 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Broad Optimality of Profile Maximum Likelihood
Paper and Code
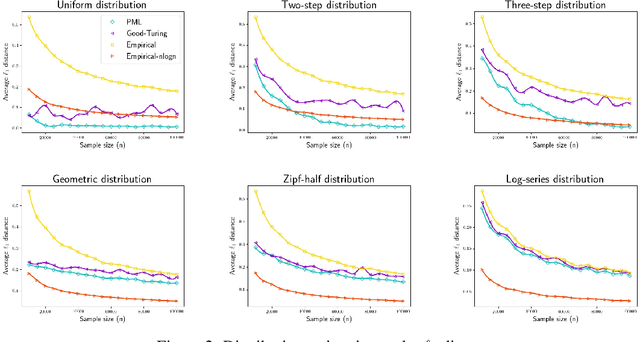
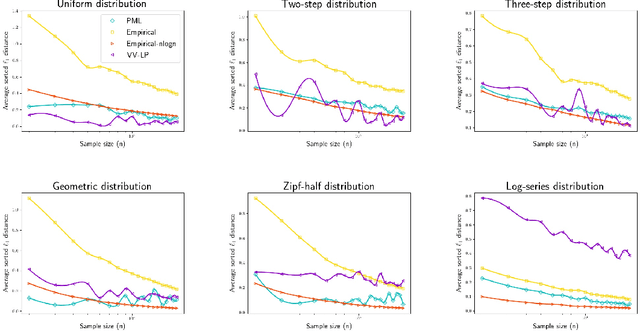
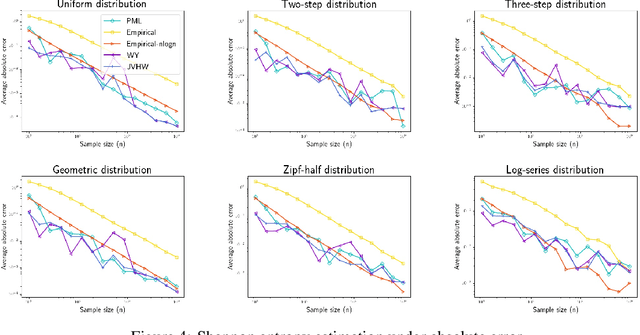
We study three fundamental statistical-learning problems: distribution estimation, property estimation, and property testing. We establish the profile maximum likelihood (PML) estimator as the first unified sample-optimal approach to a wide range of learning tasks. In particular, for every alphabet size $k$ and desired accuracy $\varepsilon$: $\textbf{Distribution estimation}$ Under $\ell_1$ distance, PML yields optimal $\Theta(k/(\varepsilon^2\log k))$ sample complexity for sorted-distribution estimation, and a PML-based estimator empirically outperforms the Good-Turing estimator on the actual distribution; $\textbf{Additive property estimation}$ For a broad class of additive properties, the PML plug-in estimator uses just four times the sample size required by the best estimator to achieve roughly twice its error, with exponentially higher confidence; $\boldsymbol{\alpha}\textbf{-R\'enyi entropy estimation}$ For integer $\alpha>1$, the PML plug-in estimator has optimal $k^{1-1/\alpha}$ sample complexity; for non-integer $\alpha>3/4$, the PML plug-in estimator has sample complexity lower than the state of the art; $\textbf{Identity testing}$ In testing whether an unknown distribution is equal to or at least $\varepsilon$ far from a given distribution in $\ell_1$ distance, a PML-based tester achieves the optimal sample complexity up to logarithmic factors of $k$. Most of these results also hold for a near-linear-time computable variant of PML. Stronger results hold for a different and novel variant called truncated PML (TPML).