 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom initialisations performing above chance and how to find them
Paper and Code
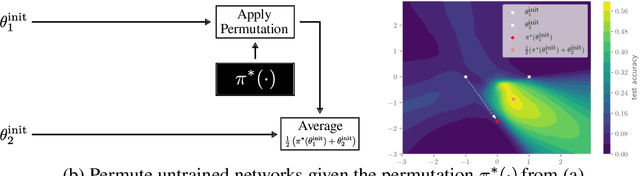
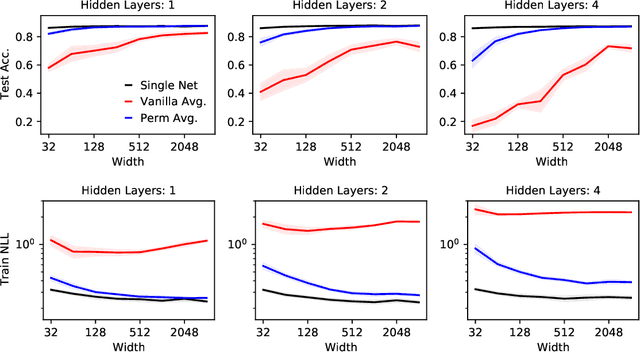
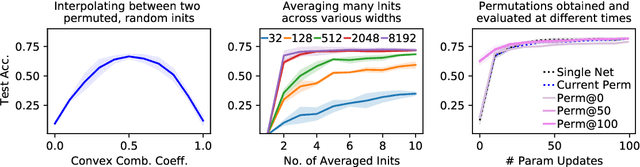
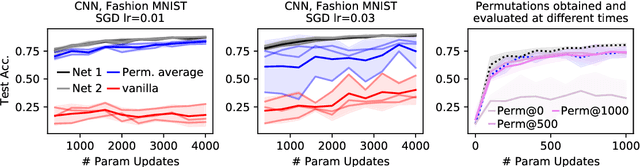
Neural networks trained with stochastic gradient descent (SGD) starting from different random initialisations typically find functionally very similar solutions, raising the question of whether there are meaningful differences between different SGD solutions. Entezari et al. recently conjectured that despite different initialisations, the solutions found by SGD lie in the same loss valley after taking into account the permutation invariance of neural networks. Concretely, they hypothesise that any two solutions found by SGD can be permuted such that the linear interpolation between their parameters forms a path without significant increases in loss. Here, we use a simple but powerful algorithm to find such permutations that allows us to obtain direct empirical evidence that the hypothesis is true in fully connected networks. Strikingly, we find that two networks already live in the same loss valley at the time of initialisation and averaging their random, but suitably permuted initialisation performs significantly above chance. In contrast, for convolutional architectures, our evidence suggests that the hypothesis does not hold. Especially in a large learning rate regime, SGD seems to discover diverse modes.