 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Can Have Your Data and Balance It Too: Towards Balanced and Efficient Multilingual Models
Paper and Code
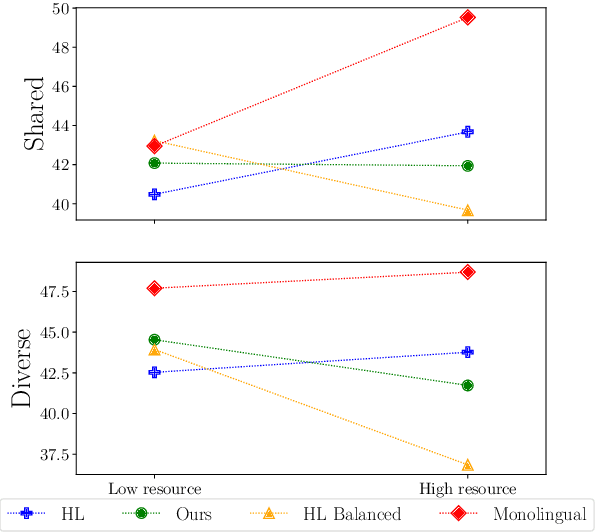
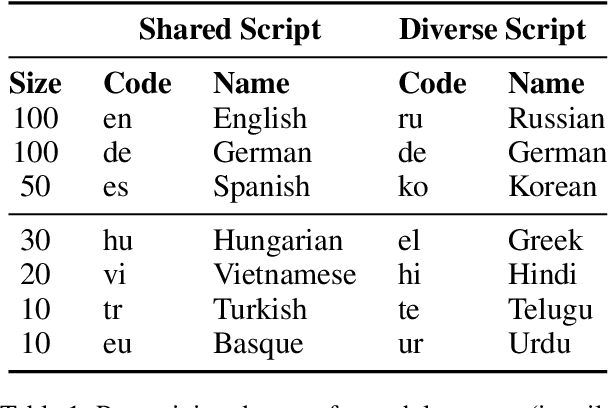
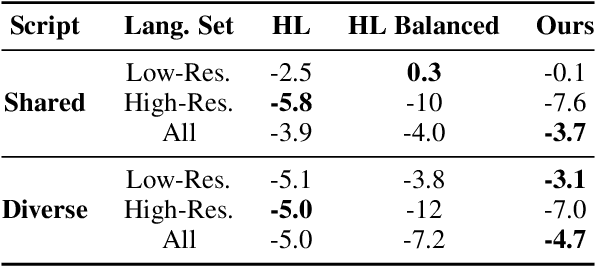
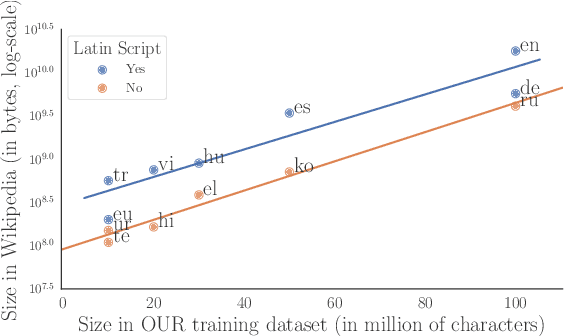
Multilingual models have been widely used for cross-lingual transfer to low-resource languages. However, the performance on these languages is hindered by their underrepresentation in the pretraining data. To alleviate this problem, we propose a novel multilingual training technique based on teacher-student knowledge distillation. In this setting, we utilize monolingual teacher models optimized for their language. We use those teachers along with balanced (sub-sampled) data to distill the teachers' knowledge into a single multilingual student. Our method outperforms standard training methods in low-resource languages and retrains performance on high-resource languages while using the same amount of data. If applied widely, our approach can increase the representation of low-resource languages in NLP systems.