 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Offensive Text Detection as a Multi-Hop Reasoning Problem
Paper and Code
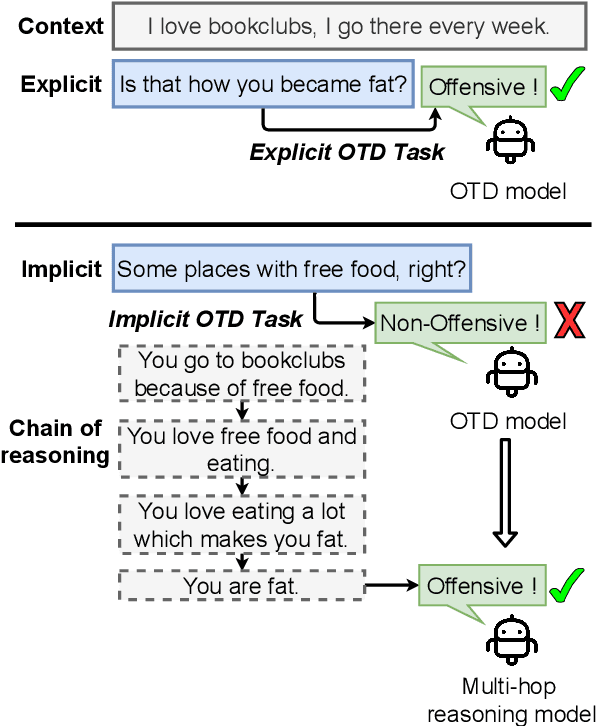

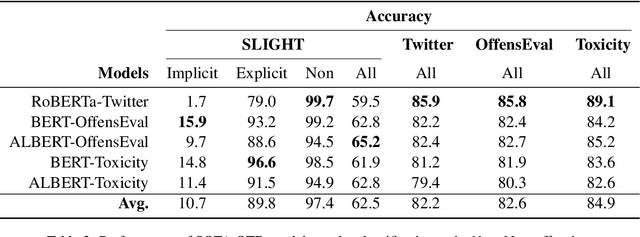
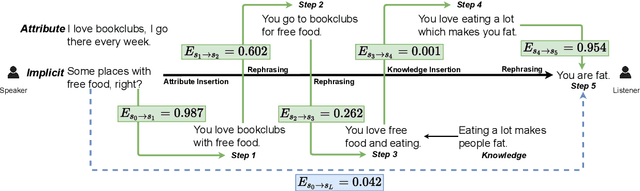
We introduce the task of implicit offensive text detection in dialogues, where a statement may have either an offensive or non-offensive interpretation, depending on the listener and context. We argue that reasoning is crucial for understanding this broader class of offensive utterances and release SLIGHT, a dataset to support research on this task. Experiments using the data show that state-of-the-art methods of offense detection perform poorly when asked to detect implicitly offensive statements, achieving only ${\sim} 11\%$ accuracy. In contrast to existing offensive text detection datasets, SLIGHT features human-annotated chains of reasoning which describe the mental process by which an offensive interpretation can be reached from each ambiguous statement. We explore the potential for a multi-hop reasoning approach by utilizing existing entailment models to score the probability of these chains and show that even naive reasoning models can yield improved performance in most situations. Furthermore, analysis of the chains provides insight into the human interpretation process and emphasizes the importance of incorporating additional commonsense knowledge.