Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFANOK: Knockoffs in Linear Time
Paper and Code
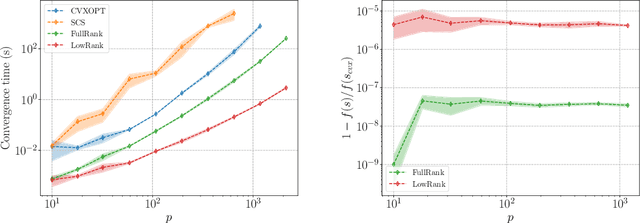
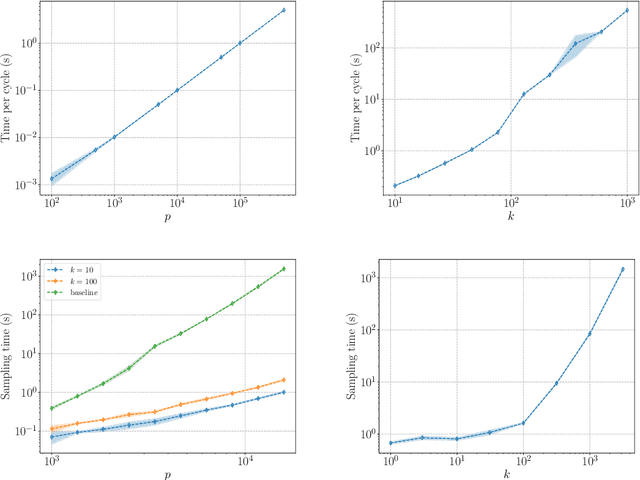
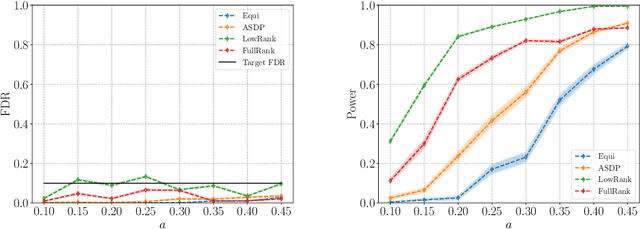
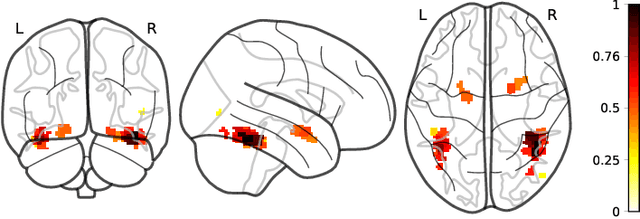
We describe a series of algorithms that efficiently implement Gaussian model-X knockoffs to control the false discovery rate on large scale feature selection problems. Identifying the knockoff distribution requires solving a large scale semidefinite program for which we derive several efficient methods. One handles generic covariance matrices, has a complexity scaling as $O(p^3)$ where $p$ is the ambient dimension, while another assumes a rank $k$ factor model on the covariance matrix to reduce this complexity bound to $O(pk^2)$. We also derive efficient procedures to both estimate factor models and sample knockoff covariates with complexity linear in the dimension. We test our methods on problems with $p$ as large as $500,000$.
* For code see https://github.com/qrebjock/fanok
View paper on