 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures
May 30, 2019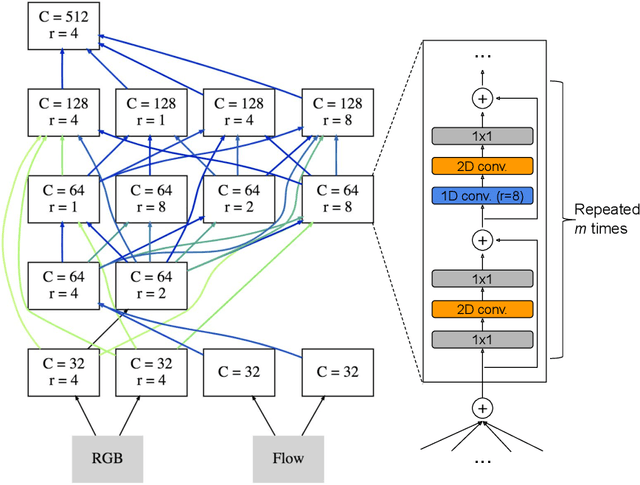
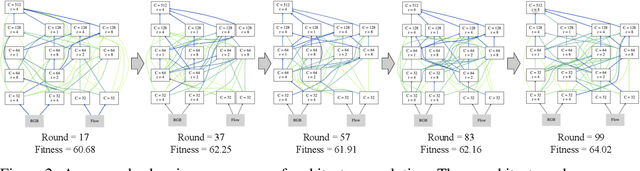
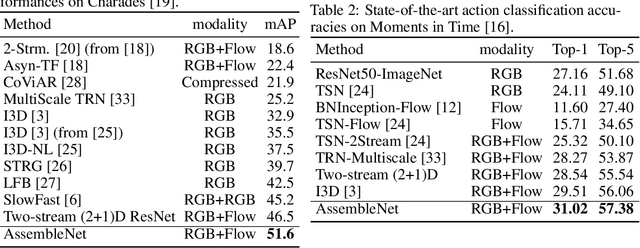
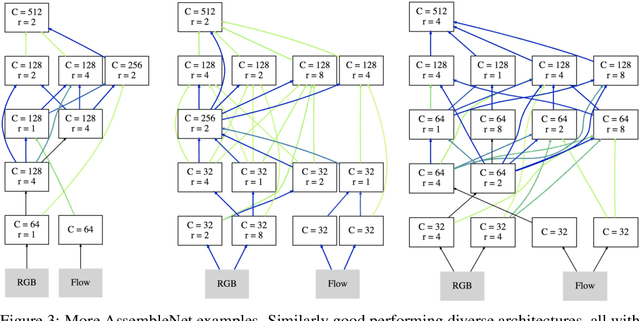
Learning to represent videos is a very challenging task both algorithmically and computationally. Standard video CNN architectures have been designed by directly extending architectures devised for image understanding to a third dimension (using a limited number of space-time modules such as 3D convolutions) or by introducing a handcrafted two-stream design to capture both appearance and motion in videos. We interpret a video CNN as a collection of multi-stream space-time convolutional blocks connected to each other, and propose the approach of automatically finding neural architectures with better connectivity for video understanding. This is done by evolving a population of overly-connected architectures guided by connection weight learning. Architectures combining representations that abstract different input types (i.e., RGB and optical flow) at multiple temporal resolutions are searched for, allowing different types or sources of information to interact with each other. Our method, referred to as AssembleNet, outperforms prior approaches on public video datasets, in some cases by a great margin.
Early Detection of Injuries in MLB Pitchers from Video
Apr 18, 2019
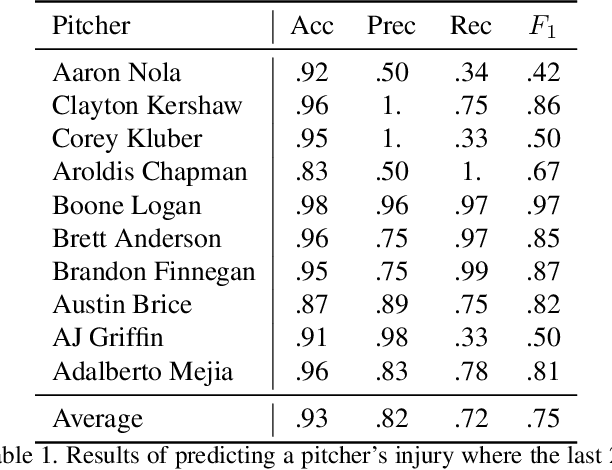

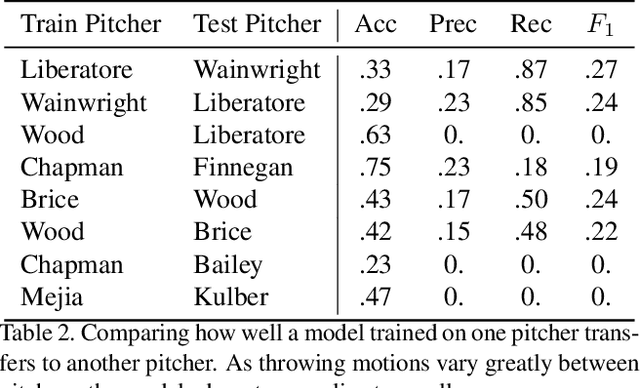
Injuries are a major cost in sports. Teams spend millions of dollars every year on players who are hurt and unable to play, resulting in lost games, decreased fan interest and additional wages for replacement players. Modern convolutional neural networks have been successfully applied to many video recognition tasks. In this paper, we introduce the problem of injury detection/prediction in MLB pitchers and experimentally evaluate the ability of such convolutional models to detect and predict injuries in pitches only from video data. We conduct experiments on a large dataset of TV broadcast MLB videos of 20 different pitchers who were injured during the 2017 season. We experimentally evaluate the model's performance on each individual pitcher, how well it generalizes to new pitchers, how it performs for various injuries, and how early it can predict or detect an injury.
Learning Differentiable Grammars for Continuous Data
Feb 01, 2019
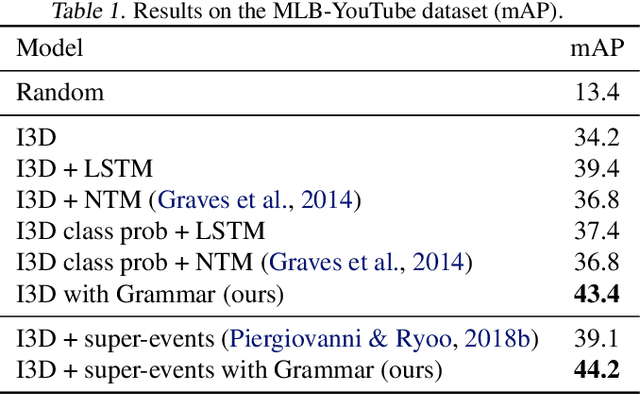
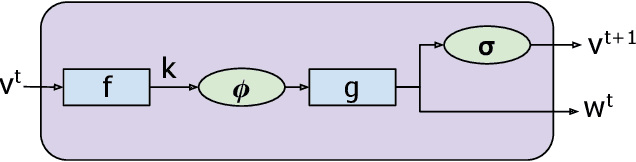
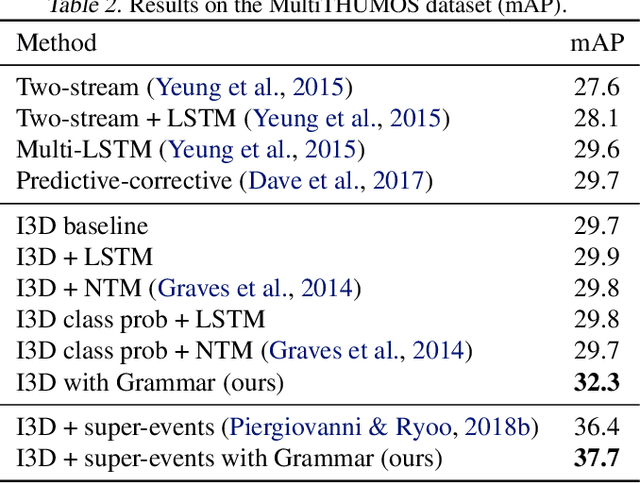
This paper proposes a novel algorithm which learns a formal regular grammar from real-world continuous data, such as videos or other streaming data. Learning latent terminals, non-terminals, and productions rules directly from streaming data allows the construction of a generative model capturing sequential structures with multiple possibilities. Our model is fully differentiable, and provides easily interpretable results which are important in order to understand the learned structures. It outperforms the state-of-the-art on several challenging datasets and is more accurate for forecasting future activities in videos. We plan to open-source the code.
Evolving Space-Time Neural Architectures for Videos
Nov 26, 2018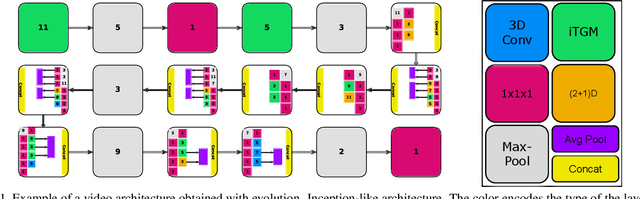
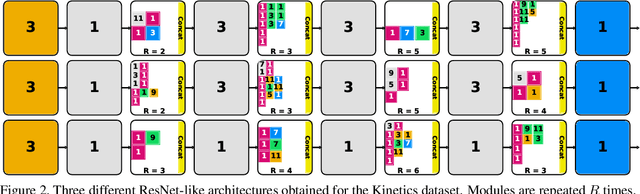
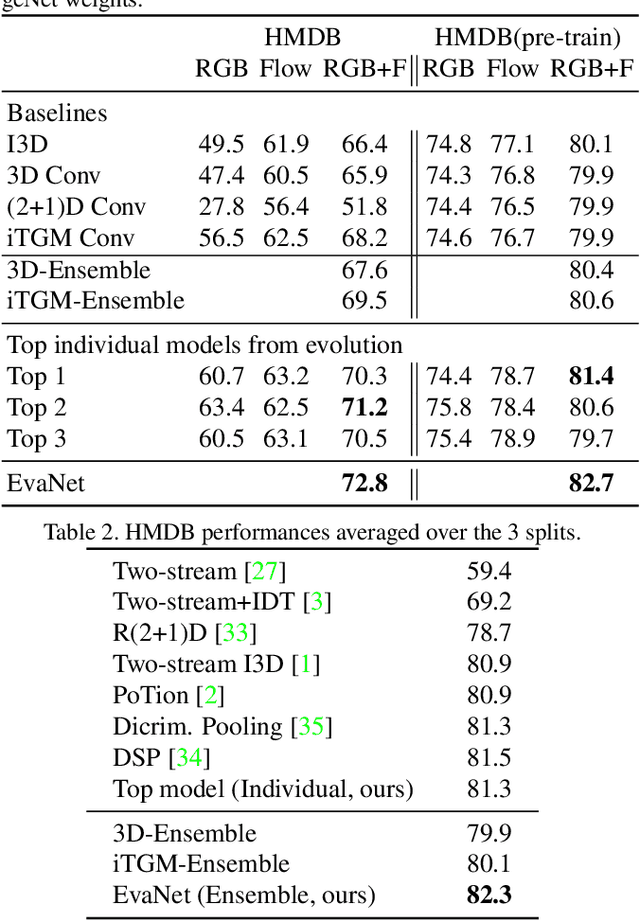
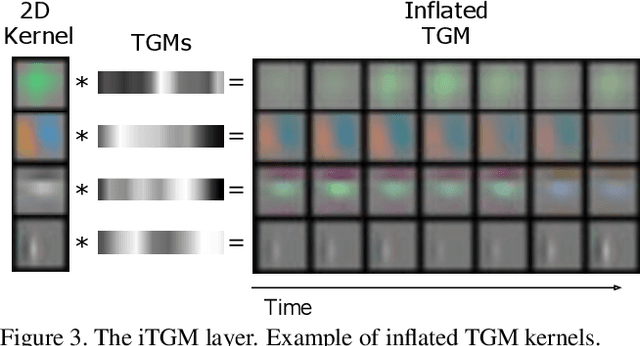
In this paper, we present a new method for evolving video CNN models to find architectures that more optimally captures rich spatio-temporal information in videos. Previous work, taking advantage of 3D convolutional layers, obtained promising results by manually designing CNN architectures for videos. We here develop an evolutionary algorithm that automatically explores models with different types and combinations of space-time convolutional layers to jointly capture various spatial and temporal aspects of video representations. We further propose a new key component in video model evolution, the iTGM layer, which more efficiently utilizes its parameters to allow learning of space-time interactions over longer time horizons. The experiments confirm the advantages of our video CNN architecture evolution, with results outperforming previous state-of-the-art models. Our algorithm discovers new and interesting video architecture structures.
Representation Flow for Action Recognition
Oct 02, 2018
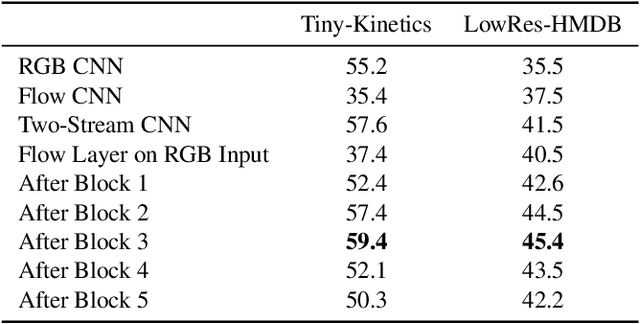
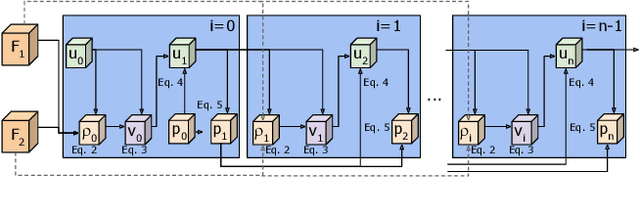
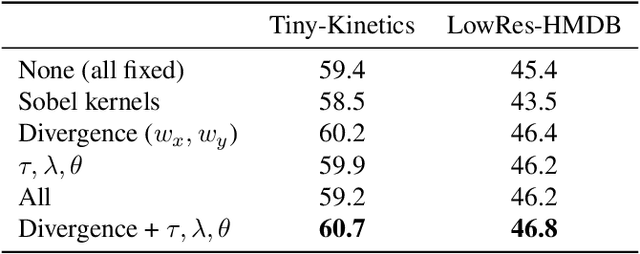
In this paper, we propose a convolutional layer inspired by optical flow algorithms to learn motion representations. Our representation flow layer is a fully-differentiable layer designed to optimally capture the `flow' of any representation channel within a convolutional neural network. Its parameters for iterative flow optimization are learned in an end-to-end fashion together with the other model parameters, maximizing the action recognition performance. Furthermore, we newly introduce the concept of learning `flow of flow' representations by stacking multiple representation flow layers. We conducted extensive experimental evaluations, confirming its advantages over previous recognition models using traditional optical flows in both computational speed and performance.
Unseen Action Recognition with Multimodal Learning
Oct 01, 2018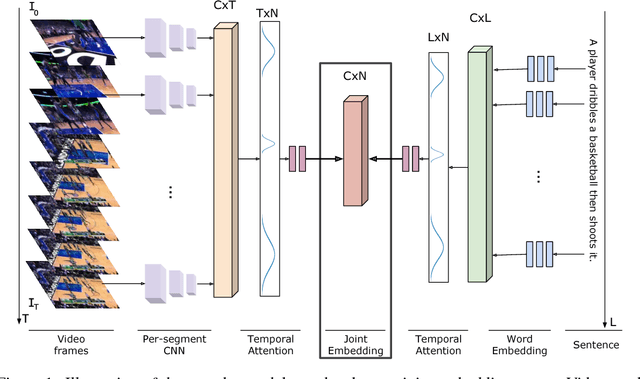
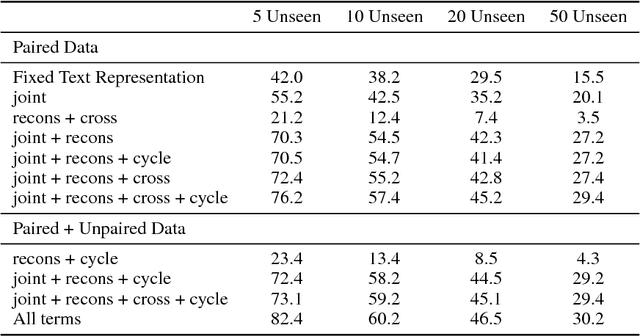

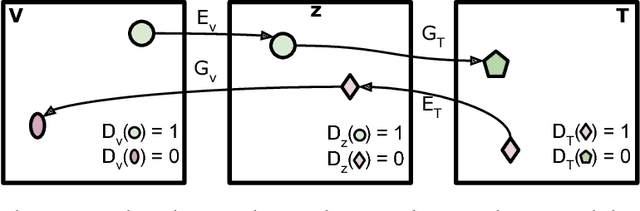
In this paper, we present a method to learn a joint multimodal representation space that allows for the recognition of unseen activities in videos. We compare the effect of placing various constraints on the embedding space using paired text and video data. Additionally, we propose a method to improve the joint embedding space using an adversarial formulation with unpaired text and video data. In addition to testing on publicly available datasets, we introduce a new, large-scale text/video dataset. We experimentally confirm that learning such shared embedding space benefits three difficult tasks (i) zero-shot activity classification, (ii) unsupervised activity discovery, and (iii) unseen activity captioning.
Temporal Gaussian Mixture Layer for Videos
Oct 01, 2018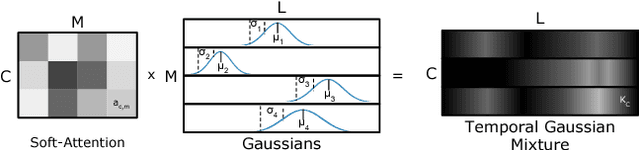
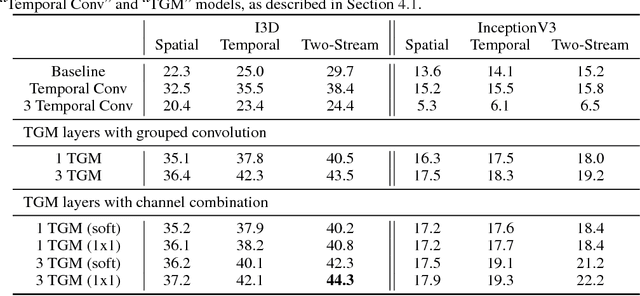
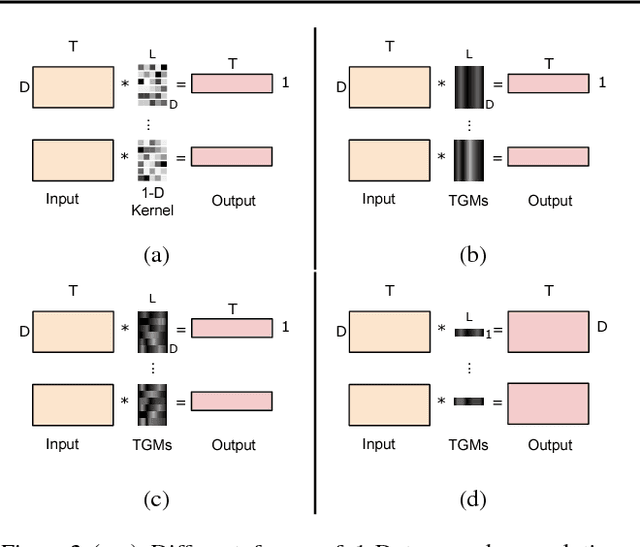

We introduce a new convolutional layer named the Temporal Gaussian Mixture (TGM) layer and present how it can be used to efficiently capture longer-term temporal information in continuous activity videos. The TGM layer is a temporal convolutional layer governed by a much smaller set of parameters (e.g., location/variance of Gaussians) that are fully differentiable. We present our fully convolutional video models with multiple TGM layers for activity detection. The experiments on multiple datasets including Charades and MultiTHUMOS confirm the effectiveness of TGM layers, outperforming the state-of-the-arts.
Learning Real-World Robot Policies by Dreaming
Sep 11, 2018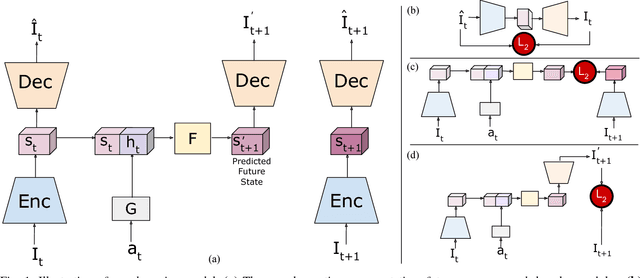
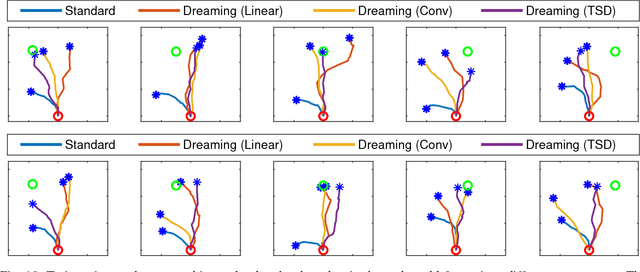
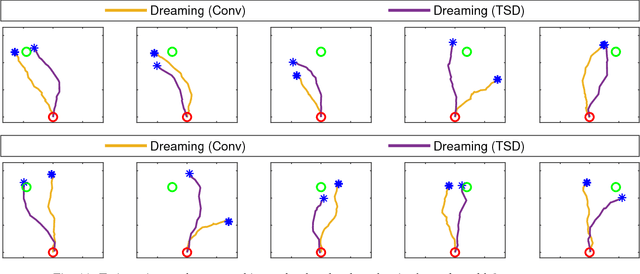
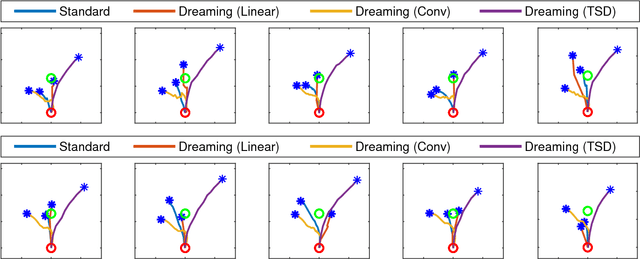
Learning to control robots directly based on images is a primary challenge in robotics. However, many existing reinforcement learning approaches require iteratively obtaining millions of samples to learn a policy which can take significant time. In this paper, we focus on the problem of learning real-world robot action policies solely based on a few random off-policy initial samples. We learn a realistic dreaming model that can emulate samples equivalent to a sequence of images from the actual environment, and make the agent learn action policies by interacting with the dreaming model rather than the real-world. We experimentally confirm that our dreaming model can learn realistic policies that transfer to the real-world.
Fine-grained Activity Recognition in Baseball Videos
Apr 09, 2018
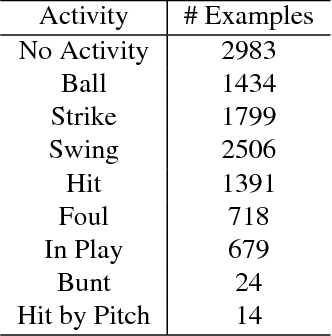

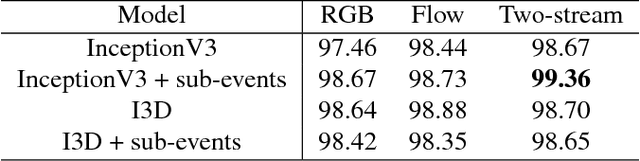
In this paper, we introduce a challenging new dataset, MLB-YouTube, designed for fine-grained activity detection. The dataset contains two settings: segmented video classification as well as activity detection in continuous videos. We experimentally compare various recognition approaches capturing temporal structure in activity videos, by classifying segmented videos and extending those approaches to continuous videos. We also compare models on the extremely difficult task of predicting pitch speed and pitch type from broadcast baseball videos. We find that learning temporal structure is valuable for fine-grained activity recognition.
* CVPR Workshop on Computer Vision in Sports
Learning Latent Super-Events to Detect Multiple Activities in Videos
Mar 29, 2018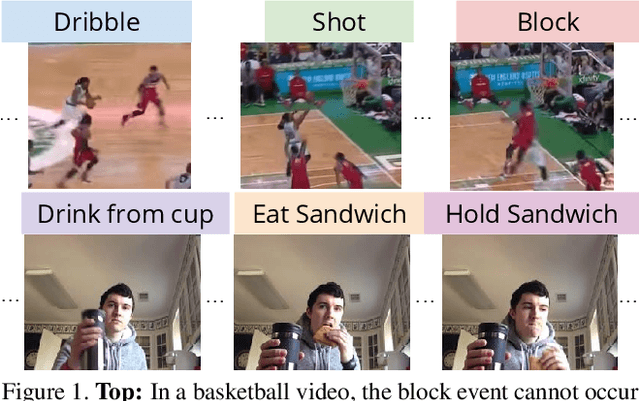

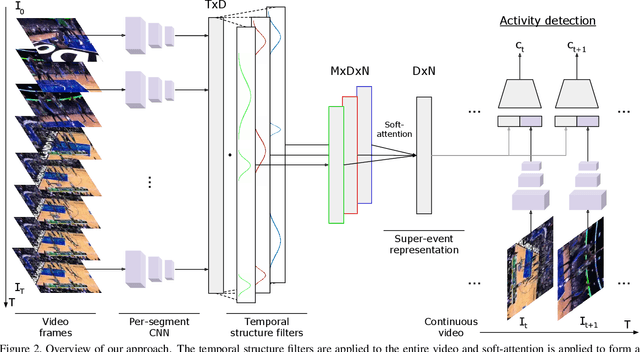

In this paper, we introduce the concept of learning latent super-events from activity videos, and present how it benefits activity detection in continuous videos. We define a super-event as a set of multiple events occurring together in videos with a particular temporal organization; it is the opposite concept of sub-events. Real-world videos contain multiple activities and are rarely segmented (e.g., surveillance videos), and learning latent super-events allows the model to capture how the events are temporally related in videos. We design temporal structure filters that enable the model to focus on particular sub-intervals of the videos, and use them together with a soft attention mechanism to learn representations of latent super-events. Super-event representations are combined with per-frame or per-segment CNNs to provide frame-level annotations. Our approach is designed to be fully differentiable, enabling end-to-end learning of latent super-event representations jointly with the activity detector using them. Our experiments with multiple public video datasets confirm that the proposed concept of latent super-event learning significantly benefits activity detection, advancing the state-of-the-arts.
* CVPR 2018