 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Retrieval at CheckThat! 2025: Identifying Scientific Papers from Implicit Social Media Mentions via Hybrid Retrieval and Re-Ranking
Paper and Code
May 29, 2025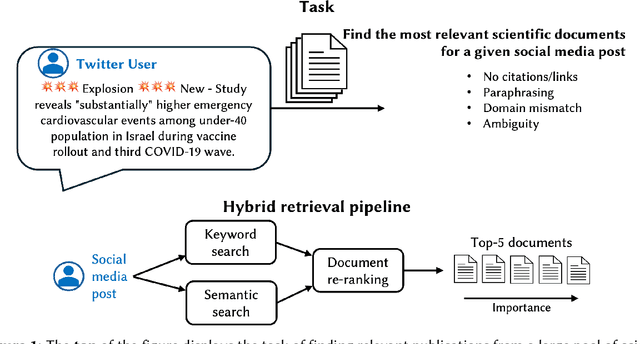
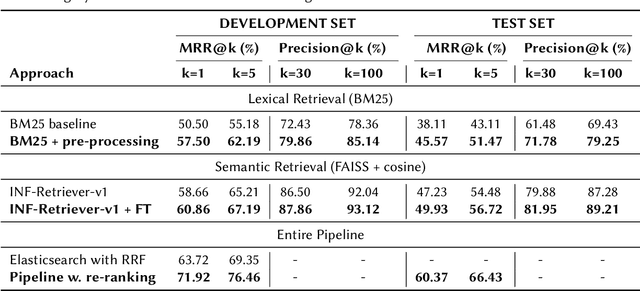
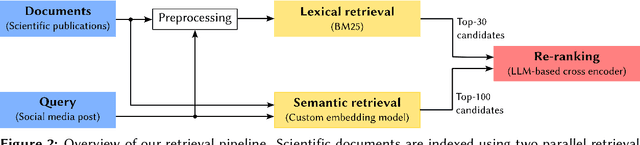
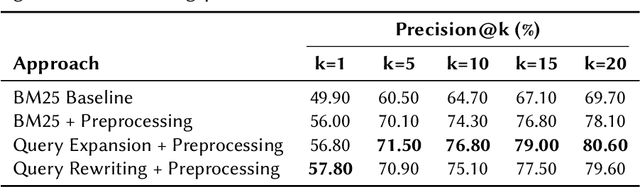
We present the methodology and results of the Deep Retrieval team for subtask 4b of the CLEF CheckThat! 2025 competition, which focuses on retrieving relevant scientific literature for given social media posts. To address this task, we propose a hybrid retrieval pipeline that combines lexical precision, semantic generalization, and deep contextual re-ranking, enabling robust retrieval that bridges the informal-to-formal language gap. Specifically, we combine BM25-based keyword matching with a FAISS vector store using a fine-tuned INF-Retriever-v1 model for dense semantic retrieval. BM25 returns the top 30 candidates, and semantic search yields 100 candidates, which are then merged and re-ranked via a large language model (LLM)-based cross-encoder. Our approach achieves a mean reciprocal rank at 5 (MRR@5) of 76.46% on the development set and 66.43% on the hidden test set, securing the 1st position on the development leaderboard and ranking 3rd on the test leaderboard (out of 31 teams), with a relative performance gap of only 2 percentage points compared to the top-ranked system. We achieve this strong performance by running open-source models locally and without external training data, highlighting the effectiveness of a carefully designed and fine-tuned retrieval pipeline.