 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACL-Verbatim: hallucination-free question answering for research
May 20, 2026Academic researchers need efficient and reliable methods for collecting high-quality information from trusted sources, but modern tools for AI-assisted research still suffer from the tendency of Large Language Models (LLMs) to produce factually inaccurate or nonsensical output, commonly referred to as hallucinations. We apply the extractive question answering system VerbatimRAG to research papers in the ACL Anthology, directly mapping user queries to verbatim text spans in retrieved documents. We contribute a novel ground truth dataset for the task of mapping user queries to relevant text spans in research papers, and use it to train and evaluate a variety of extractive models. Human annotation is performed by NLP researchers and is based on synthetic user queries generated using a custom pipeline based on the ScIRGen methodology, paired with chunks of research papers retrieved by VerbatimRAG. On this benchmark, a 150M-parameter ModernBERT token classifier trained on silver supervision from our pipeline achieves the best word-level F1 (53.6), ahead of the strongest evaluated LLM extractor (48.7).
Squeez: Task-Conditioned Tool-Output Pruning for Coding Agents
Apr 04, 2026Coding agents repeatedly consume long tool observations even though only a small fraction of each observation matters for the next step. We study task-conditioned tool-output pruning: given a focused query and one tool output, return the smallest verbatim evidence block the agent should inspect next. We introduce a benchmark of 11,477 examples built from SWE-bench repository interactions and synthetic multi-ecosystem tool outputs, with a manually curated 618-example test set. We fine-tune Qwen 3.5 2B with LoRA and compare it against larger zero-shot models and heuristic pruning baselines. Our model reaches 0.86 recall and 0.80 F1 while removing 92% of input tokens, outperforming zero-shot Qwen 3.5 35B A3B by 11 recall points and all heuristic baselines by a wide margin.
LettuceDetect: A Hallucination Detection Framework for RAG Applications
Feb 24, 2025Retrieval Augmented Generation (RAG) systems remain vulnerable to hallucinated answers despite incorporating external knowledge sources. We present LettuceDetect a framework that addresses two critical limitations in existing hallucination detection methods: (1) the context window constraints of traditional encoder-based methods, and (2) the computational inefficiency of LLM based approaches. Building on ModernBERT's extended context capabilities (up to 8k tokens) and trained on the RAGTruth benchmark dataset, our approach outperforms all previous encoder-based models and most prompt-based models, while being approximately 30 times smaller than the best models. LettuceDetect is a token-classification model that processes context-question-answer triples, allowing for the identification of unsupported claims at the token level. Evaluations on the RAGTruth corpus demonstrate an F1 score of 79.22% for example-level detection, which is a 14.8% improvement over Luna, the previous state-of-the-art encoder-based architecture. Additionally, the system can process 30 to 60 examples per second on a single GPU, making it more practical for real-world RAG applications.
POTATO: exPlainable infOrmation exTrAcTion framewOrk
Jan 31, 2022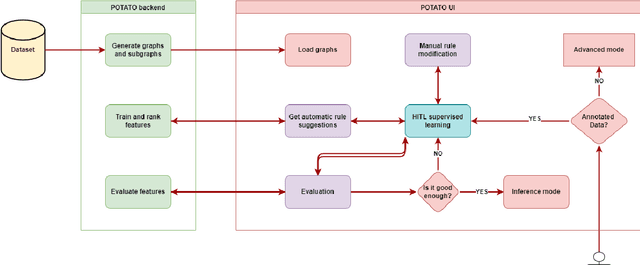
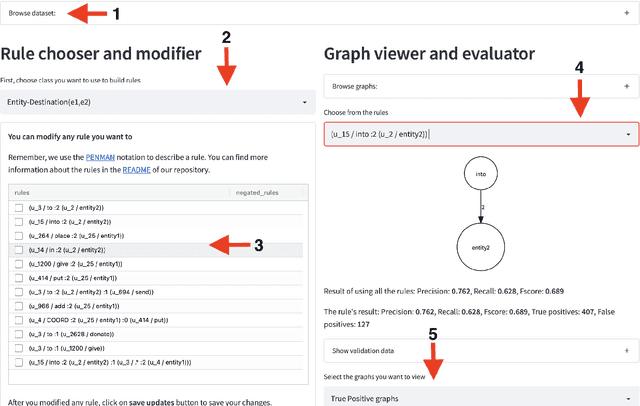
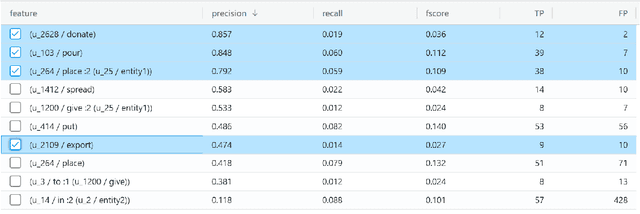
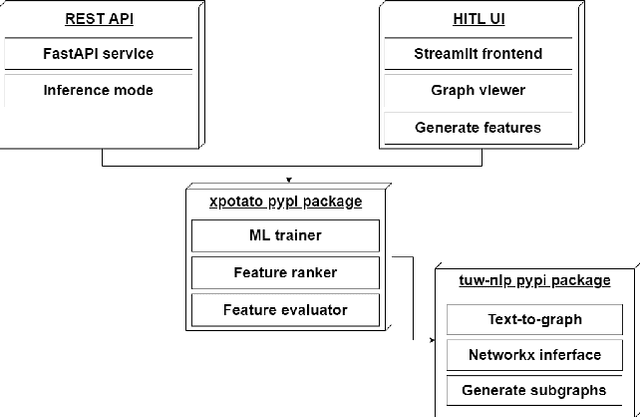
We present POTATO, a task- and languageindependent framework for human-in-the-loop (HITL) learning of rule-based text classifiers using graph-based features. POTATO handles any type of directed graph and supports parsing text into Abstract Meaning Representations (AMR), Universal Dependencies (UD), and 4lang semantic graphs. A streamlit-based user interface allows users to build rule systems from graph patterns, provides real-time evaluation based on ground truth data, and suggests rules by ranking graph features using interpretable machine learning models. Users can also provide patterns over graphs using regular expressions, and POTATO can recommend refinements of such rules. POTATO is applied in projects across domains and languages, including classification tasks on German legal text and English social media data. All components of our system are written in Python, can be installed via pip, and are released under an MIT License on GitHub.