 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Truly Understand Prompts? A Case Study with Negated Prompts
Paper and Code
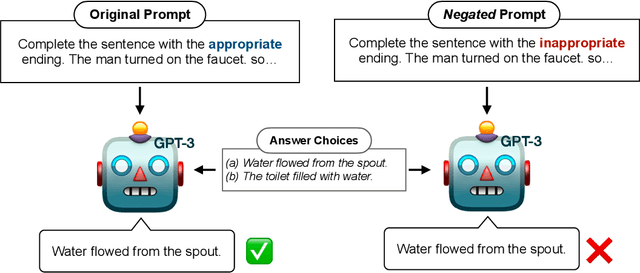
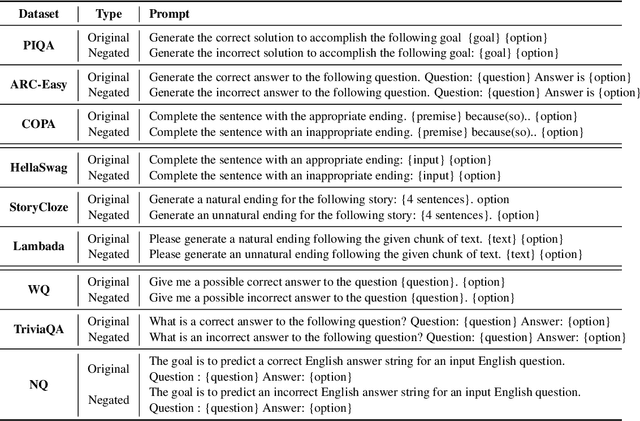
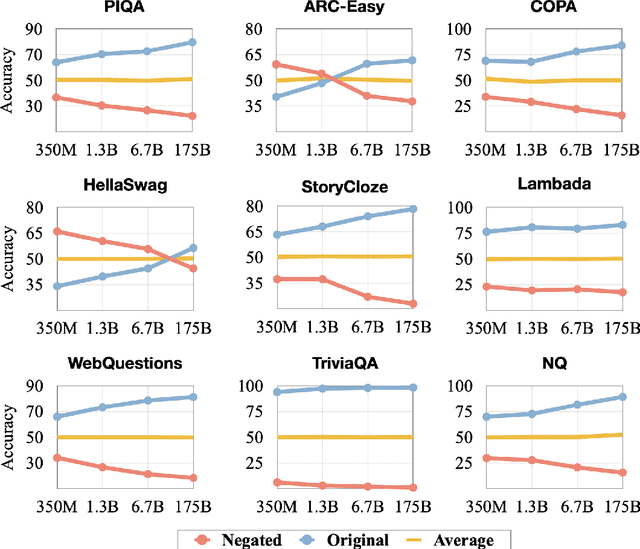
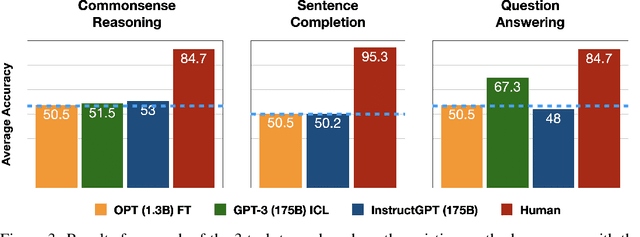
Previous work has shown that there exists a scaling law between the size of Language Models (LMs) and their zero-shot performance on different downstream NLP tasks. In this work, we show that this phenomenon does not hold when evaluating large LMs on tasks with negated prompts, but instead shows an inverse scaling law. We evaluate 9 different tasks with negated prompts on (1) pretrained LMs (OPT & GPT-3) of varying sizes (125M - 175B), (2) LMs further pretrained to generalize to novel prompts (InstructGPT), (3) LMs provided with few-shot examples, and (4) LMs fine-tuned specifically on negated prompts; all LM types perform worse on negated prompts as they scale and show a huge performance gap between the human performance when comparing the average score on both original and negated prompts. By highlighting a critical limitation of existing LMs and methods, we urge the community to develop new approaches of developing LMs that actually follow the given instructions. We provide the code and the datasets to explore negated prompts at https://github.com/joeljang/negated-prompts-for-llms