 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Than Whitespace: Information Retrieval for Languages without Custom Tokenizers
Paper and Code
Oct 11, 2022
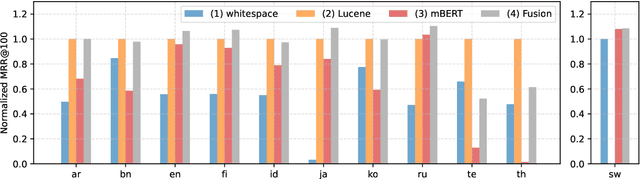
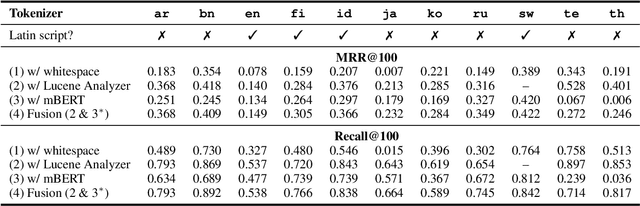
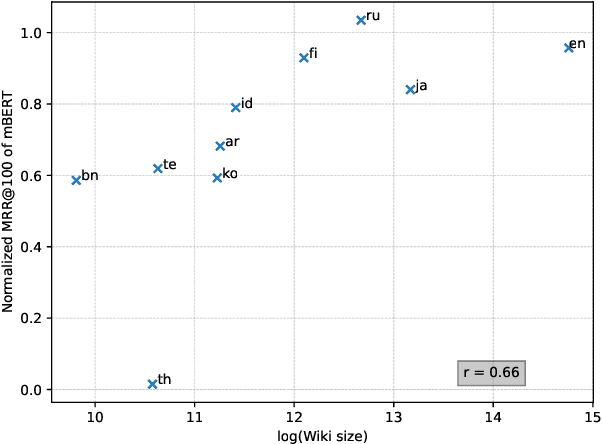
Tokenization is a crucial step in information retrieval, especially for lexical matching algorithms, where the quality of indexable tokens directly impacts the effectiveness of a retrieval system. Since different languages have unique properties, the design of the tokenization algorithm is usually language-specific and requires at least some lingustic knowledge. However, only a handful of the 7000+ languages on the planet benefit from specialized, custom-built tokenization algorithms, while the other languages are stuck with a "default" whitespace tokenizer, which cannot capture the intricacies of different languages. To address this challenge, we propose a different approach to tokenization for lexical matching retrieval algorithms (e.g., BM25): using the WordPiece tokenizer, which can be built automatically from unsupervised data. We test the approach on 11 typologically diverse languages in the MrTyDi collection: results show that the mBERT tokenizer provides strong relevance signals for retrieval "out of the box", outperforming whitespace tokenization on most languages. In many cases, our approach also improves retrieval effectiveness when combined with existing custom-built tokenizers.