 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Change Diffusion: Change Detection Map Generation Based on Difference-Feature Guided DDPM
Jun 06, 2023
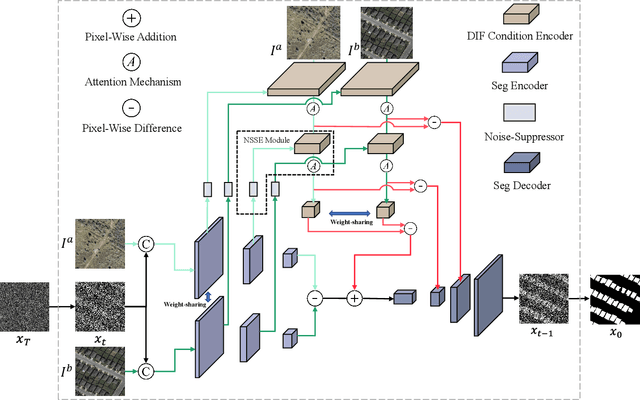
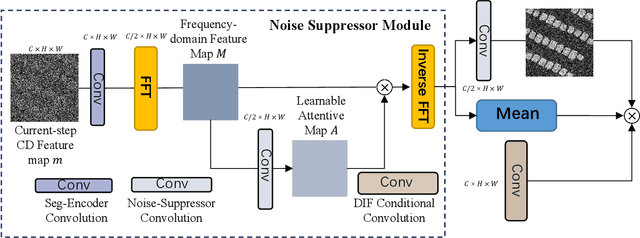


Deep learning (DL) approaches based on CNN-purely or Transformer networks have demonstrated promising results in bitemporal change detection (CD). However, their performance is limited by insufficient contextual information aggregation, as they struggle to fully capture the implicit contextual dependency relationships among feature maps at different levels. Additionally, researchers have utilized pre-trained denoising diffusion probabilistic models (DDPMs) for training lightweight CD classifiers. Nevertheless, training a DDPM to generate intricately detailed, multi-channel remote sensing images requires months of training time and a substantial volume of unlabeled remote sensing datasets, making it significantly more complex than generating a single-channel change map. To overcome these challenges, we propose a novel end-to-end DDPM-based model architecture called change-aware diffusion model (CADM), which can be trained using a limited annotated dataset quickly. Furthermore, we introduce dynamic difference conditional encoding to enhance step-wise regional attention in DDPM for bitemporal images in CD datasets. This method establishes state-adaptive conditions for each sampling step, emphasizing two main innovative points of our model: 1) its end-to-end nature and 2) difference conditional encoding. We evaluate CADM on four remote sensing CD tasks with different ground scenarios, including CDD, WHU, Levier, and GVLM. Experimental results demonstrate that CADM significantly outperforms state-of-the-art methods, indicating the generalization and effectiveness of the proposed model.
Towards End-to-end Speech-to-text Summarization
Jun 06, 2023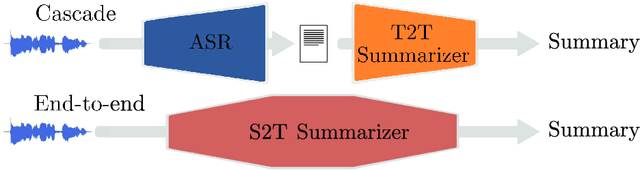

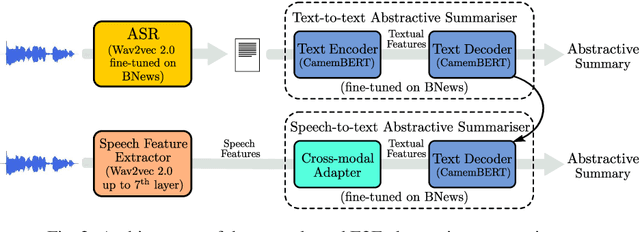
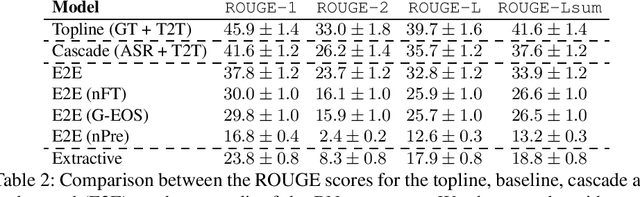
Speech-to-text (S2T) summarization is a time-saving technique for filtering and keeping up with the broadcast news uploaded online on a daily basis. The rise of large language models from deep learning with impressive text generation capabilities has placed the research focus on summarization systems that produce paraphrased compact versions of the document content, also known as abstractive summaries. End-to-end (E2E) modelling of S2T abstractive summarization is a promising approach that offers the possibility of generating rich latent representations that leverage non-verbal and acoustic information, as opposed to the use of only linguistic information from automatically generated transcripts in cascade systems. However, the few literature on E2E modelling of this task fails on exploring different domains, namely broadcast news, which is challenging domain where large and diversified volumes of data are presented to the user every day. We model S2T summarization both with a cascade and an E2E system for a corpus of broadcast news in French. Our novel E2E model leverages external data by resorting to transfer learning from a pre-trained T2T summarizer. Experiments show that both our cascade and E2E abstractive summarizers are stronger than an extractive baseline. However, the performance of the E2E model still lies behind the cascade one, which is object of an extensive analysis that includes future directions to close that gap.
Ultra-miniature dual-wavelength spatial frequency domain imaging for micro-endoscopy
Jun 06, 2023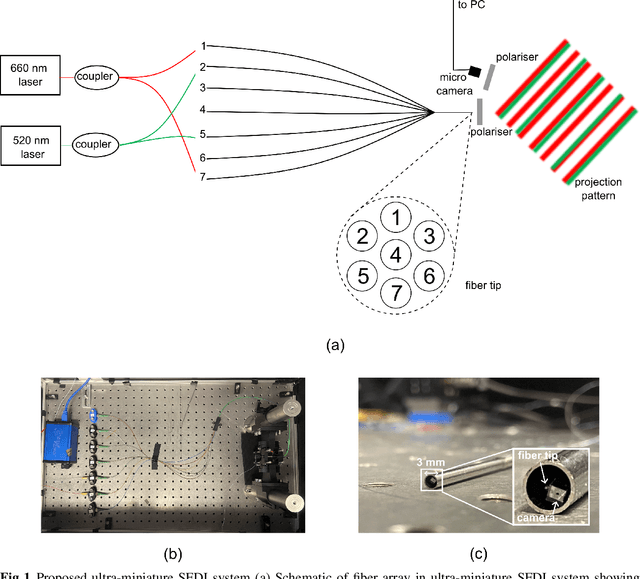
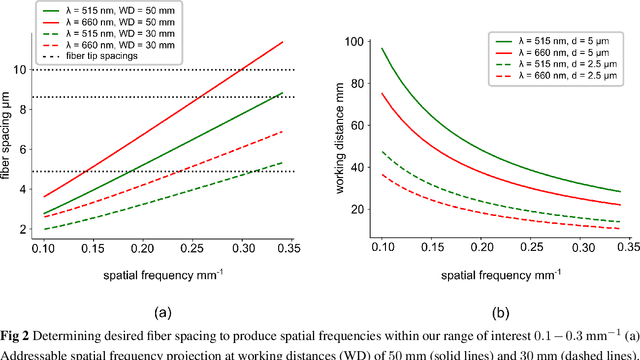
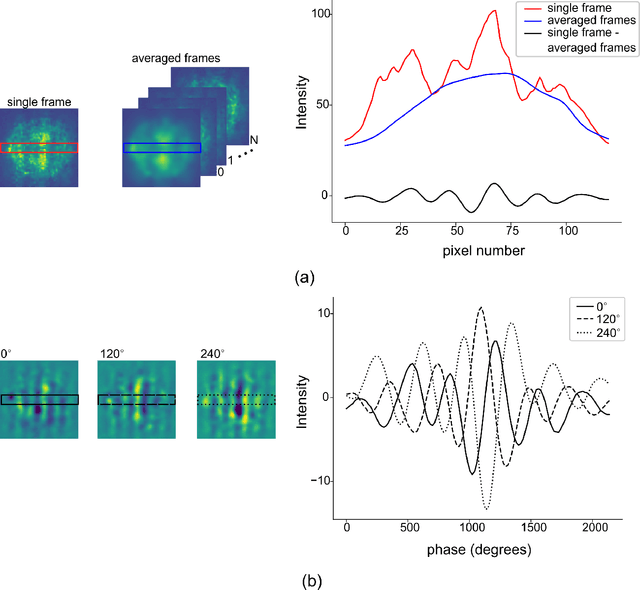
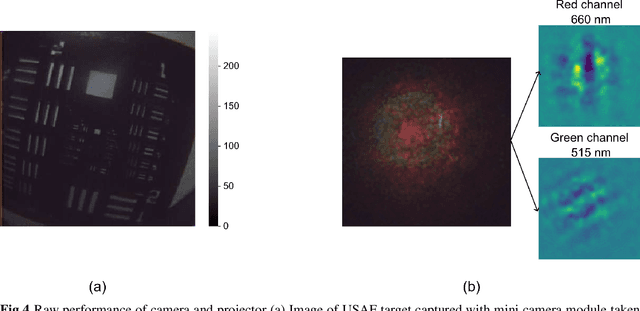
There is a need for a cost-effective, quantitative imaging tool that can be deployed endoscopically to better detect early stage gastrointestinal cancers. Spatial frequency domain imaging (SFDI) is a low-cost imaging technique that produces near-real time, quantitative maps of absorption and reduced scattering coefficients, but most implementations are bulky and suitable only for use outside the body. We present an ultra-miniature SFDI system comprised of an optical fiber array (diameter 0.125 mm) and a micro camera (1 x 1 mm package) displacing conventionally bulky components, in particular the projector. The prototype has outer diameter 3 mm, but the individual components dimensions could permit future packaging to < 1.5 mm diameter. We develop a phase-tracking algorithm to rapidly extract images with fringe projections at 3 equispaced phase shifts in order to perform SFDI demodulation. To validate performance, we first demonstrate comparable recovery of quantitative optical properties between our ultra-miniature system and a conventional bench-top SFDI system with agreement of 15% and 6% for absorption and reduced scattering respectively. Next, we demonstrate imaging of absorption and reduced scattering of tissue-mimicking phantoms providing enhanced contrast between simulated tissue types (healthy and tumour), done simultaneously at wavelengths of 515 nm and 660 nm. This device shows promise as a cost-effective, quantitative imaging tool to detect variations in optical absorption and scattering as indicators of cancer.
A Polynomial Time, Pure Differentially Private Estimator for Binary Product Distributions
Apr 19, 2023We present the first $\varepsilon$-differentially private, computationally efficient algorithm that estimates the means of product distributions over $\{0,1\}^d$ accurately in total-variation distance, whilst attaining the optimal sample complexity to within polylogarithmic factors. The prior work had either solved this problem efficiently and optimally under weaker notions of privacy, or had solved it optimally while having exponential running times.
Recent applications of machine learning, remote sensing, and iot approaches in yield prediction: a critical review
Jun 07, 2023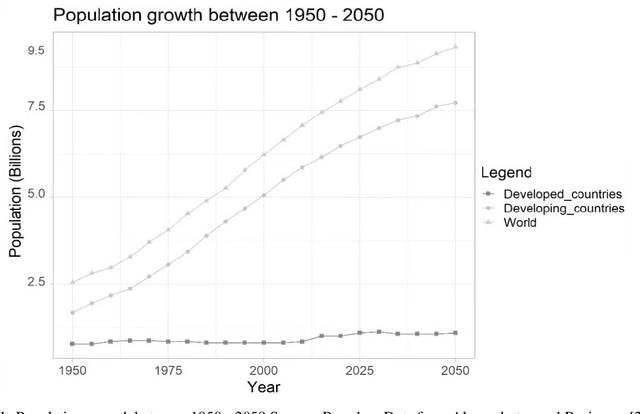

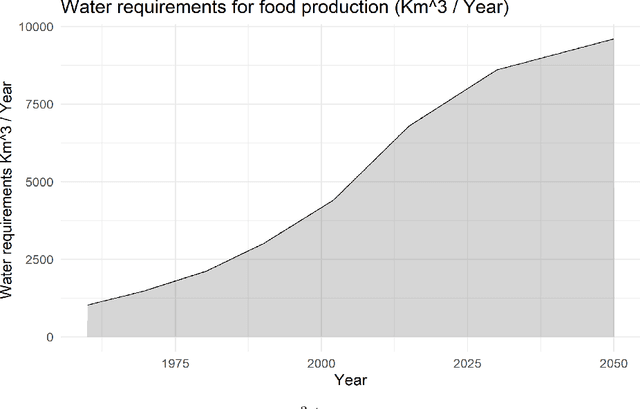
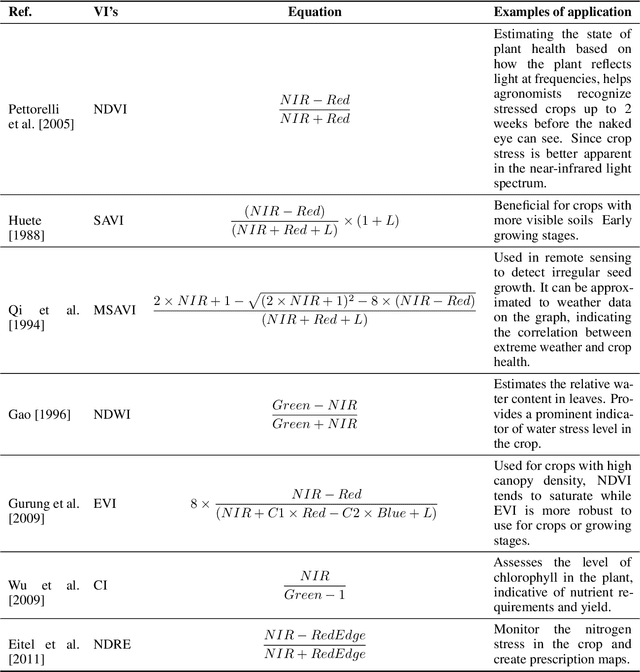
The integration of remote sensing and machine learning in agriculture is transforming the industry by providing insights and predictions through data analysis. This combination leads to improved yield prediction and water management, resulting in increased efficiency, better yields, and more sustainable agricultural practices. Achieving the United Nations' Sustainable Development Goals, especially "zero hunger," requires the investigation of crop yield and precipitation gaps, which can be accomplished through, the usage of artificial intelligence (AI), machine learning (ML), remote sensing (RS), and the internet of things (IoT). By integrating these technologies, a robust agricultural mobile or web application can be developed, providing farmers and decision-makers with valuable information and tools for improving crop management and increasing efficiency. Several studies have investigated these new technologies and their potential for diverse tasks such as crop monitoring, yield prediction, irrigation management, etc. Through a critical review, this paper reviews relevant articles that have used RS, ML, cloud computing, and IoT in crop yield prediction. It reviews the current state-of-the-art in this field by critically evaluating different machine-learning approaches proposed in the literature for crop yield prediction and water management. It provides insights into how these methods can improve decision-making in agricultural production systems. This work will serve as a compendium for those interested in yield prediction in terms of primary literature but, most importantly, what approaches can be used for real-time and robust prediction.
IsoEx: an explainable unsupervised approach to process event logs cyber investigation
Jun 07, 2023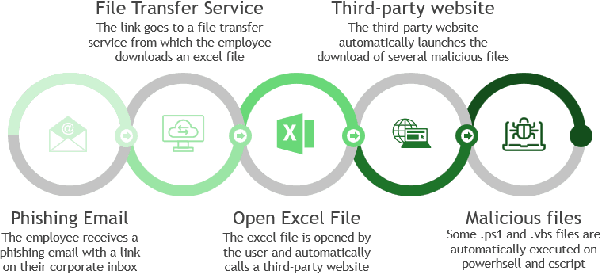
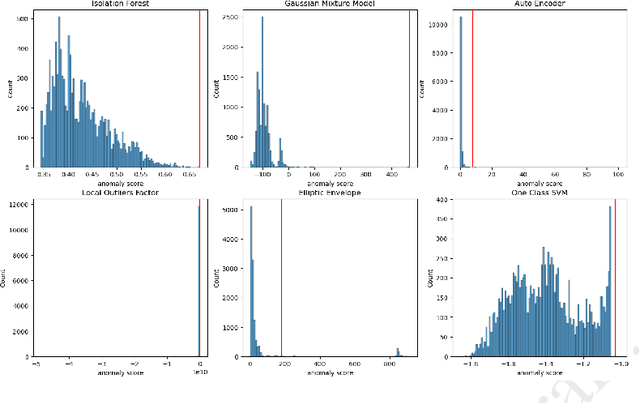
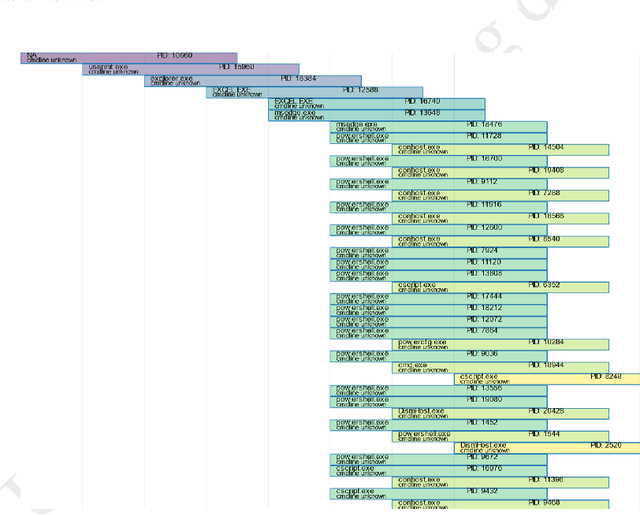
39 seconds. That is the timelapse between two consecutive cyber attacks as of 2023. Meaning that by the time you are done reading this abstract, about 1 or 2 additional cyber attacks would have occurred somewhere in the world. In this context of highly increased frequency of cyber threats, Security Operation Centers (SOC) and Computer Emergency Response Teams (CERT) can be overwhelmed. In order to relieve the cybersecurity teams in their investigative effort and help them focus on more added-value tasks, machine learning approaches and methods started to emerge. This paper introduces a novel method, IsoEx, for detecting anomalous and potentially problematic command lines during the investigation of contaminated devices. IsoEx is built around a set of features that leverages the log structure of the command line, as well as its parent/child relationship, to achieve a greater accuracy than traditional methods. To detect anomalies, IsoEx resorts to an unsupervised anomaly detection technique that is both highly sensitive and lightweight. A key contribution of the paper is its emphasis on interpretability, achieved through the features themselves and the application of eXplainable Artificial Intelligence (XAI) techniques and visualizations. This is critical to ensure the adoption of the method by SOC and CERT teams, as the paper argues that the current literature on machine learning for log investigation has not adequately addressed the issue of explainability. This method was proven efficient in a real-life environment as it was built to support a company\'s SOC and CERT
Real-Time Speech Enhancement Using Spectral Subtraction with Minimum Statistics and Spectral Floor
Feb 20, 2023
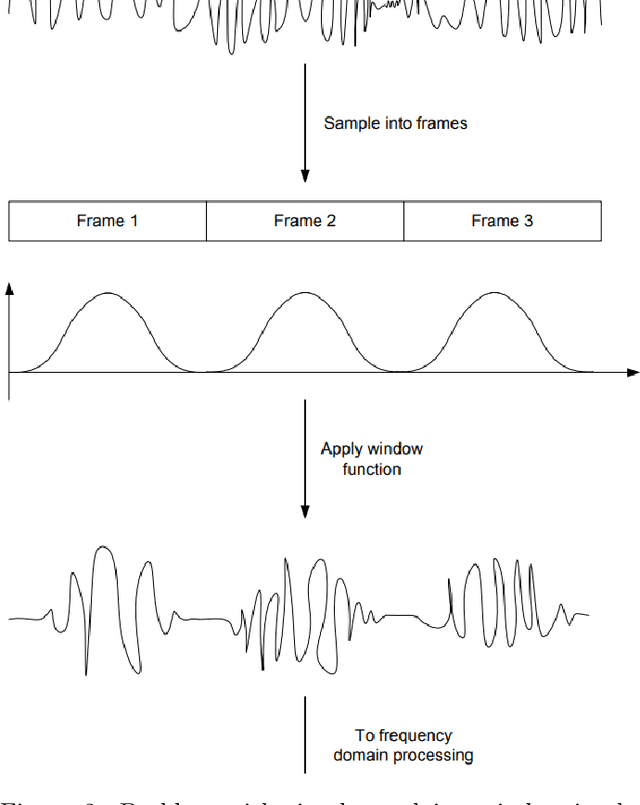
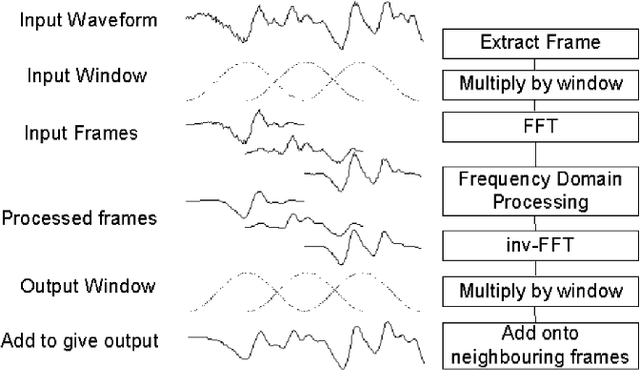
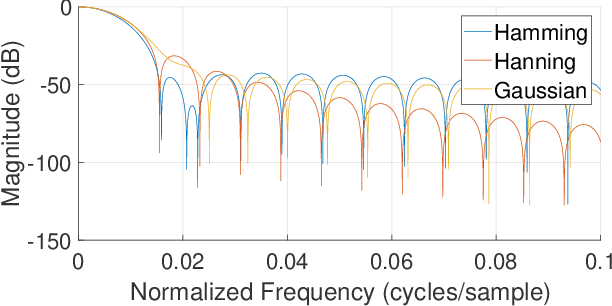
An initial real-time speech enhancement method is presented to reduce the effects of additive noise. The method operates in the frequency domain and is a form of spectral subtraction. Initially, minimum statistics are used to generate an estimate of the noise signal in the frequency domain. The use of minimum statistics avoids the need for a voice activity detector (VAD) which has proven to be challenging to create. As minimum statistics are used, the noise signal estimate must be multiplied by a scaling factor before subtraction from the noise corrupted speech signal can take place. A spectral floor is applied to the difference to suppress the effects of "musical noise". Finally, a series of further enhancements are considered to reduce the effects of residual noise even further. These methods are compared using time-frequency plots to create the final speech enhancement design
Computing a partition function of a generalized pattern-based energy over a semiring
May 27, 2023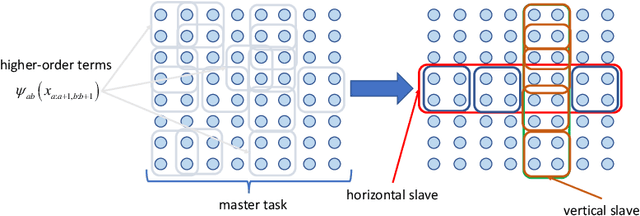
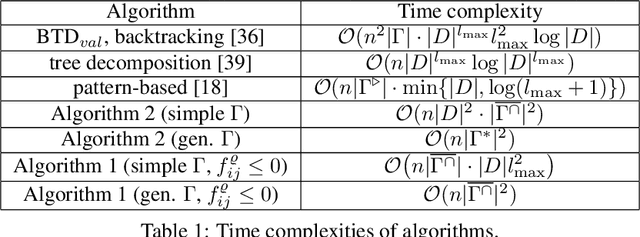
Valued constraint satisfaction problems with ordered variables (VCSPO) are a special case of Valued CSPs in which variables are totally ordered and soft constraints are imposed on tuples of variables that do not violate the order. We study a restriction of VCSPO, in which soft constraints are imposed on a segment of adjacent variables and a constraint language $\Gamma$ consists of $\{0,1\}$-valued characteristic functions of predicates. This kind of potentials generalizes the so-called pattern-based potentials, which were applied in many tasks of structured prediction. For a constraint language $\Gamma$ we introduce a closure operator, $ \overline{\Gamma^{\cap}}\supseteq \Gamma$, and give examples of constraint languages for which $|\overline{\Gamma^{\cap}}|$ is small. If all predicates in $\Gamma$ are cartesian products, we show that the minimization of a generalized pattern-based potential (or, the computation of its partition function) can be made in ${\mathcal O}(|V|\cdot |D|^2 \cdot |\overline{\Gamma^{\cap}}|^2 )$ time, where $V$ is a set of variables, $D$ is a domain set. If, additionally, only non-positive weights of constraints are allowed, the complexity of the minimization task drops to ${\mathcal O}(|V|\cdot |\overline{\Gamma^{\cap}}| \cdot |D| \cdot \max_{\rho\in \Gamma}\|\rho\|^2 )$ where $\|\rho\|$ is the arity of $\rho\in \Gamma$. For a general language $\Gamma$ and non-positive weights, the minimization task can be carried out in ${\mathcal O}(|V|\cdot |\overline{\Gamma^{\cap}}|^2)$ time. We argue that in many natural cases $\overline{\Gamma^{\cap}}$ is of moderate size, though in the worst case $|\overline{\Gamma^{\cap}}|$ can blow up and depend exponentially on $\max_{\rho\in \Gamma}\|\rho\|$.
Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder
May 25, 2023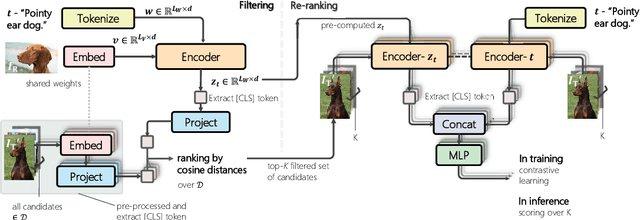
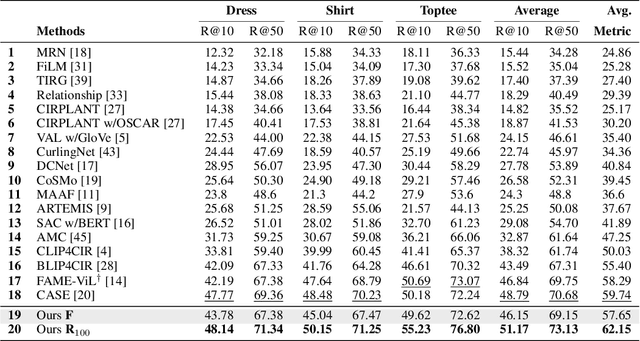
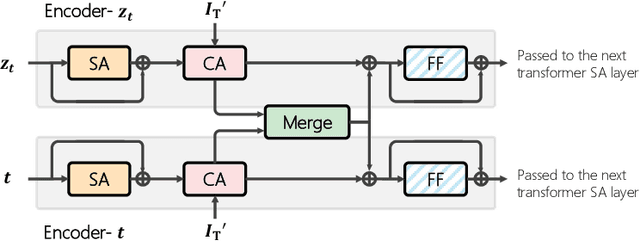
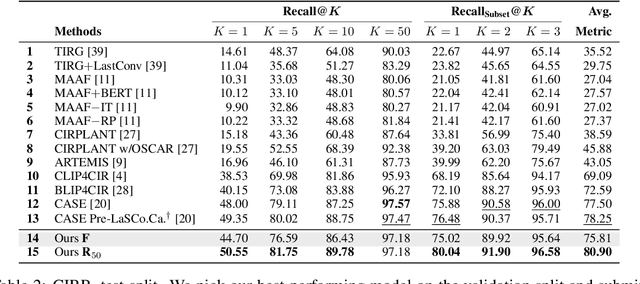
Composed image retrieval aims to find an image that best matches a given multi-modal user query consisting of a reference image and text pair. Existing methods commonly pre-compute image embeddings over the entire corpus and compare these to a reference image embedding modified by the query text at test time. Such a pipeline is very efficient at test time since fast vector distances can be used to evaluate candidates, but modifying the reference image embedding guided only by a short textual description can be difficult, especially independent of potential candidates. An alternative approach is to allow interactions between the query and every possible candidate, i.e., reference-text-candidate triplets, and pick the best from the entire set. Though this approach is more discriminative, for large-scale datasets the computational cost is prohibitive since pre-computation of candidate embeddings is no longer possible. We propose to combine the merits of both schemes using a two-stage model. Our first stage adopts the conventional vector distancing metric and performs a fast pruning among candidates. Meanwhile, our second stage employs a dual-encoder architecture, which effectively attends to the input triplet of reference-text-candidate and re-ranks the candidates. Both stages utilize a vision-and-language pre-trained network, which has proven beneficial for various downstream tasks. Our method consistently outperforms state-of-the-art approaches on standard benchmarks for the task.
LLHR: Low Latency and High Reliability CNN Distributed Inference for Resource-Constrained UAV Swarms
May 25, 2023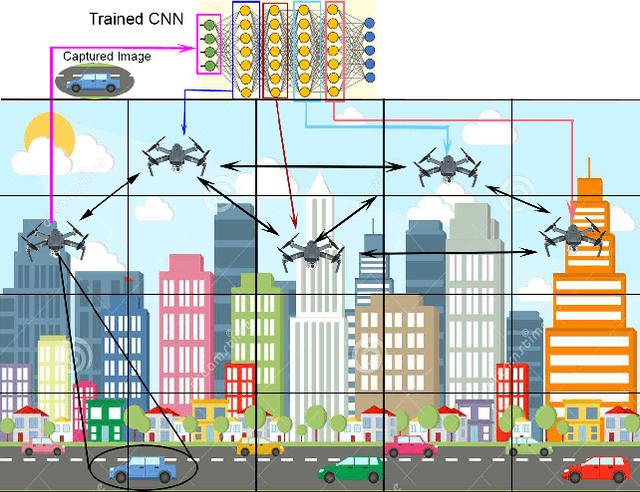
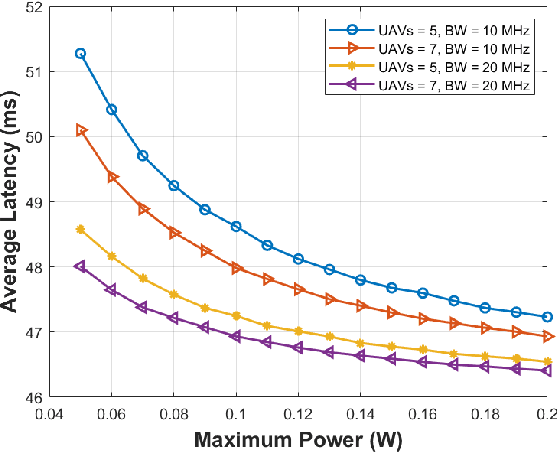
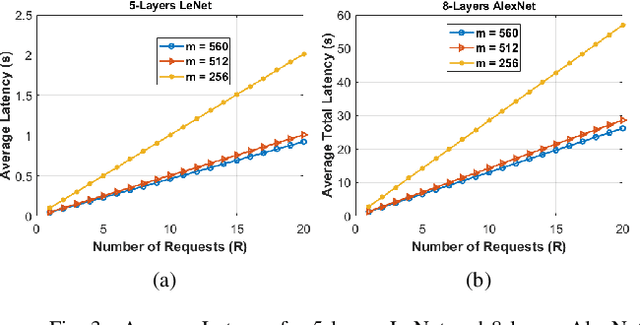

Recently, Unmanned Aerial Vehicles (UAVs) have shown impressive performance in many critical applications, such as surveillance, search and rescue operations, environmental monitoring, etc. In many of these applications, the UAVs capture images as well as other sensory data and then send the data processing requests to remote servers. Nevertheless, this approach is not always practical in real-time-based applications due to unstable connections, limited bandwidth, limited energy, and strict end-to-end latency. One promising solution is to divide the inference requests into subtasks that can be distributed among UAVs in a swarm based on the available resources. Moreover, these tasks create intermediate results that need to be transmitted reliably as the swarm moves to cover the area. Our system model deals with real-time requests, aiming to find the optimal transmission power that guarantees higher reliability and low latency. We formulate the Low Latency and High-Reliability (LLHR) distributed inference as an optimization problem, and due to the complexity of the problem, we divide it into three subproblems. In the first subproblem, we find the optimal transmit power of the connected UAVs with guaranteed transmission reliability. The second subproblem aims to find the optimal positions of the UAVs in the grid, while the last subproblem finds the optimal placement of the CNN layers in the available UAVs. We conduct extensive simulations and compare our work to two baseline models demonstrating that our model outperforms the competing models.
* arXiv admin note: substantial text overlap with arXiv:2212.11201