by the transcript of the interaction is close to its true value on the data distribution, and 2) sample accuracy on its own ensures that any query answer produced by the mechanism is close to its posterior expectation with high probability. This second claim follows from a thought experiment in which we imagine that the dataset is resampled from the posterior distribution after the mechanism has committed to its answers. The transfer theorem then follows by summing these two bounds, and in particular, avoids the "monitor argument" used to derive high probability bounds in prior work. An upshot of our new proof technique is that the concrete bounds we obtain are substantially better than the best previously known bounds, even though the improvements are in the constants, rather than the asymptotics (which are known to be tight). As we show, our new bounds outperform the naive "sample-splitting" baseline at dramatically smaller dataset sizes compared to the previous state of the art, bringing techniques from this literature closer to practicality.
Differentially Private Objective Perturbation: Beyond Smoothness and Convexity
Sep 03, 2019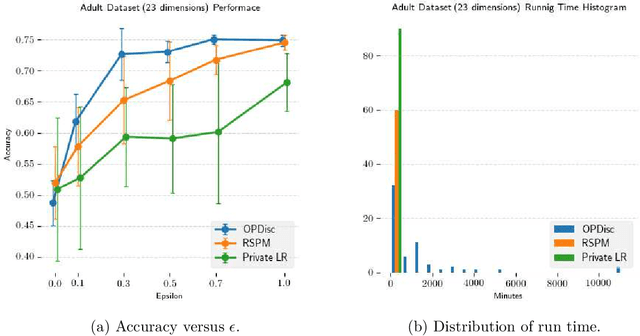
One of the most effective algorithms for differentially private learning and optimization is objective perturbation. This technique augments a given optimization problem (e.g. deriving from an ERM problem) with a random linear term, and then exactly solves it. However, to date, analyses of this approach crucially rely on the convexity and smoothness of the objective function. We give two algorithms that extend this approach substantially. The first algorithm requires nothing except boundedness of the loss function, and operates over a discrete domain. Its privacy and accuracy guarantees hold even without assuming convexity. The second algorithm operates over a continuous domain and requires only that the loss function be bounded and Lipschitz in its continuous parameter. Its privacy analysis does not even require convexity. Its accuracy analysis does require convexity, but does not require second order conditions like smoothness. We complement our theoretical results with an empirical evaluation of the non-convex case, in which we use an integer program solver as our optimization oracle. We find that for the problem of learning linear classifiers, directly optimizing for 0/1 loss using our approach can out-perform the more standard approach of privately optimizing a convex-surrogate loss function on the Adult dataset.
Exponential Separations in Local Differential Privacy Through Communication Complexity
Jul 01, 2019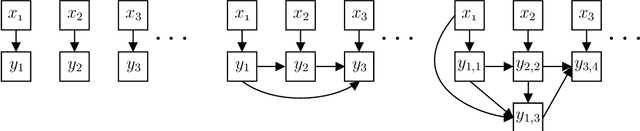
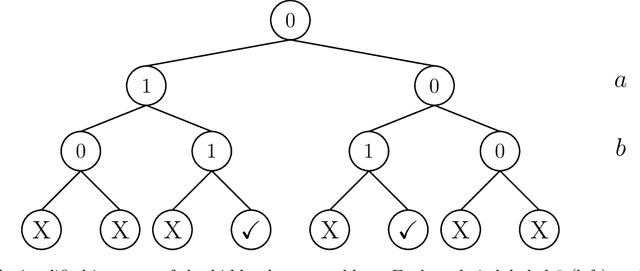
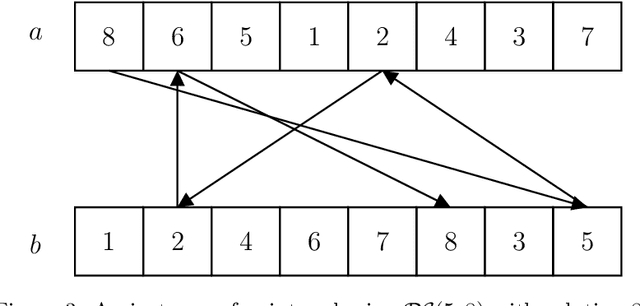
We prove a general connection between the communication complexity of two-player games and the sample complexity of their multi-player locally private analogues. We use this connection to prove sample complexity lower bounds for locally differentially private protocols as straightforward corollaries of results from communication complexity. In particular, we 1) use a communication lower bound for the hidden layers problem to prove an exponential sample complexity separation between sequentially and fully interactive locally private protocols, and 2) use a communication lower bound for the pointer chasing problem to prove an exponential sample complexity separation between $k$ round and $k+1$ round sequentially interactive locally private protocols, for every $k$.
Guaranteed Validity for Empirical Approaches to Adaptive Data Analysis
Jun 21, 2019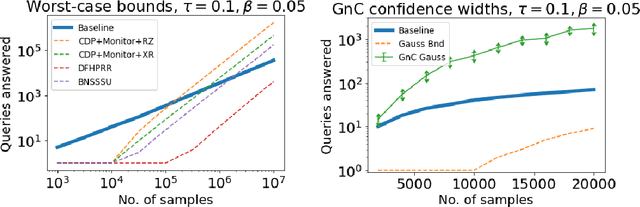
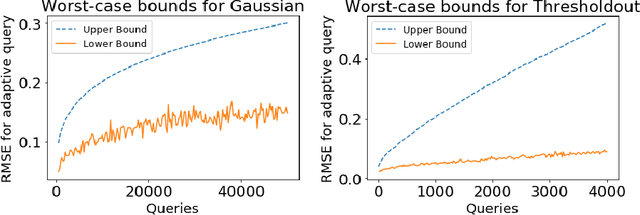
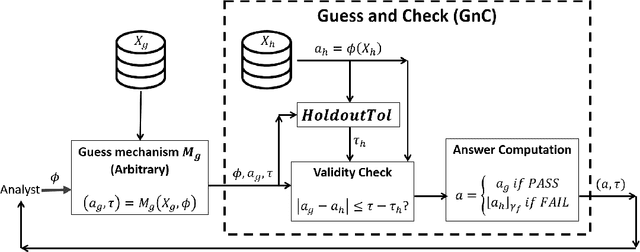
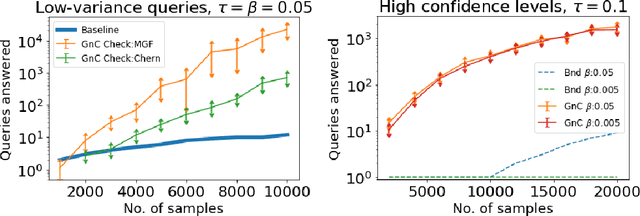
We design a general framework for answering adaptive statistical queries that focuses on providing explicit confidence intervals along with point estimates. Prior work in this area has either focused on providing tight confidence intervals for specific analyses, or providing general worst-case bounds for point estimates. Unfortunately, as we observe, these worst-case bounds are loose in many settings --- often not even beating simple baselines like sample splitting. Our main contribution is to design a framework for providing valid, instance-specific confidence intervals for point estimates that can be generated by heuristics. When paired with good heuristics, this method gives guarantees that are orders of magnitude better than the best worst-case bounds. We provide a Python library implementing our method.