 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic extraction of road intersection points from USGS historical map series using deep convolutional neural networks
Paper and Code
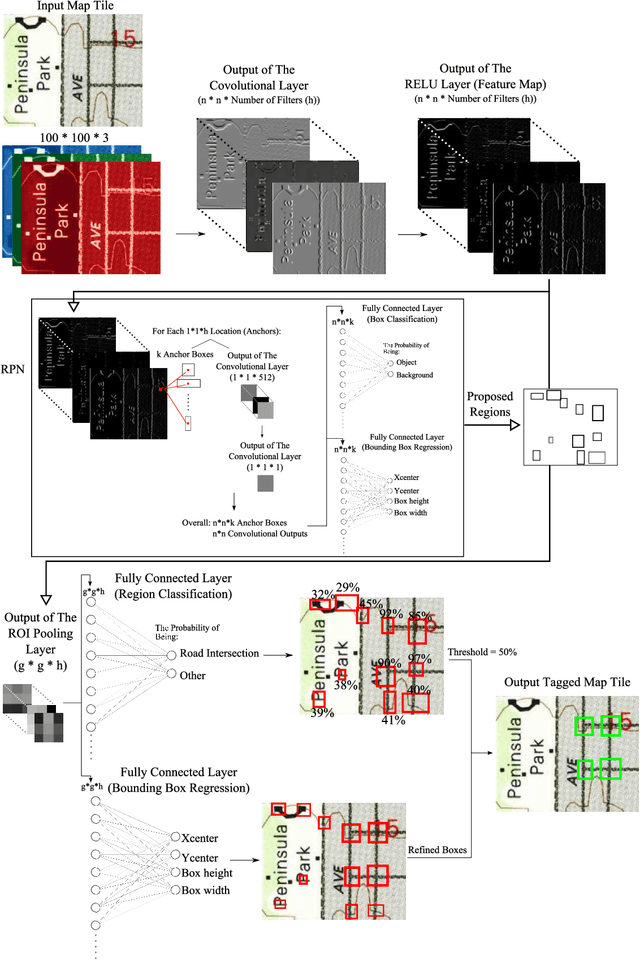

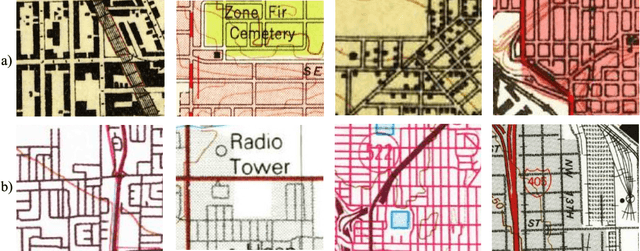
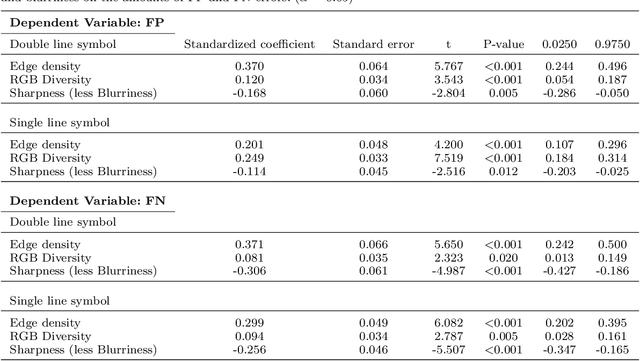
Road intersections data have been used across different geospatial applications and analysis. The road network datasets dating from pre-GIS years are only available in the form of historical printed maps. Before they can be analyzed by a GIS software, they need to be scanned and transformed into the usable vector-based format. Due to the great bulk of scanned historical maps, automated methods of transforming them into digital datasets need to be employed. Frequently, this process is based on computer vision algorithms. However, low conversion accuracy for low quality and visually complex maps and setting optimal parameters are the two challenges of using those algorithms. In this paper, we employed the standard paradigm of using deep convolutional neural network for object detection task named region-based CNN for automatically identifying road intersections in scanned historical USGS maps of several U.S. cities. We have found that the algorithm showed higher conversion accuracy for the double line cartographic representations of the road maps than the single line ones. Also, compared to the majority of traditional computer vision algorithms RCNN provides more accurate extraction. Finally, the results show that the amount of errors in the detection outputs is sensitive to complexity and blurriness of the maps as well as the number of distinct RGB combinations within them.