 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSET: A Benchmark for Evaluating Neural Program Embeddings
Paper and Code
May 27, 2019
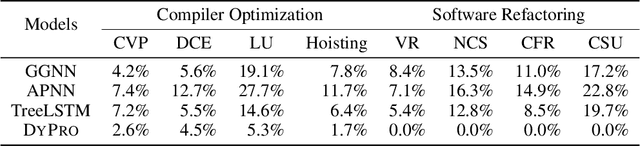
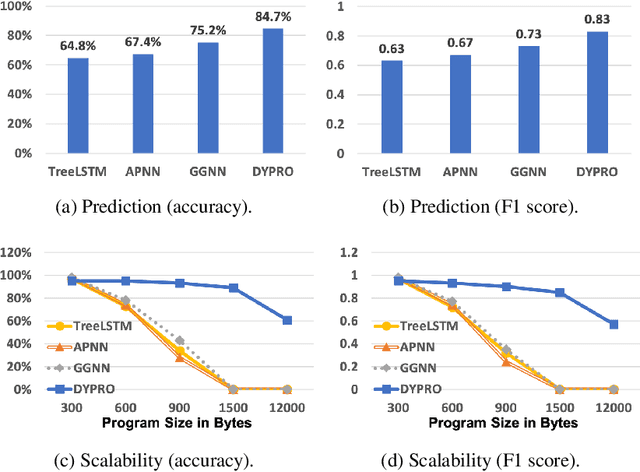

Neural program embedding can be helpful in analyzing large software, a task that is challenging for traditional logic-based program analyses due to their limited scalability. A key focus of recent machine-learning advances in this area is on modeling program semantics instead of just syntax. Unfortunately evaluating such advances is not obvious, as program semantics does not lend itself to straightforward metrics. In this paper, we introduce a benchmarking framework called COSET for standardizing the evaluation of neural program embeddings. COSET consists of a diverse dataset of programs in source-code format, labeled by human experts according to a number of program properties of interest. A point of novelty is a suite of program transformations included in COSET. These transformations when applied to the base dataset can simulate natural changes to program code due to optimization and refactoring and can serve as a "debugging" tool for classification mistakes. We conducted a pilot study on four prominent models: TreeLSTM, gated graph neural network (GGNN), AST-Path neural network (APNN), and DYPRO. We found that COSET is useful in identifying the strengths and limitations of each model and in pinpointing specific syntactic and semantic characteristics of programs that pose challenges.