 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINE: Pipeline for Important Node Exploration in Attributed Networks
Paper and Code

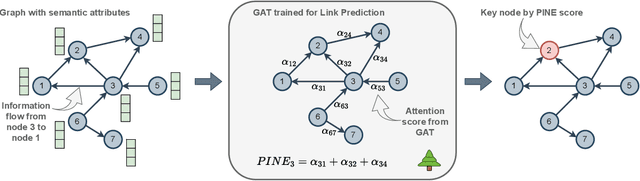
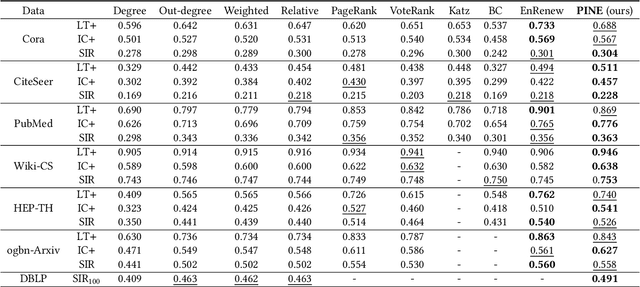
A graph with semantically attributed nodes are a common data structure in a wide range of domains. It could be interlinked web data or citation networks of scientific publications. The essential problem for such a data type is to determine nodes that carry greater importance than all the others, a task that markedly enhances system monitoring and management. Traditional methods to identify important nodes in networks introduce centrality measures, such as node degree or more complex PageRank. However, they consider only the network structure, neglecting the rich node attributes. Recent methods adopt neural networks capable of handling node features, but they require supervision. This work addresses the identified gap--the absence of approaches that are both unsupervised and attribute-aware--by introducing a Pipeline for Important Node Exploration (PINE). At the core of the proposed framework is an attention-based graph model that incorporates node semantic features in the learning process of identifying the structural graph properties. The PINE's node importance scores leverage the obtained attention distribution. We demonstrate the superior performance of the proposed PINE method on various homogeneous and heterogeneous attributed networks. As an industry-implemented system, PINE tackles the real-world challenge of unsupervised identification of key entities within large-scale enterprise graphs.