Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Abstraction in MAXQ Hierarchical Reinforcement Learning
Paper and Code
May 21, 1999
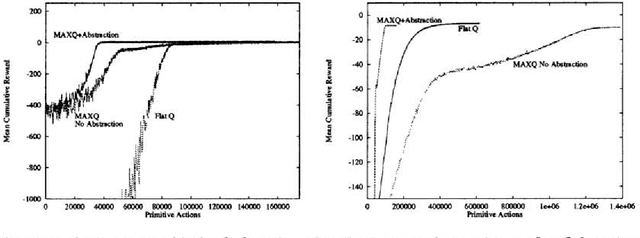
Many researchers have explored methods for hierarchical reinforcement learning (RL) with temporal abstractions, in which abstract actions are defined that can perform many primitive actions before terminating. However, little is known about learning with state abstractions, in which aspects of the state space are ignored. In previous work, we developed the MAXQ method for hierarchical RL. In this paper, we define five conditions under which state abstraction can be combined with the MAXQ value function decomposition. We prove that the MAXQ-Q learning algorithm converges under these conditions and show experimentally that state abstraction is important for the successful application of MAXQ-Q learning.
* 7 pages, 2 figures
View paper on