 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Manual Annotation Cost In Supervised Training From Corpora
Paper and Code
Jun 24, 1996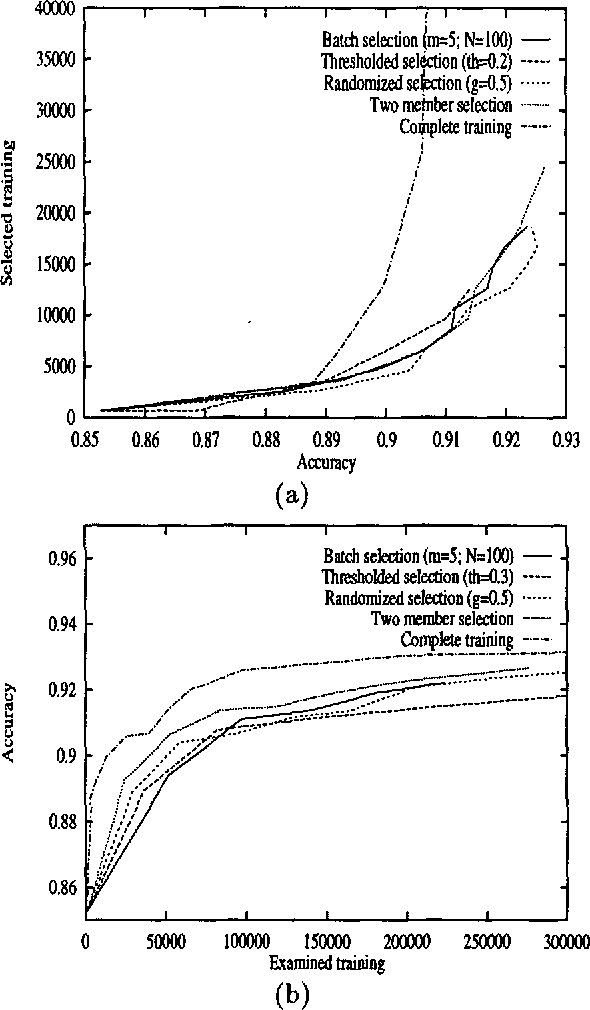
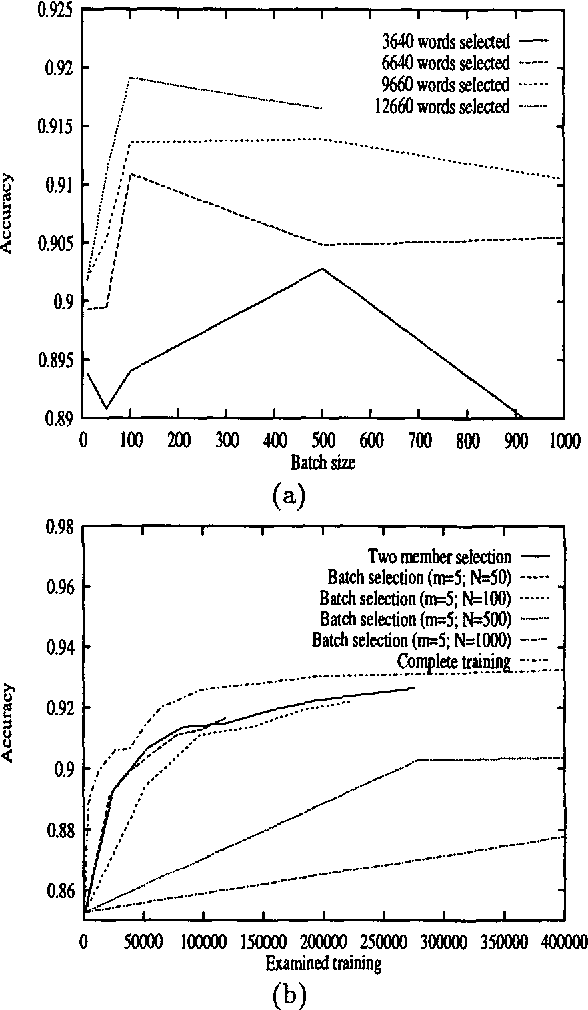
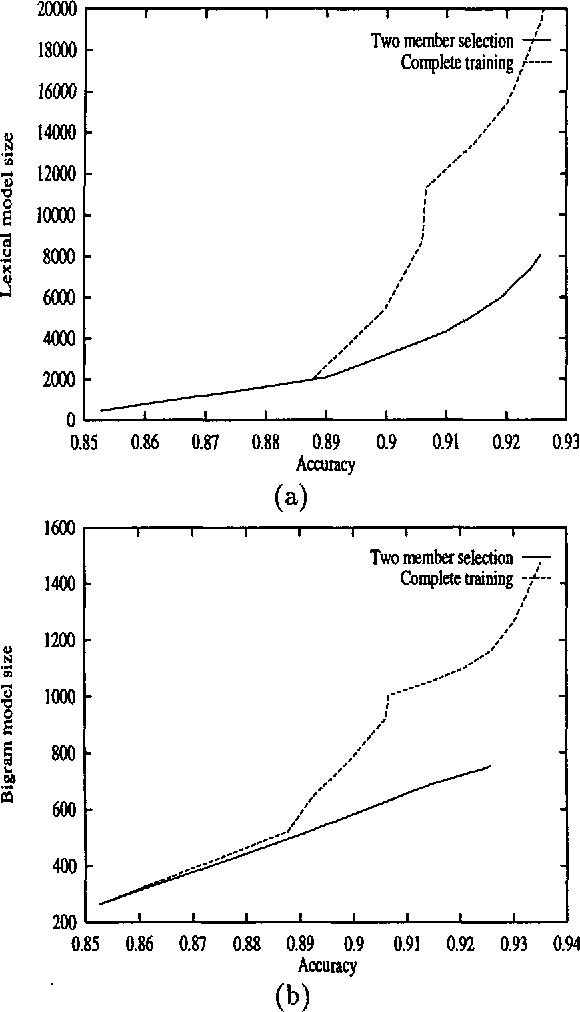
Corpus-based methods for natural language processing often use supervised training, requiring expensive manual annotation of training corpora. This paper investigates methods for reducing annotation cost by {\it sample selection}. In this approach, during training the learning program examines many unlabeled examples and selects for labeling (annotation) only those that are most informative at each stage. This avoids redundantly annotating examples that contribute little new information. This paper extends our previous work on {\it committee-based sample selection} for probabilistic classifiers. We describe a family of methods for committee-based sample selection, and report experimental results for the task of stochastic part-of-speech tagging. We find that all variants achieve a significant reduction in annotation cost, though their computational efficiency differs. In particular, the simplest method, which has no parameters to tune, gives excellent results. We also show that sample selection yields a significant reduction in the size of the model used by the tagger.