 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide Attention Is The Way Forward For Transformers
Paper and Code
Oct 02, 2022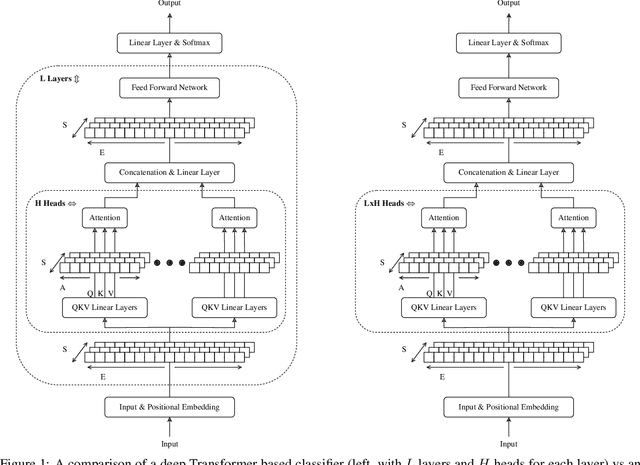

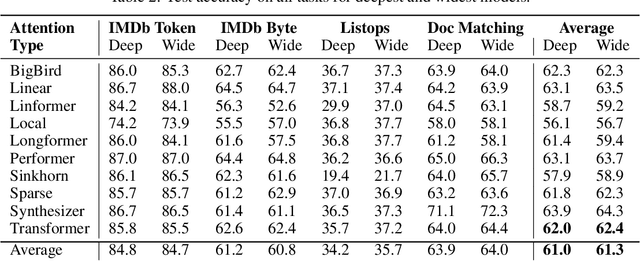
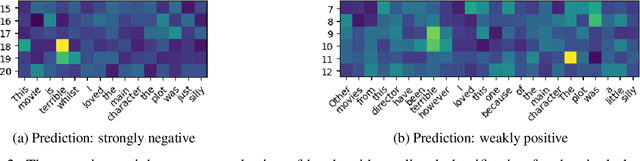
The Transformer is an extremely powerful and prominent deep learning architecture. In this work, we challenge the commonly held belief in deep learning that going deeper is better, and show an alternative design approach that is building wider attention Transformers. We demonstrate that wide single layer Transformer models can compete with or outperform deeper ones in a variety of Natural Language Processing (NLP) tasks when both are trained from scratch. The impact of changing the model aspect ratio on Transformers is then studied systematically. This ratio balances the number of layers and the number of attention heads per layer while keeping the total number of attention heads and all other hyperparameters constant. On average, across 4 NLP tasks and 10 attention types, single layer wide models perform 0.3% better than their deep counterparts. We show an in-depth evaluation and demonstrate how wide models require a far smaller memory footprint and can run faster on commodity hardware, in addition, these wider models are also more interpretable. For example, a single layer Transformer on the IMDb byte level text classification has 3.1x faster inference latency on a CPU than its equally accurate deeper counterpart, and is half the size. Our results suggest that the critical direction for building better Transformers for NLP is their width, and that their depth is less relevant.