 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVietnamese Image Captioning
Papers and Code
KTVIC: A Vietnamese Image Captioning Dataset on the Life Domain
Jan 16, 2024Image captioning is a crucial task with applications in a wide range of domains, including healthcare and education. Despite extensive research on English image captioning datasets, the availability of such datasets for Vietnamese remains limited, with only two existing datasets. In this study, we introduce KTVIC, a comprehensive Vietnamese Image Captioning dataset focused on the life domain, covering a wide range of daily activities. This dataset comprises 4,327 images and 21,635 Vietnamese captions, serving as a valuable resource for advancing image captioning in the Vietnamese language. We conduct experiments using various deep neural networks as the baselines on our dataset, evaluating them using the standard image captioning metrics, including BLEU, METEOR, CIDEr, and ROUGE. Our findings underscore the effectiveness of the proposed dataset and its potential contributions to the field of image captioning in the Vietnamese context.
UIT-OpenViIC: A Novel Benchmark for Evaluating Image Captioning in Vietnamese
May 09, 2023



Image Captioning is one of the vision-language tasks that still interest the research community worldwide in the 2020s. MS-COCO Caption benchmark is commonly used to evaluate the performance of advanced captioning models, although it was published in 2015. Recent captioning models trained on the MS-COCO Caption dataset only have good performance in language patterns of English; they do not have such good performance in contexts captured in Vietnam or fluently caption images using Vietnamese. To contribute to the low-resources research community as in Vietnam, we introduce a novel image captioning dataset in Vietnamese, the Open-domain Vietnamese Image Captioning dataset (UIT-OpenViIC). The introduced dataset includes complex scenes captured in Vietnam and manually annotated by Vietnamese under strict rules and supervision. In this paper, we present in more detail the dataset creation process. From preliminary analysis, we show that our dataset is challenging to recent state-of-the-art (SOTA) Transformer-based baselines, which performed well on the MS COCO dataset. Then, the modest results prove that UIT-OpenViIC has room to grow, which can be one of the standard benchmarks in Vietnamese for the research community to evaluate their captioning models. Furthermore, we present a CAMO approach that effectively enhances the image representation ability by a multi-level encoder output fusion mechanism, which helps improve the quality of generated captions compared to previous captioning models.
VieCap4H-VLSP 2021: ObjectAoA -- Enhancing performance of Object Relation Transformer with Attention on Attention for Vietnamese image captioning
Nov 12, 2022



Image captioning is currently a challenging task that requires the ability to both understand visual information and use human language to describe this visual information in the image. In this paper, we propose an efficient way to improve the image understanding ability of transformer-based method by extending Object Relation Transformer architecture with Attention on Attention mechanism. Experiments on the VieCap4H dataset show that our proposed method significantly outperforms its original structure on both the public test and private test of the Image Captioning shared task held by VLSP.
vieCap4H-VLSP 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM
Sep 03, 2022
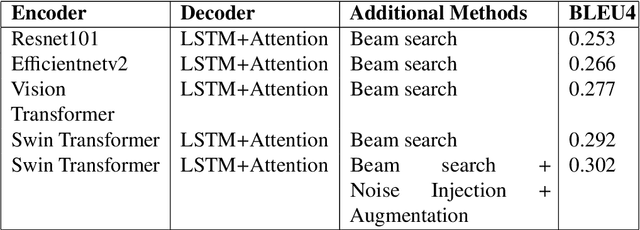
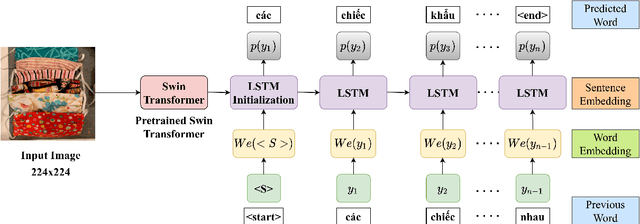

This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3$^{rd}$ place on the private leaderboard. Our code can be found at \url{https://git.io/JDdJm}.
UIT-ViIC: A Dataset for the First Evaluation on Vietnamese Image Captioning
Feb 01, 2020
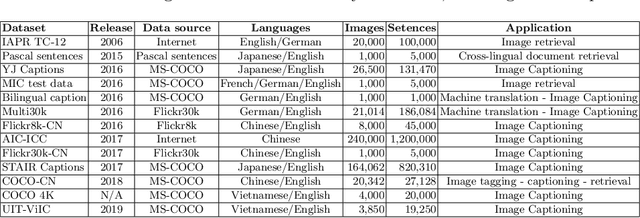
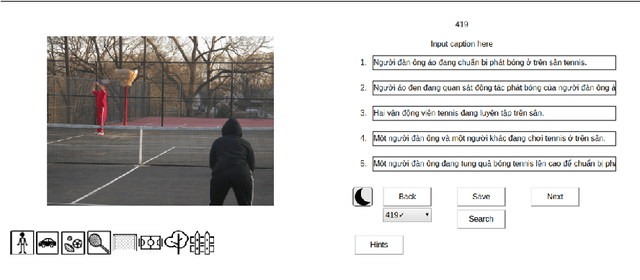
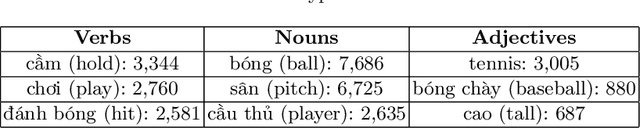
Image Captioning, the task of automatic generation of image captions, has attracted attentions from researchers in many fields of computer science, being computer vision, natural language processing and machine learning in recent years. This paper contributes to research on Image Captioning task in terms of extending dataset to a different language - Vietnamese. So far, there is no existed Image Captioning dataset for Vietnamese language, so this is the foremost fundamental step for developing Vietnamese Image Captioning. In this scope, we first build a dataset which contains manually written captions for images from Microsoft COCO dataset relating to sports played with balls, we called this dataset UIT-ViIC. UIT-ViIC consists of 19,250 Vietnamese captions for 3,850 images. Following that, we evaluate our dataset on deep neural network models and do comparisons with English dataset and two Vietnamese datasets built by different methods. UIT-ViIC is published on our lab website for research purposes.
End to End Recognition System for Recognizing Offline Unconstrained Vietnamese Handwriting
May 14, 2019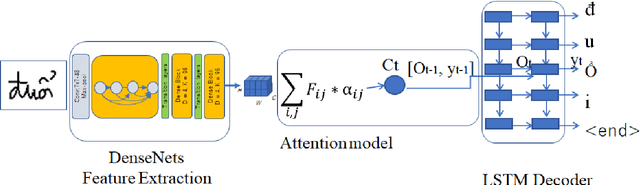
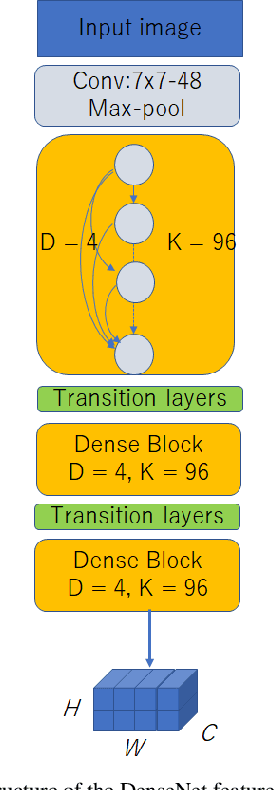
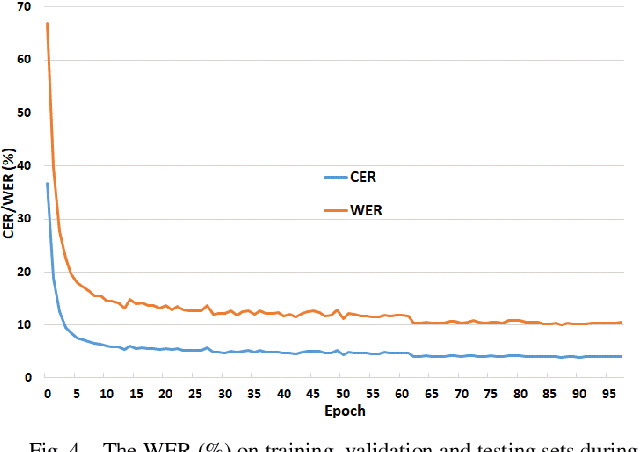

Inspired by recent successes in neural machine translation and image caption generation, we present an attention based encoder decoder model (AED) to recognize Vietnamese Handwritten Text. The model composes of two parts: a DenseNet for extracting invariant features, and a Long Short-Term Memory network (LSTM) with an attention model incorporated for generating output text (LSTM decoder), which are connected from the CNN part to the attention model. The input of the CNN part is a handwritten text image and the target of the LSTM decoder is the corresponding text of the input image. Our model is trained end-to-end to predict the text from a given input image since all the parts are differential components. In the experiment section, we evaluate our proposed AED model on the VNOnDB-Word and VNOnDB-Line datasets to verify its efficiency. The experiential results show that our model achieves 12.30% of word error rate without using any language model. This result is competitive with the handwriting recognition system provided by Google in the Vietnamese Online Handwritten Text Recognition competition.