 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIpn Hand
Papers and Code
Multi-modal Fusion for Single-Stage Continuous Gesture Recognition
Nov 10, 2020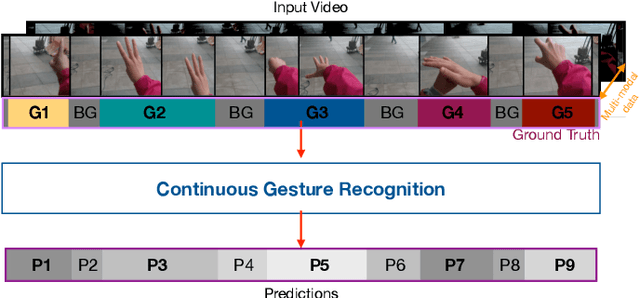
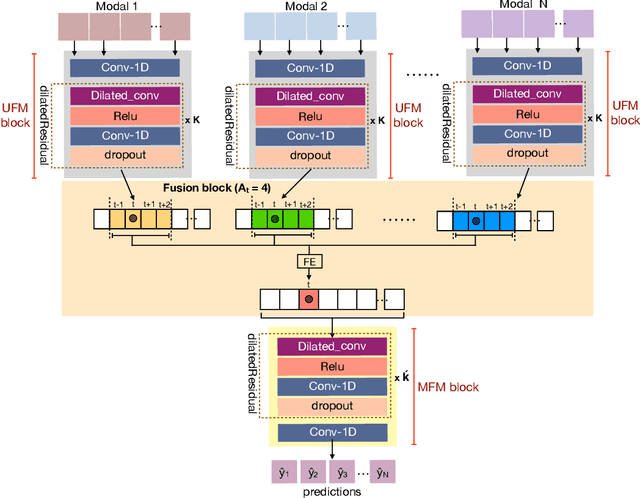
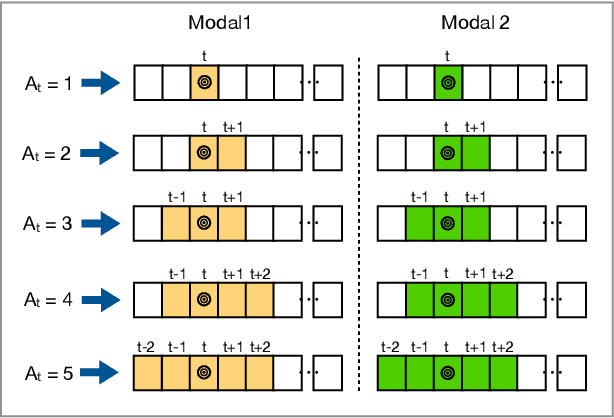
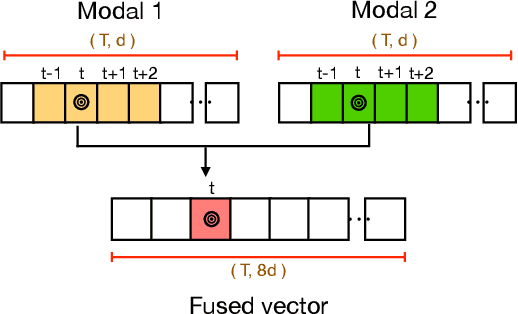
Gesture recognition is a much studied research area which has myriad real-world applications including robotics and human-machine interaction. Current gesture recognition methods have heavily focused on isolated gestures, and existing continuous gesture recognition methods are limited by a two-stage approach where independent models are required for detection and classification, with the performance of the latter being constrained by detection performance. In contrast, we introduce a single-stage continuous gesture recognition model, that can detect and classify multiple gestures in a single video via a single model. This approach learns the natural transitions between gestures and non-gestures without the need for a pre-processing segmentation stage to detect individual gestures. To enable this, we introduce a multi-modal fusion mechanism to support the integration of important information that flows from multi-modal inputs, and is scalable to any number of modes. Additionally, we propose Unimodal Feature Mapping (UFM) and Multi-modal Feature Mapping (MFM) models to map uni-modal features and the fused multi-modal features respectively. To further enhance the performance we propose a mid-point based loss function that encourages smooth alignment between the ground truth and the prediction. We demonstrate the utility of our proposed framework which can handle variable-length input videos, and outperforms the state-of-the-art on two challenging datasets, EgoGesture, and IPN hand. Furthermore, ablative experiments show the importance of different components of the proposed framework.
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Apr 20, 2020


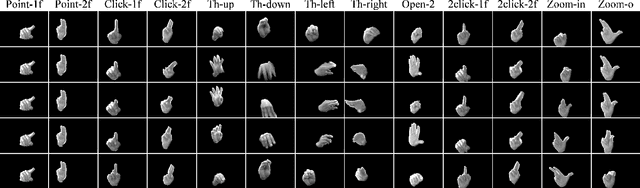
In the research community of continuous hand gesture recognition (HGR), the current publicly available datasets lack real-world elements needed to build responsive and efficient HGR systems. In this paper, we introduce a new benchmark dataset named IPN Hand with sufficient size, variation, and real-world elements able to train and evaluate deep neural networks. This dataset contains more than 4 000 gesture samples and 800 000 RGB frames from 50 distinct subjects. We design 13 different static and dynamic gestures focused on interaction with touchless screens. We especially consider the scenario when continuous gestures are performed without transition states, and when subjects perform natural movements with their hands as non-gesture actions. Gestures were collected from about 30 diverse scenes, with real-world variation in background and illumination. With our dataset, the performance of three 3D-CNN models is evaluated on the tasks of isolated and continuous real-time HGR. Furthermore, we analyze the possibility of increasing the recognition accuracy by adding multiple modalities derived from RGB frames, i.e., optical flow and semantic segmentation, while keeping the real-time performance of the 3D-CNN model. Our empirical study also provides a comparison with the publicly available nvGesture (NVIDIA) dataset. The experimental results show that the state-of-the-art ResNext-101 model decreases about 30% accuracy when using our real-world dataset, demonstrating that the IPN Hand dataset can be used as a benchmark, and may help the community to step forward in the continuous HGR. Our dataset and pre-trained models used in the evaluation are publicly available at https://github.com/GibranBenitez/IPN-hand.