 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Compassionately Conservative Balanced Cuts for Image Segmentation
Mar 27, 2018
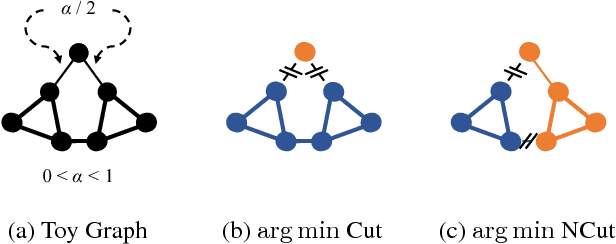
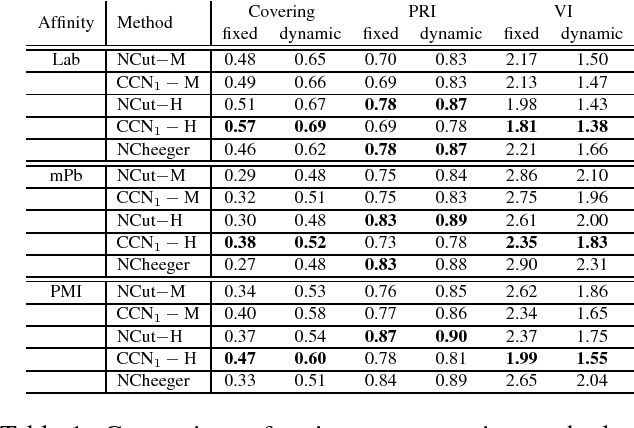
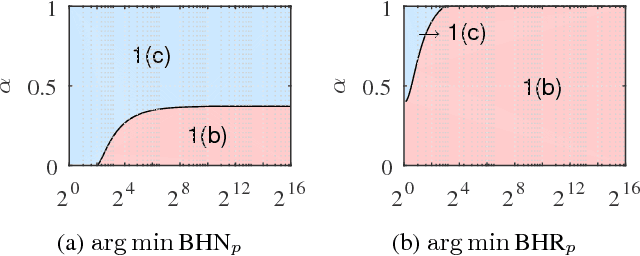
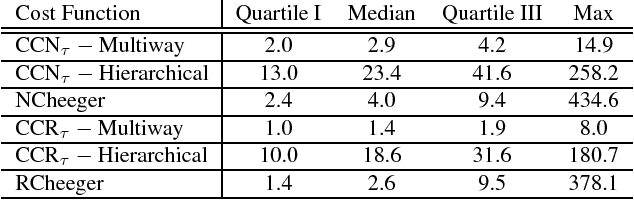
The Normalized Cut (NCut) objective function, widely used in data clustering and image segmentation, quantifies the cost of graph partitioning in a way that biases clusters or segments that are balanced towards having lower values than unbalanced partitionings. However, this bias is so strong that it avoids any singleton partitions, even when vertices are very weakly connected to the rest of the graph. Motivated by the B\"uhler-Hein family of balanced cut costs, we propose the family of Compassionately Conservative Balanced (CCB) Cut costs, which are indexed by a parameter that can be used to strike a compromise between the desire to avoid too many singleton partitions and the notion that all partitions should be balanced. We show that CCB-Cut minimization can be relaxed into an orthogonally constrained $\ell_{\tau}$-minimization problem that coincides with the problem of computing Piecewise Flat Embeddings (PFE) for one particular index value, and we present an algorithm for solving the relaxed problem by iteratively minimizing a sequence of reweighted Rayleigh quotients (IRRQ). Using images from the BSDS500 database, we show that image segmentation based on CCB-Cut minimization provides better accuracy with respect to ground truth and greater variability in region size than NCut-based image segmentation.
AdjointBackMap: Reconstructing Effective Decision Hypersurfaces from CNN Layers Using Adjoint Operators
Dec 16, 2020
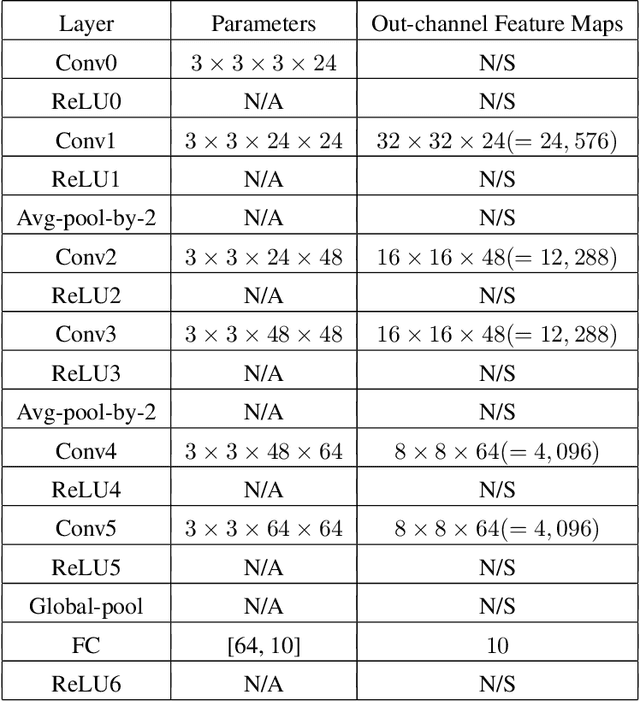
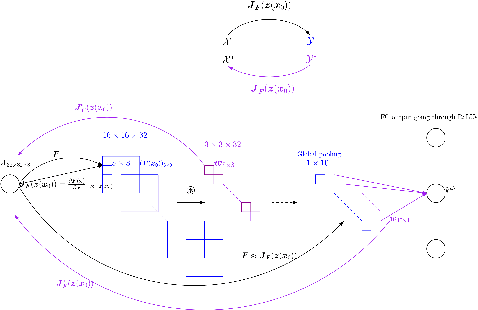
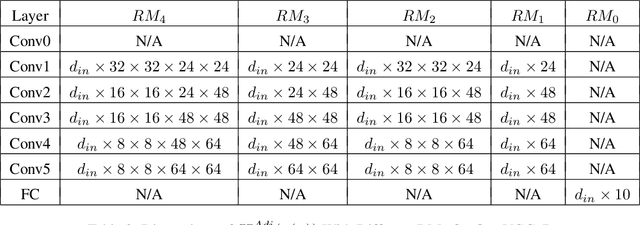
There are several effective methods in explaining the inner workings of convolutional neural networks (CNNs). However, in general, finding the inverse of the function performed by CNNs as a whole is an ill-posed problem. In this paper, we propose a method based on adjoint operators to reconstruct, given an arbitrary unit in the CNN (except for the first convolutional layer), its effective hypersurface in the input space that replicates that unit's decision surface conditioned on a particular input image. Our results show that the hypersurface reconstructed this way, when multiplied by the original input image, would give nearly exact output value of that unit. We find that the CNN unit's decision surface is largely conditioned on the input, and this may explain why adversarial inputs can effectively deceive CNNs.
Secure 3D medical Imaging
Oct 06, 2020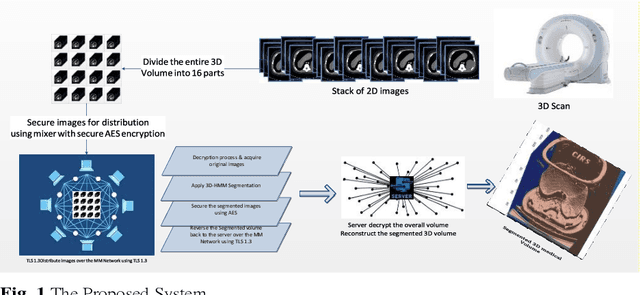
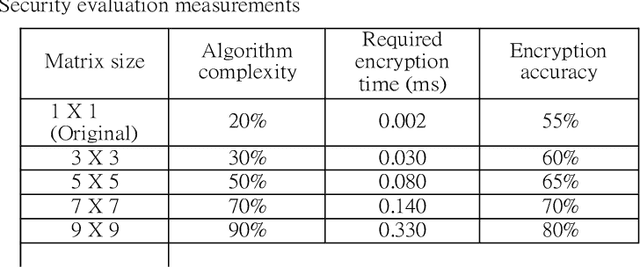

Image segmentation has proved its importance and plays an important role in various domains such as health systems and satellite-oriented military applications. In this context, accuracy, image quality, and execution time deem to be the major issues to always consider. Although many techniques have been applied, and their experimental results have shown appealing achievements for 2D images in real-time environments, however, there is a lack of works about 3D image segmentation despite its importance in improving segmentation accuracy. Specifically, HMM was used in this domain. However, it suffers from the time complexity, which was updated using different accelerators. As it is important to have efficient 3D image segmentation, we propose in this paper a novel system for partitioning the 3D segmentation process across several distributed machines. The concepts behind distributed multi-media network segmentation were employed to accelerate the segmentation computational time of training Hidden Markov Model (HMMs). Furthermore, a secure transmission has been considered in this distributed environment and various bidirectional multimedia security algorithms have been applied. The contribution of this work lies in providing an efficient and secure algorithm for 3D image segmentation. Through a number of extensive experiments, it was proved that our proposed system is of comparable efficiency to the state of art methods in terms of segmentation accuracy, security and execution time.
Transitioning from Real to Synthetic data: Quantifying the bias in model
May 10, 2021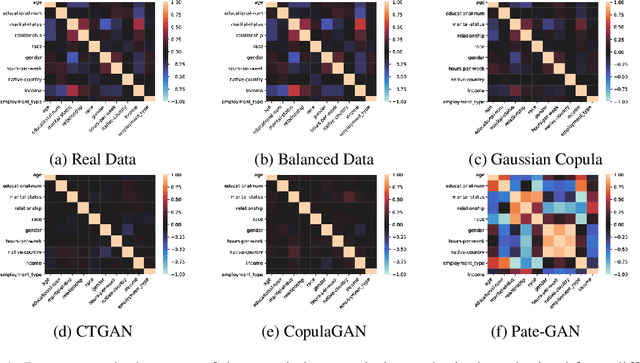
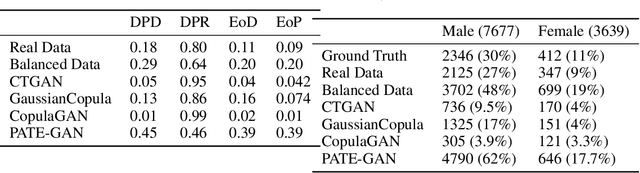
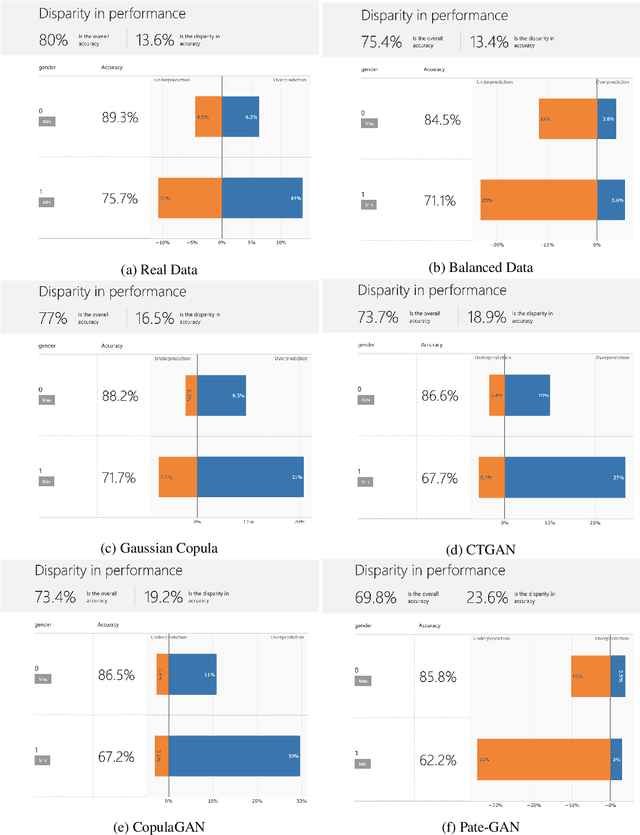
With the advent of generative modeling techniques, synthetic data and its use has penetrated across various domains from unstructured data such as image, text to structured dataset modeling healthcare outcome, risk decisioning in financial domain, and many more. It overcomes various challenges such as limited training data, class imbalance, restricted access to dataset owing to privacy issues. To ensure the trained model used for automated decisioning purposes makes a fair decision there exist prior work to quantify and mitigate those issues. This study aims to establish a trade-off between bias and fairness in the models trained using synthetic data. Variants of synthetic data generation techniques were studied to understand bias amplification including differentially private generation schemes. Through experiments on a tabular dataset, we demonstrate there exist a varying levels of bias impact on models trained using synthetic data. Techniques generating less correlated feature performs well as evident through fairness metrics with 94\%, 82\%, and 88\% relative drop in DPD (demographic parity difference), EoD (equality of odds) and EoP (equality of opportunity) respectively, and 24\% relative improvement in DRP (demographic parity ratio) with respect to the real dataset. We believe the outcome of our research study will help data science practitioners understand the bias in the use of synthetic data.
uTHCD: A New Benchmarking for Tamil Handwritten OCR
Mar 13, 2021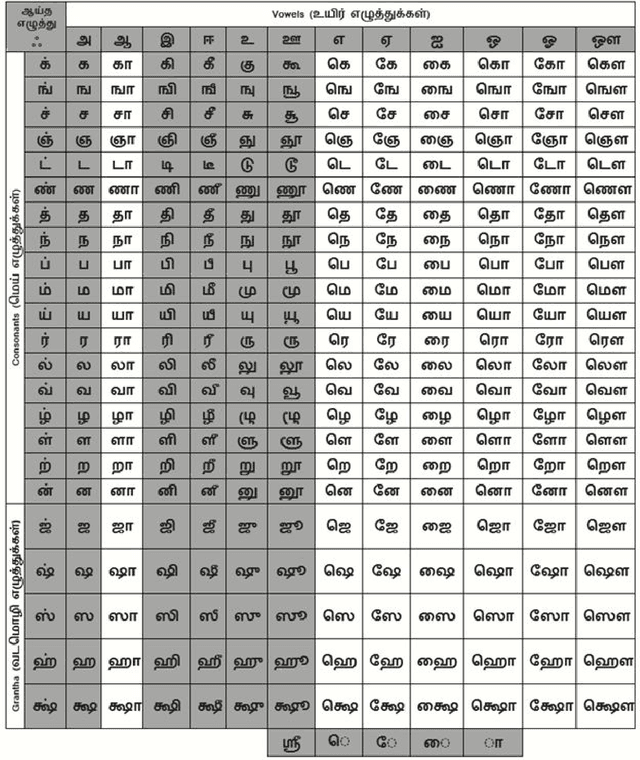
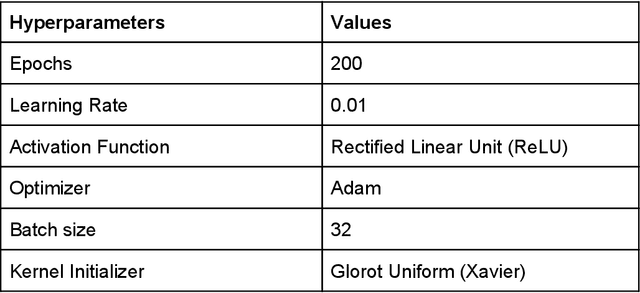
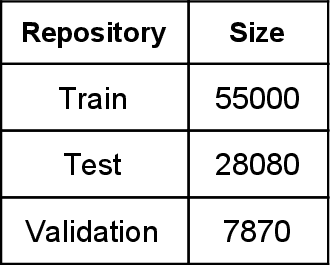
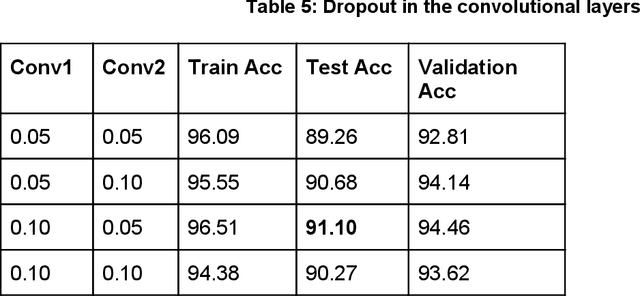
Handwritten character recognition is a challenging research in the field of document image analysis over many decades due to numerous reasons such as large writing styles variation, inherent noise in data, expansive applications it offers, non-availability of benchmark databases etc. There has been considerable work reported in literature about creation of the database for several Indic scripts but the Tamil script is still in its infancy as it has been reported only in one database [5]. In this paper, we present the work done in the creation of an exhaustive and large unconstrained Tamil Handwritten Character Database (uTHCD). Database consists of around 91000 samples with nearly 600 samples in each of 156 classes. The database is a unified collection of both online and offline samples. Offline samples were collected by asking volunteers to write samples on a form inside a specified grid. For online samples, we made the volunteers write in a similar grid using a digital writing pad. The samples collected encompass a vast variety of writing styles, inherent distortions arising from offline scanning process viz stroke discontinuity, variable thickness of stroke, distortion etc. Algorithms which are resilient to such data can be practically deployed for real time applications. The samples were generated from around 650 native Tamil volunteers including school going kids, homemakers, university students and faculty. The isolated character database will be made publicly available as raw images and Hierarchical Data File (HDF) compressed file. With this database, we expect to set a new benchmark in Tamil handwritten character recognition and serve as a launchpad for many avenues in document image analysis domain. Paper also presents an ideal experimental set-up using the database on convolutional neural networks (CNN) with a baseline accuracy of 88% on test data.
Total Variation with Overlapping Group Sparsity and Lp Quasinorm for Infrared Image Deblurring under Salt-and-Pepper Noise
Jan 01, 2019Because of the limitations of the infrared imaging principle and the properties of infrared imaging systems, infrared images have some drawbacks, including a lack of details, indistinct edges, and a large amount of salt-andpepper noise. To improve the sparse characteristics of the image while maintaining the image edges and weakening staircase artifacts, this paper proposes a method that uses the Lp quasinorm instead of the L1 norm and for infrared image deblurring with an overlapping group sparse total variation method. The Lp quasinorm introduces another degree of freedom, better describes image sparsity characteristics, and improves image restoration. Furthermore, we adopt the accelerated alternating direction method of multipliers and fast Fourier transform theory in the proposed method to improve the efficiency and robustness of our algorithm. Experiments show that under different conditions for blur and salt-and-pepper noise, the proposed method leads to excellent performance in terms of objective evaluation and subjective visual results.
Paying More Attention to Saliency: Image Captioning with Saliency and Context Attention
May 21, 2018
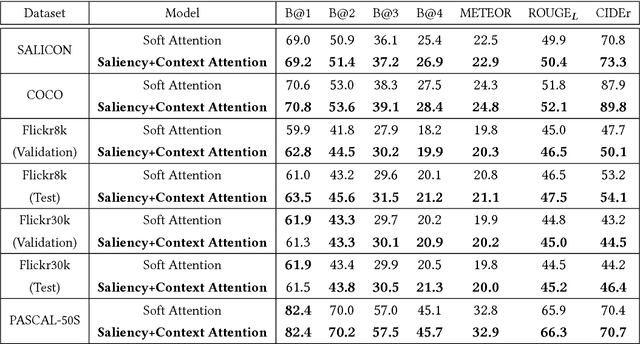
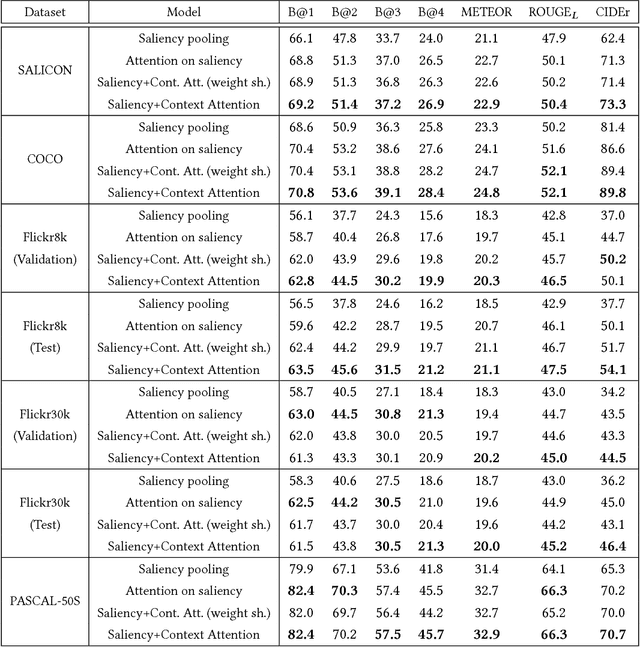
Image captioning has been recently gaining a lot of attention thanks to the impressive achievements shown by deep captioning architectures, which combine Convolutional Neural Networks to extract image representations, and Recurrent Neural Networks to generate the corresponding captions. At the same time, a significant research effort has been dedicated to the development of saliency prediction models, which can predict human eye fixations. Even though saliency information could be useful to condition an image captioning architecture, by providing an indication of what is salient and what is not, research is still struggling to incorporate these two techniques. In this work, we propose an image captioning approach in which a generative recurrent neural network can focus on different parts of the input image during the generation of the caption, by exploiting the conditioning given by a saliency prediction model on which parts of the image are salient and which are contextual. We show, through extensive quantitative and qualitative experiments on large scale datasets, that our model achieves superior performances with respect to captioning baselines with and without saliency, and to different state of the art approaches combining saliency and captioning.
Z-GCNETs: Time Zigzags at Graph Convolutional Networks for Time Series Forecasting
May 10, 2021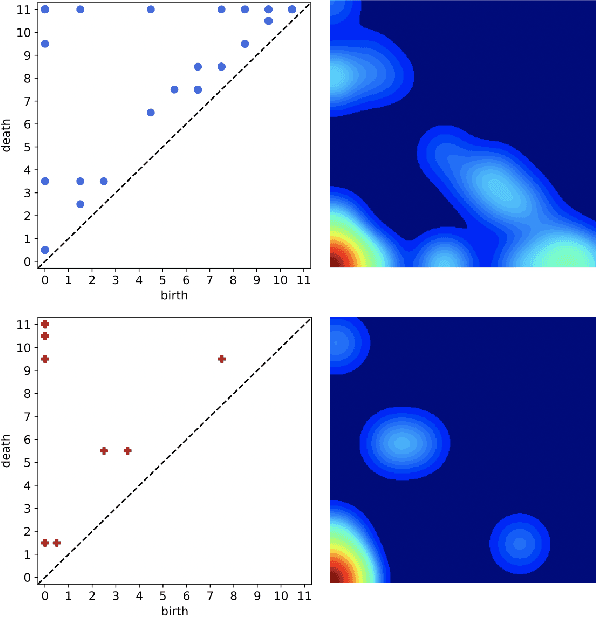
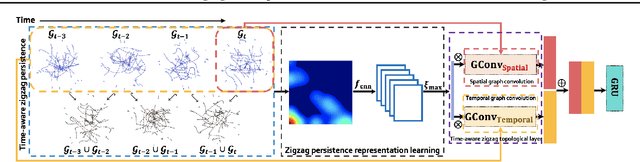
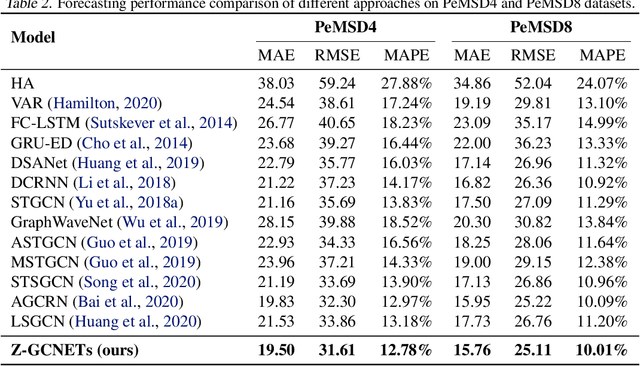
There recently has been a surge of interest in developing a new class of deep learning (DL) architectures that integrate an explicit time dimension as a fundamental building block of learning and representation mechanisms. In turn, many recent results show that topological descriptors of the observed data, encoding information on the shape of the dataset in a topological space at different scales, that is, persistent homology of the data, may contain important complementary information, improving both performance and robustness of DL. As convergence of these two emerging ideas, we propose to enhance DL architectures with the most salient time-conditioned topological information of the data and introduce the concept of zigzag persistence into time-aware graph convolutional networks (GCNs). Zigzag persistence provides a systematic and mathematically rigorous framework to track the most important topological features of the observed data that tend to manifest themselves over time. To integrate the extracted time-conditioned topological descriptors into DL, we develop a new topological summary, zigzag persistence image, and derive its theoretical stability guarantees. We validate the new GCNs with a time-aware zigzag topological layer (Z-GCNETs), in application to traffic forecasting and Ethereum blockchain price prediction. Our results indicate that Z-GCNET outperforms 13 state-of-the-art methods on 4 time series datasets.
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 06, 2020
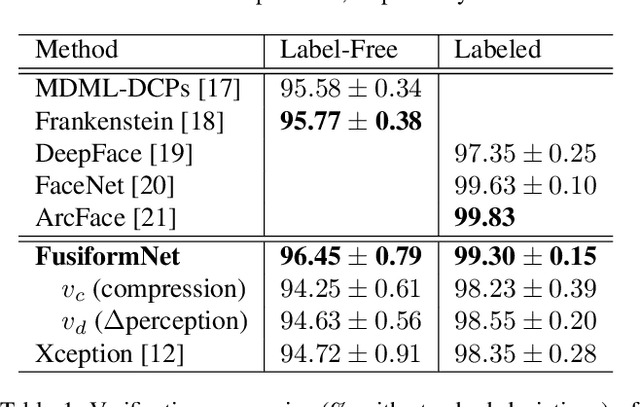
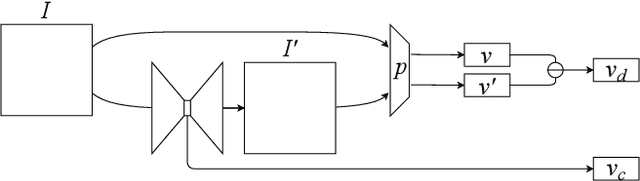
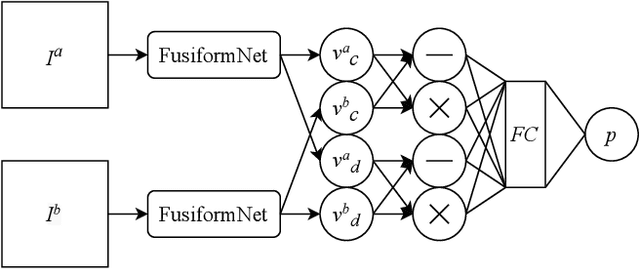
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of discriminative facial features. Tested on Image-Unrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pre-trained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
Detecting Hate Speech in Multi-modal Memes
Dec 29, 2020

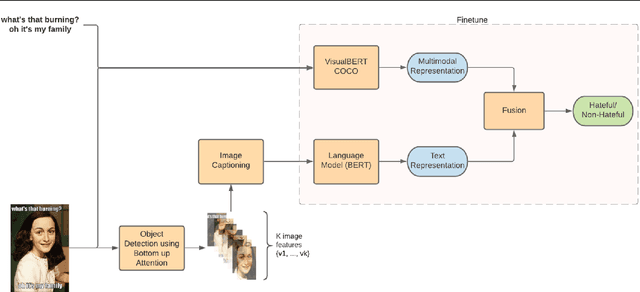
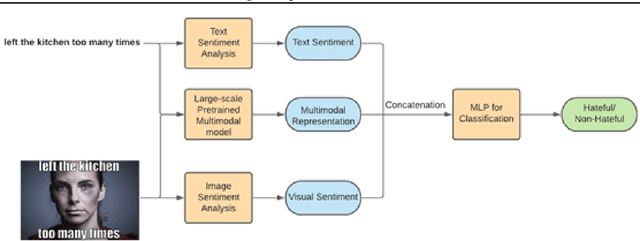
In the past few years, there has been a surge of interest in multi-modal problems, from image captioning to visual question answering and beyond. In this paper, we focus on hate speech detection in multi-modal memes wherein memes pose an interesting multi-modal fusion problem. We aim to solve the Facebook Meme Challenge \cite{kiela2020hateful} which aims to solve a binary classification problem of predicting whether a meme is hateful or not. A crucial characteristic of the challenge is that it includes "benign confounders" to counter the possibility of models exploiting unimodal priors. The challenge states that the state-of-the-art models perform poorly compared to humans. During the analysis of the dataset, we realized that majority of the data points which are originally hateful are turned into benign just be describing the image of the meme. Also, majority of the multi-modal baselines give more preference to the hate speech (language modality). To tackle these problems, we explore the visual modality using object detection and image captioning models to fetch the "actual caption" and then combine it with the multi-modal representation to perform binary classification. This approach tackles the benign text confounders present in the dataset to improve the performance. Another approach we experiment with is to improve the prediction with sentiment analysis. Instead of only using multi-modal representations obtained from pre-trained neural networks, we also include the unimodal sentiment to enrich the features. We perform a detailed analysis of the above two approaches, providing compelling reasons in favor of the methodologies used.