Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Statistical Parser Based on Bigram Lexical Dependencies
Paper and Code
May 06, 1996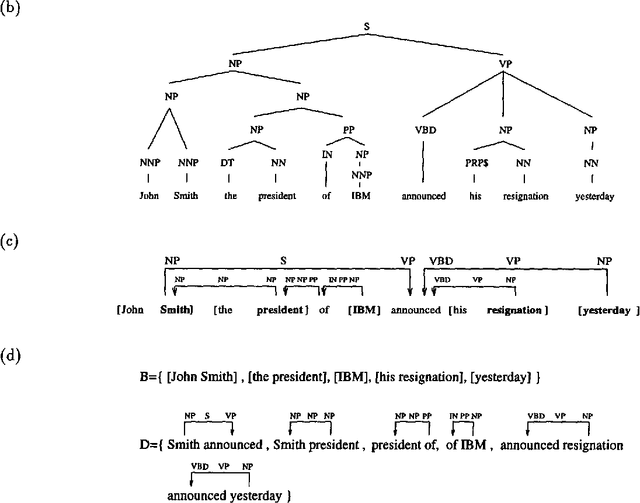
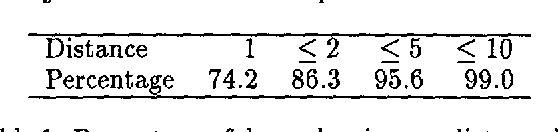
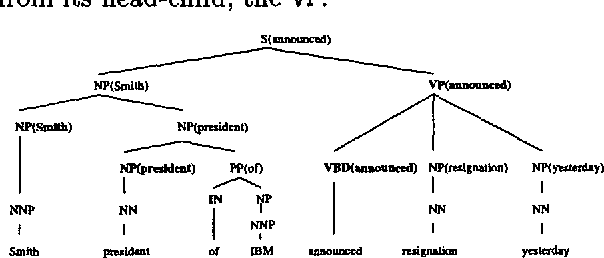
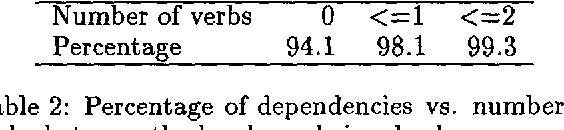
This paper describes a new statistical parser which is based on probabilities of dependencies between head-words in the parse tree. Standard bigram probability estimation techniques are extended to calculate probabilities of dependencies between pairs of words. Tests using Wall Street Journal data show that the method performs at least as well as SPATTER (Magerman 95, Jelinek et al 94), which has the best published results for a statistical parser on this task. The simplicity of the approach means the model trains on 40,000 sentences in under 15 minutes. With a beam search strategy parsing speed can be improved to over 200 sentences a minute with negligible loss in accuracy.
* 8 pages, to appear in Proceedings of ACL 96. Uuencoded gz-compressed
postscript file created by csh script uufiles
View paper on