Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore Combination for Improved Parallel Corpus Filtering for Low Resource Conditions
Paper and Code
Nov 16, 2020
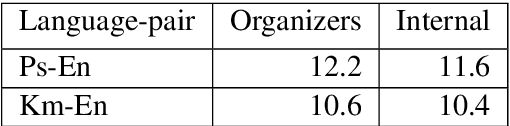
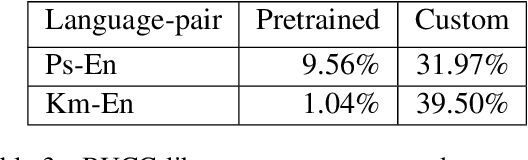

This paper describes our submission to the WMT20 sentence filtering task. We combine scores from (1) a custom LASER built for each source language, (2) a classifier built to distinguish positive and negative pairs by semantic alignment, and (3) the original scores included in the task devkit. For the mBART finetuning setup, provided by the organizers, our method shows 7% and 5% relative improvement over baseline, in sacreBLEU score on the test set for Pashto and Khmer respectively.
* Accepted at WMT20 (EMNLP 2020 Fifth Conference on Machine
Translation)
View paper on