 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor-Train Networks for Learning Predictive Modeling of Multidimensional Data
Jan 22, 2021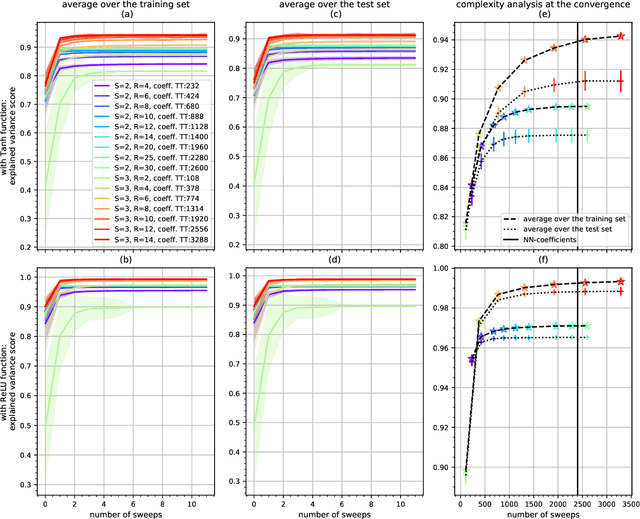
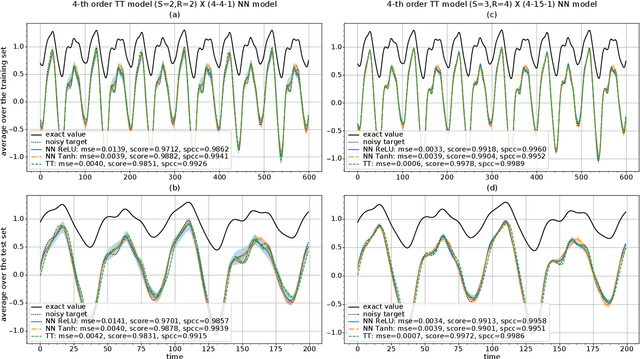
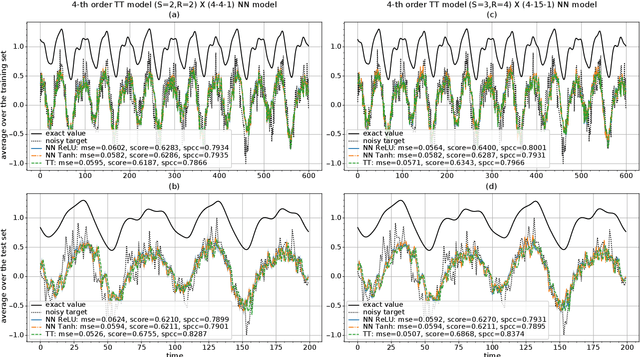
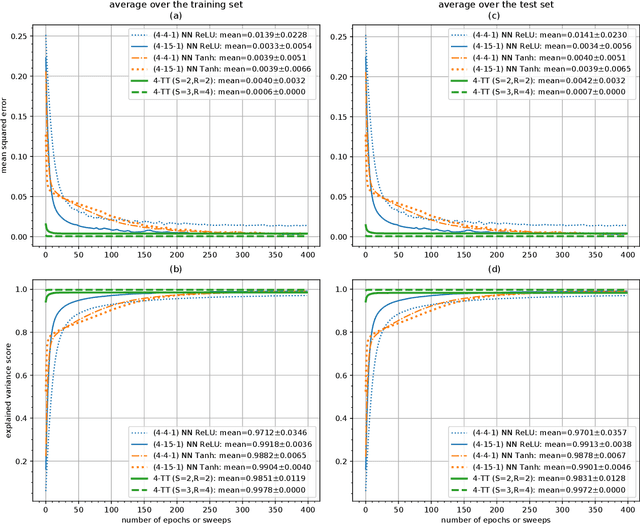
Deep neural networks have attracted the attention of the machine learning community because of their appealing data-driven framework and of their performance in several pattern recognition tasks. On the other hand, there are many open theoretical problems regarding the internal operation of the network, the necessity of certain layers, hyperparameter selection etc. A promising strategy is based on tensor networks, which have been very successful in physical and chemical applications. In general, higher-order tensors are decomposed into sparsely interconnected lower-order tensors. This is a numerically reliable way to avoid the curse of dimensionality and to provide highly compressed representation of a data tensor, besides the good numerical properties that allow to control the desired accuracy of approximation. In order to compare tensor and neural networks, we first consider the identification of the classical Multilayer Perceptron using Tensor-Train. A comparative analysis is also carried out in the context of prediction of the Mackey-Glass noisy chaotic time series and NASDAQ index. We have shown that the weights of a multidimensional regression model can be learned by means of tensor networks with the aim of performing a powerful compact representation retaining the accuracy of neural networks. Furthermore, an algorithm based on alternating least squares has been proposed for approximating the weights in TT-format with a reduction of computational calculus. By means of a direct expression, we have approximated the core estimation as the conventional solution for a general regression model, which allows to extend the applicability of tensor structures to different algorithms.
Tensor Networks for Dimensionality Reduction and Large-Scale Optimizations. Part 2 Applications and Future Perspectives
Aug 30, 2017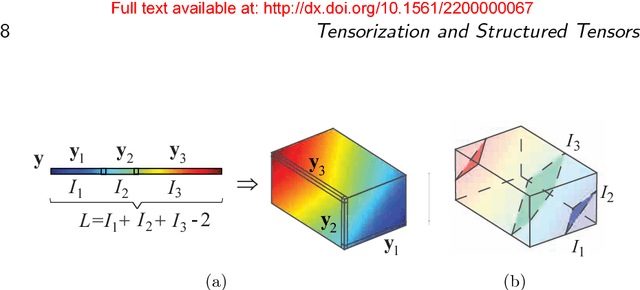

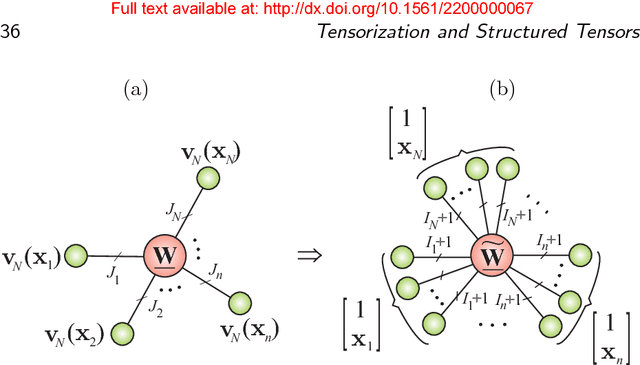
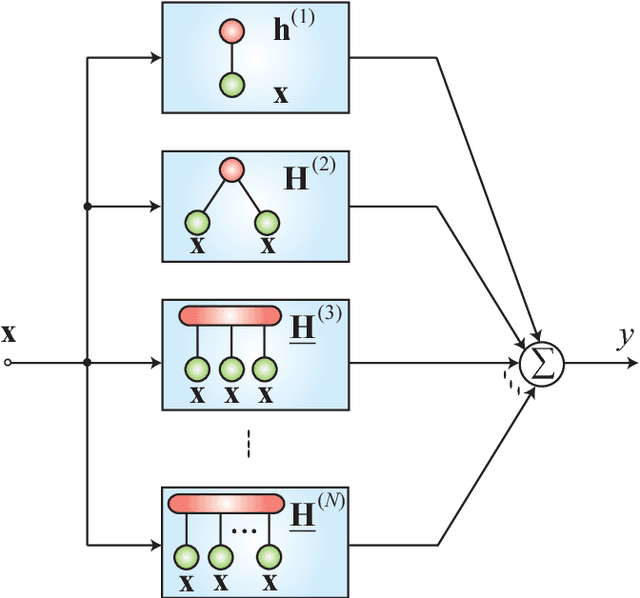
Part 2 of this monograph builds on the introduction to tensor networks and their operations presented in Part 1. It focuses on tensor network models for super-compressed higher-order representation of data/parameters and related cost functions, while providing an outline of their applications in machine learning and data analytics. A particular emphasis is on the tensor train (TT) and Hierarchical Tucker (HT) decompositions, and their physically meaningful interpretations which reflect the scalability of the tensor network approach. Through a graphical approach, we also elucidate how, by virtue of the underlying low-rank tensor approximations and sophisticated contractions of core tensors, tensor networks have the ability to perform distributed computations on otherwise prohibitively large volumes of data/parameters, thereby alleviating or even eliminating the curse of dimensionality. The usefulness of this concept is illustrated over a number of applied areas, including generalized regression and classification (support tensor machines, canonical correlation analysis, higher order partial least squares), generalized eigenvalue decomposition, Riemannian optimization, and in the optimization of deep neural networks. Part 1 and Part 2 of this work can be used either as stand-alone separate texts, or indeed as a conjoint comprehensive review of the exciting field of low-rank tensor networks and tensor decompositions.
* 232 pages