 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the train-test resolution discrepancy: FixEfficientNet
Paper and Code
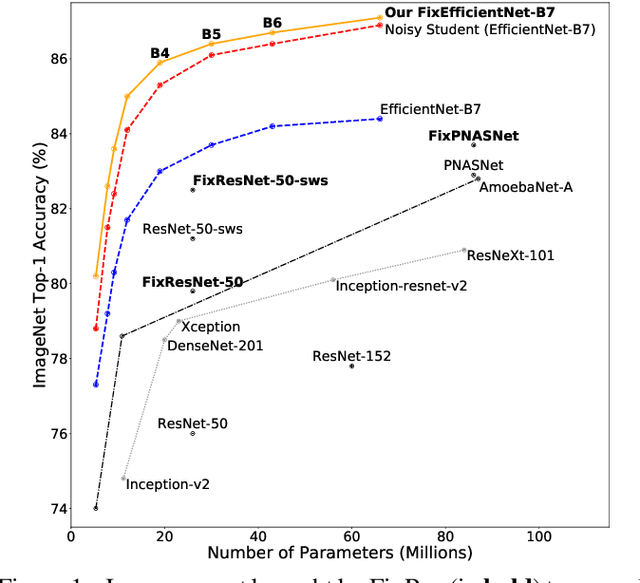
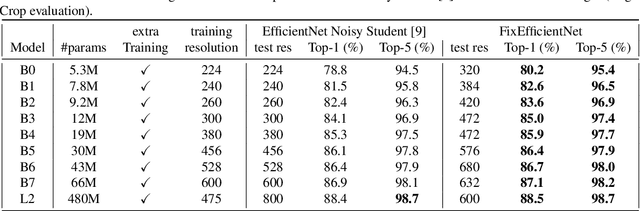
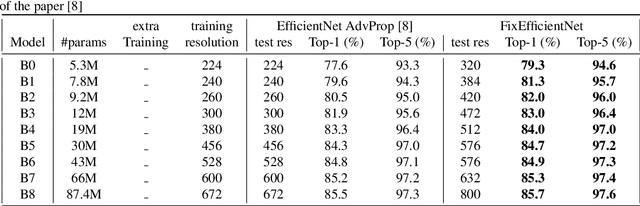
This note complements the paper "Fixing the train-test resolution discrepancy" that introduced the FixRes method. First, we show that this strategy is advantageously combined with recent training recipes from the literature. Most importantly, we provide new results for the EfficientNet architecture. The resulting network, called FixEfficientNet, significantly outperforms the initial architecture with the same number of parameters. For instance, our FixEfficientNet-B0 trained without additional training data achieves 79.3% top-1 accuracy on ImageNet with 5.3M parameters. This is a +0.5% absolute improvement over the Noisy student EfficientNet-B0 trained with 300M unlabeled images and +1.7% compared to the EfficientNet-B0 trained with adversarial examples. An EfficientNet-L2 pre-trained with weak supervision on 300M unlabeled images and further optimized with FixRes achieves 88.5% top-1 accuracy (top-5: 98.7%), which establishes the new state of the art for ImageNet with a single crop.This improvement in performance transfers to the experimental setting of ImageNet-v2, that is less prone to overfitting, for which we establish the new state of the art.