 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOUNTDOWN: Contextually Sparse Activation Filtering Out Unnecessary Weights in Down Projection
Paper and Code
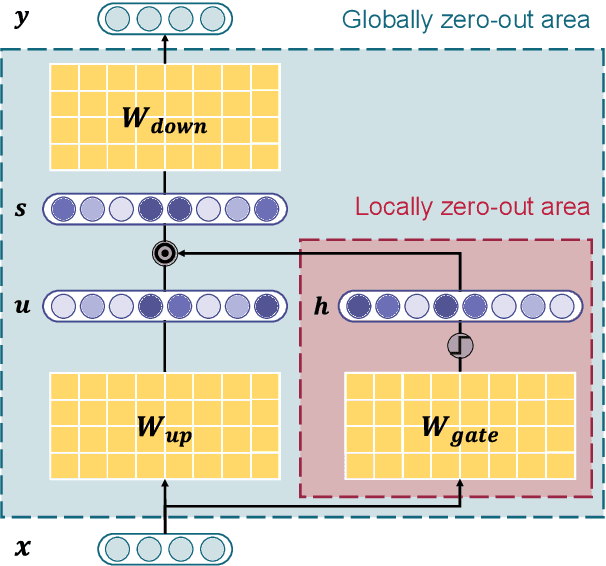



The growing size of large language models has created significant computational inefficiencies. To address this challenge, sparse activation methods selectively deactivates non-essential parameters during inference, reducing computational costs in FFNN layers. While existing methods focus on non-linear gating mechanisms, we hypothesize that the sparsity of the FFNN layer lies globally in the form of a linear combination over its internal down projection matrix. Based on this insight, we propose two methods: M-COUNTDOWN, leveraging indirect coefficients, and D-COUNTDOWN, utilizing direct coefficients of the linear combination. Experimental results demonstrate that D-COUNTDOWN can omit 90% of computations with performance loss as low as 5.5% ideally, while M-COUNTDOWN provides a predictor-free solution with up to 29.4% better performance preservation compared to existing methods. Our specialized kernel implementations effectively realize these theoretical gains into substantial real-world acceleration.