 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Sampling Bias Correction: Training with the Right Loss Function
Jun 24, 2020

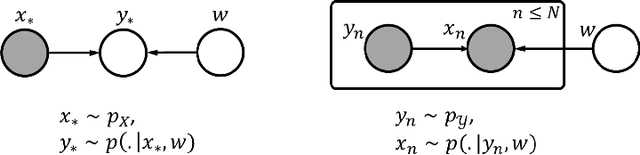
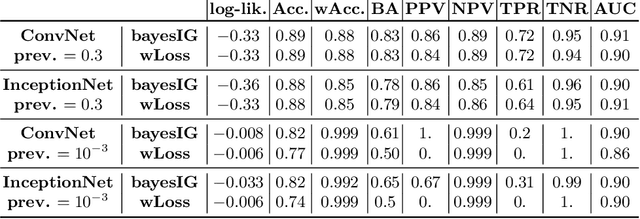
We derive a family of loss functions to train models in the presence of sampling bias. Examples are when the prevalence of a pathology differs from its sampling rate in the training dataset, or when a machine learning practioner rebalances their training dataset. Sampling bias causes large discrepancies between model performance in the lab and in more realistic settings. It is omnipresent in medical imaging applications, yet is often overlooked at training time or addressed on an ad-hoc basis. Our approach is based on Bayesian risk minimization. For arbitrary likelihood models we derive the associated bias corrected loss for training, exhibiting a direct connection to information gain. The approach integrates seamlessly in the current paradigm of (deep) learning using stochastic backpropagation and naturally with Bayesian models. We illustrate the methodology on case studies of lung nodule malignancy grading.
Using context to make gas classifiers robust to sensor drift
Mar 16, 2020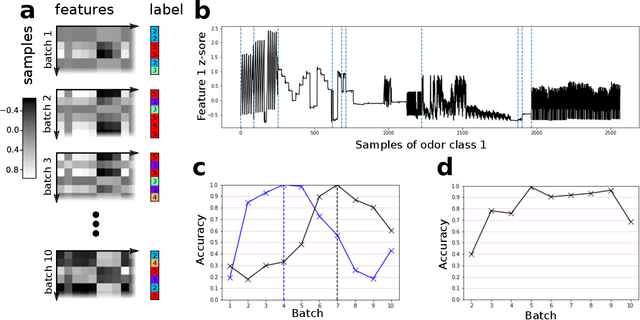
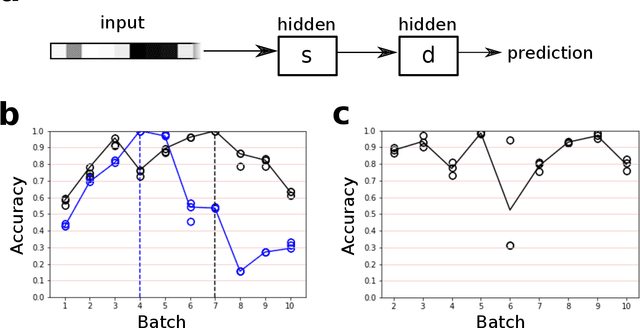
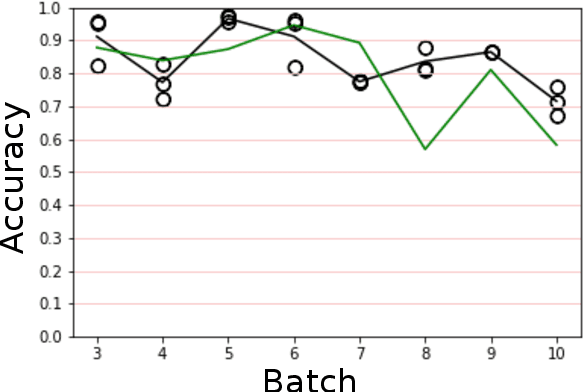
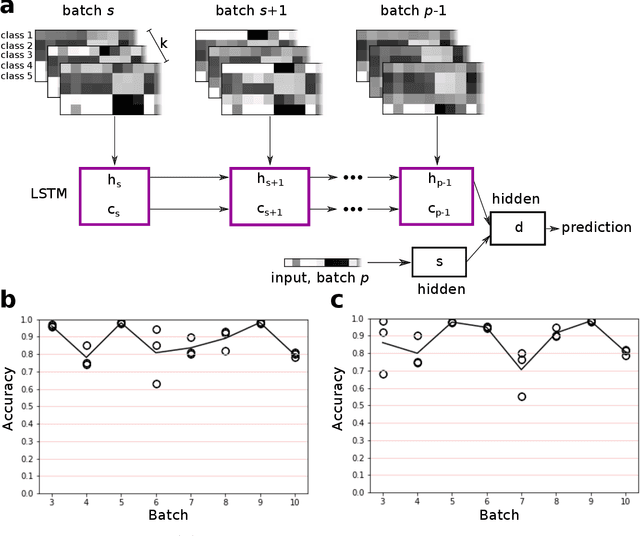
The interaction of a gas particle with a metal-oxide based gas sensor changes the sensor irreversibly. The compounded changes, referred to as sensor drift, are unstable, but adaptive algorithms can sustain the accuracy of odor sensor systems. Here we focus on extending the lifetime of sensor systems without additional data acquisition by transfering knowledge from one time window to a subsequent one after drift has occurred. To support generalization across sensor states, we introduce a context-based neural network model which forms a latent representation of sensor state. We tested our models to classify samples taken from unseen subsequent time windows and discovered favorable accuracy compared to drift-naive and ensemble methods on a gas sensor array drift dataset. By reducing the effect that sensor drift has on classification accuracy, context-based models may extend the effective lifetime of gas identification systems in practical settings.