 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Multi-level and Episodic Human Feedback
Paper and Code
Apr 20, 2025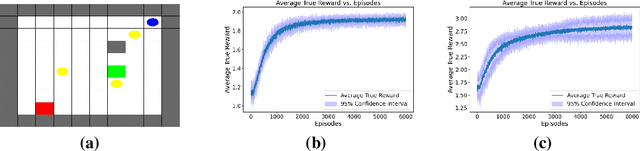
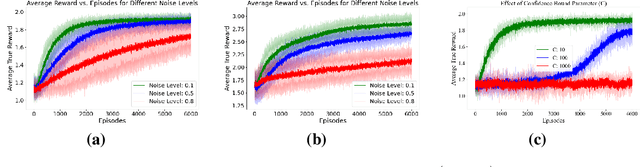

Designing an effective reward function has long been a challenge in reinforcement learning, particularly for complex tasks in unstructured environments. To address this, various learning paradigms have emerged that leverage different forms of human input to specify or refine the reward function. Reinforcement learning from human feedback is a prominent approach that utilizes human comparative feedback, expressed as a preference for one behavior over another, to tackle this problem. In contrast to comparative feedback, we explore multi-level human feedback, which is provided in the form of a score at the end of each episode. This type of feedback offers more coarse but informative signals about the underlying reward function than binary feedback. Additionally, it can handle non-Markovian rewards, as it is based on the evaluation of an entire episode. We propose an algorithm to efficiently learn both the reward function and the optimal policy from this form of feedback. Moreover, we show that the proposed algorithm achieves sublinear regret and demonstrate its empirical effectiveness through extensive simulations.