 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHSER: A Dataset and Case Study on Generative Speech Error Correction for Child ASR
Paper and Code
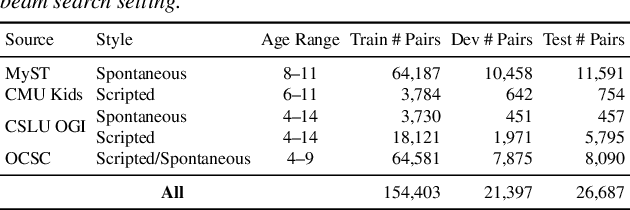
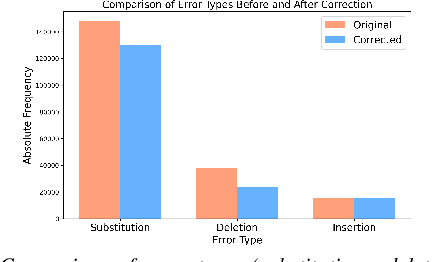
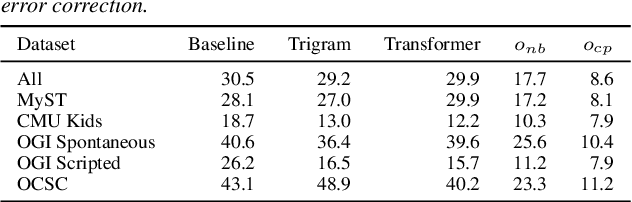
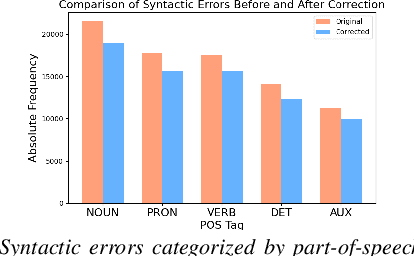
Automatic Speech Recognition (ASR) systems struggle with child speech due to its distinct acoustic and linguistic variability and limited availability of child speech datasets, leading to high transcription error rates. While ASR error correction (AEC) methods have improved adult speech transcription, their effectiveness on child speech remains largely unexplored. To address this, we introduce CHSER, a Generative Speech Error Correction (GenSEC) dataset for child speech, comprising 200K hypothesis-transcription pairs spanning diverse age groups and speaking styles. Results demonstrate that fine-tuning on the CHSER dataset achieves up to a 28.5% relative WER reduction in a zero-shot setting and a 13.3% reduction when applied to fine-tuned ASR systems. Additionally, our error analysis reveals that while GenSEC improves substitution and deletion errors, it struggles with insertions and child-specific disfluencies. These findings highlight the potential of GenSEC for improving child ASR.